본 포스팅은 다음 글을 기반으로 작성하였습니다. 매우 좋은 자료 공유해주셔서 감사합니다.
Jupyter Notebook Viewer
2. Large-scale의 시대에 우리는 무엇을 준비해야 할까?¶ Large-scale transformer 모델은 기존과 아키텍처는 거의 동일한데, 모델의 모델과 데이터 사이즈를 엄청나게 키운 것입니다. 그래서 몇몇 사람들
nbviewer.org
Why Large Scale?
그동안 많은 연구에서 언어 모델의 아키텍처의 변화가 생각보다 큰 차이를 가져오진 못한다고 말한다. 물론, 언어 모델의 성능이 어느 정도 향상된 것은 사실이지만 이것이 드라마틱한 성능 개선을 의미하진 않는다. 결국 모델의 성능에 가장 큰 영향을 끼치는 것은 데이터와 모델의 크기이다. 둘 중 굳이 더 중요한 것을 따지자면, 모델의 크기가 성능에 가장 큰 영향을 끼치고 그 다음으로 데이터의 크기가 중요하다고 한다.
`Large-scale Transformer` 모델은 기존 모델과 아키텍처는 거의 동일한데 모델의 크기와 데이터 사이즈를 엄청나게 키운 모델을 의미한다. 이러한 Large-scale 모델들을 잘 다루기 위해선 다음과 같은 엔지니어링들이 동반되어야 한다.
- TensorRT(GPU 기반 배포기술)
- Megatron LM(모델 병렬처리)
- DeepSpeed(메모리 최적화)
- Fused Kernel(고성능 CUDA 연산)
- Big Query(빅데이터 처리)
Distributed Programming
`분산처리`란, 커다란 리소스를 여러 대의 컴퓨터 혹은 여러 대의 장비에 분산시켜서 처리하는 것을 의미한다. Large-scale 모델들은 크기가 크기 때문에 여러 대의 GPU에 쪼개서 모델을 올려야하며, 쪼개진 각 모델의 조각들끼리 네트워크로 통신하면서 값을 주고받아야 한다.
Multi-processing with Pytorch
Multi-processing 통신에 사용되는 기본 용어는 다음과 같다.
- `Node` : 컴퓨터 -> 노드 3대는 곧 컴퓨터 3대를 의미
- `Global Rank` : GPU의 ID(본래는 프로세스 우선 순위)
- `Local Rank` : 노드 내의 GPU ID(본래는 한 노드 내에서의 프로세스 우선 순위)
- `World Size` : 프로세스의 개수

Pytorch로 구현된 Multi-process 애플리케이션을 실행시키는 방법은 크게 두 가지가 있다.
- 사용자의 코드가 메인 프로세스가 되어 특정 함수를 서브프로세스로 분기
- Pytorch 런처가 메인 프로세스가 되어 사용자 코드 전체를 서브프로세스로 분기
사용자의 코드가 메인 프로세스가 되어 특정 함수를 서브프로세스로 분기
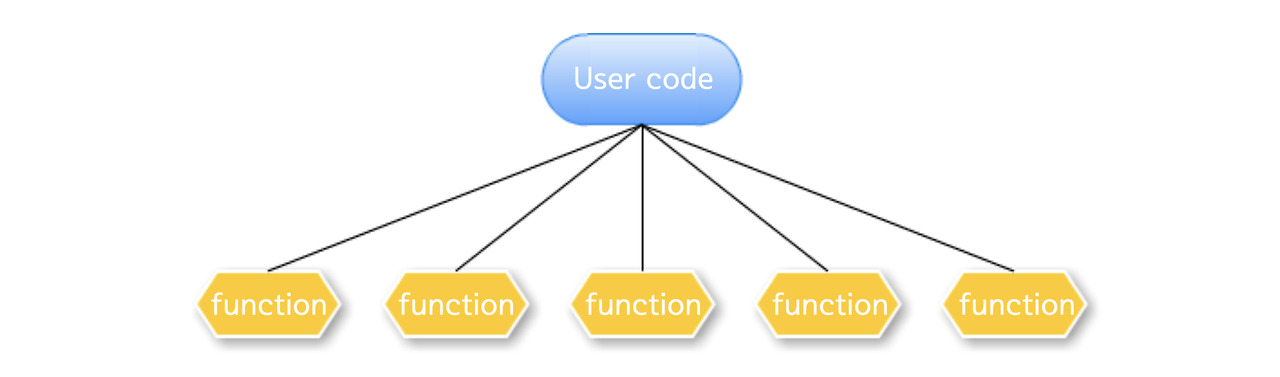
이 방식은 일반적으로 `Spawn`과 `Fork` 두가지 방식이 가능하다. `Spawn`은 메인 프로세스의 자원을 물려주지 않고, 필요한만큼의 자원만 서브프로세스에게 새로 할당하여 속도가 느리지만 안전한 방식에 해당한다. `Fork`는 메인 프로세스의 모든 자원을 서브프로세스와 공유하고 프로세스를 시작하여 속도가 빠르지만 위험한 방식에 해당한다. 추가적으로 `Forkserver` 방식도 있지만, 자주 사용되지 않는다.
