Transformer에서의 Feed-Forward Network
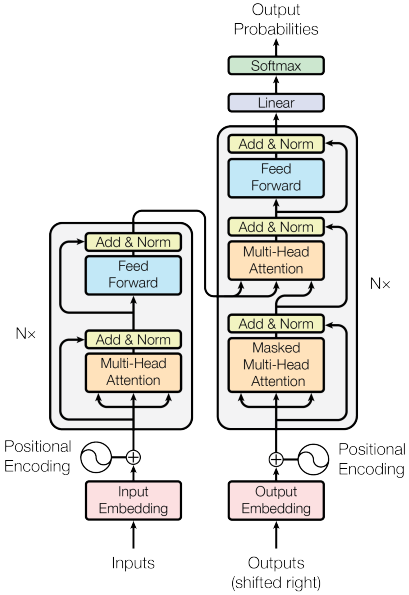
Transformer의 Encoder와 Decoder 모듈 내에 위치한 Feed-Forward Network(FFN)은 attention mechanism이 처리하는 데이터를 정제하는데 중요한 역할을 한다. 먼저 Multi-head Attention Sublayer와 Post-Layer Normalization(Post-LN)을 거친 output은 $d_{model}=512$의 차원을 유지하며, FFN에 입력된다. 이 FFN은 시퀀스의 각 position에서 독립적으로 데이터를 순차적으로 처리하는 데 중요한 역할을 수행한다.
Transformer의 인코더와 디코더 내부의 FFN은 fully connected network이면서 동시에 position-wise network에 해당한다. 이러한 설계는 입력 시퀀스의 각 위치가 개별적으로 처리되지만, 동일한 방식으로 처리되므로 입력 데이터의 positional integrity를 유지하는데 매우 중요하다.
FFN의 주요 특성
- Fully-Connected Layer
- 2개의 fully-connected linear layer로 구성되어 input data를 처리
- 첫 번째 layer는 input dimension $d_{model}=512$를 더 큰 차원인 $dff=2048$로 확장
- 두 번째 layer는 이를 다시 $d_{model}=512$ 차원으로 돌려놓음
- Activation Function
- 두 linear layer 사이에
Rectified Linear Unit(ReLU)적용- $ReLU(x)=max(0,x)$
- 모델에 비선형성을 도입하여 더 복잡한 패턴을 학습할 수 있도록 지원하는 역할
- 두 linear layer 사이에
- Position-wise Processing
- 입력 데이터의 순차적 특성에도 불구하고 각 position(즉, 문장에서 각 단어의 representation)은 동일한 FFN으로 독립적으로 처리
- 모든 position에 동일한 변환을 적용하는 것과 유사
- 입력 시퀀스의 다양한 부분에서 feature를 추출할때의
uniformity를 보장
FFN의 수학적 표현
$FFN(x)=ReLU(xW_1+b_1)W_2+b_2$
- $W_1$과 $W_2$는 각각 첫 번째 layer와 두 번째 layer의 weight matrix
- $b_1$과 $b_2$는 각각 첫 번째 layer와 두 번째 layer의 bias
- 첫번째 선형 변환 이후
ReLUactivation이 element-wise하게 적용
Reference
Transformer에서의 Feed-Forward Network
Transformer의 Encoder와 Decoder 모듈 내에 위치한 Feed-Forward Network(FFN)은 attention mechanism이 처리하는 데이터를 정제하는데 중요한 역할을 한다. 먼저 Multi-head Attention Sublayer와 Post-Layer Normalization(Post-LN)을 거친 output은 dmodel=512의 차원을 유지하며, FFN에 입력된다. 이 FFN은 시퀀스의 각 position에서 독립적으로 데이터를 순차적으로 처리하는 데 중요한 역할을 수행한다.
Transformer의 인코더와 디코더 내부의 FFN은 fully connected network이면서 동시에 position-wise network에 해당한다. 이러한 설계는 입력 시퀀스의 각 위치가 개별적으로 처리되지만, 동일한 방식으로 처리되므로 입력 데이터의 positional integrity를 유지하는데 매우 중요하다.
FFN의 주요 특성
- Fully-Connected Layer
- 2개의 fully-connected linear layer로 구성되어 input data를 처리
- 첫 번째 layer는 input dimension dmodel=512를 더 큰 차원인 dff=2048로 확장
- 두 번째 layer는 이를 다시 dmodel=512 차원으로 돌려놓음
- Activation Function
- 두 linear layer 사이에
Rectified Linear Unit(ReLU)적용- ReLU(x)=max(0,x)
- 모델에 비선형성을 도입하여 더 복잡한 패턴을 학습할 수 있도록 지원하는 역할
- 두 linear layer 사이에
- Position-wise Processing
- 입력 데이터의 순차적 특성에도 불구하고 각 position(즉, 문장에서 각 단어의 representation)은 동일한 FFN으로 독립적으로 처리
- 모든 position에 동일한 변환을 적용하는 것과 유사
- 입력 시퀀스의 다양한 부분에서 feature를 추출할때의
uniformity를 보장
FFN의 수학적 표현
FFN(x)=ReLU(xW1+b1)W2+b2
- W1과 W2는 각각 첫 번째 layer와 두 번째 layer의 weight matrix
- b1과 b2는 각각 첫 번째 layer와 두 번째 layer의 bias
- 첫번째 선형 변환 이후
ReLUactivation이 element-wise하게 적용