pytorch를 통해 멀티 프로세싱을 구현하는 코드는 다음과 같다.
import torch.multiprocessing as mp
def fn(rank, param1, param2):
print(f"{param2} {param2} - rank: {rank}")
processes = []
mp.set_start_method("spawn") # 시작 방법 설정
for rank in range(4):
process = mp.Process(target=fn, args=(rank, "A0", "B1"))
process.damon = False
process.start() # 프로세스 시작
processes.append(process) # 서브프로세스 시작
for process in processes:
process.join() # 서브프로세스 join(= 완료되면 종료)
이는 `torch.multiprocessing.spawn` 함수를 이용하면 매우 쉽게 진행할 수 있다.
import torch.multiprocessing as mp
def fn(rank, param1, param2):
print(f"{param1} {param2} - rank: {rank}")
mp.spawn(fn = fn, # 각 프로세스에서 실행할 함수
args=("A0", "B1"), # 함수 fn에 전달할 인자
nprocs=4, # 만들 프로세스의 개수
join=True, # 프로세스의 joint 여부(default: True)
daemon=False, # 메인 프로세스 종료시 함께 종료되는 데몬 사용 여부(default: False)
start_method='spawn' # spawn, fork, forkswerver 중 하나
)Pytorch 런처가 메인 프로세스가 되어 사용자 코드 전체를 서브프로세스로 분기
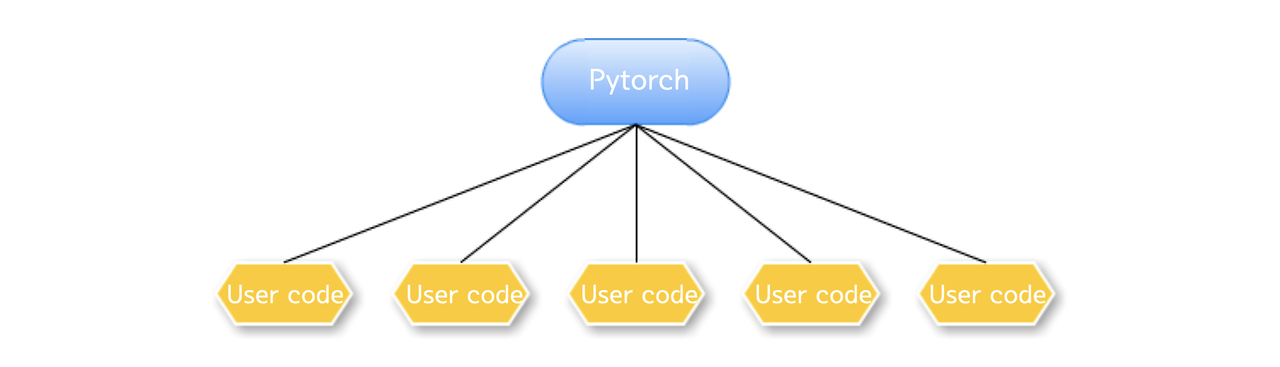
이 방식은 torch에 내장된 멀티프로세싱 런처가 사용자 코드 전체를 서브프로세스로 실행시켜주는 매우 편리한 방식에 해당한다. 다음과 같은 명령어를 통해 사용할 수 있다.
python -m torch.distributed.launch --nproce_per_node=n 000.pyDistributed Programming with Pytorch
Message Passing
`메시지 패싱(Message Passing)`이란, 동일한 주소 공간을 공유하지 않는 여러 프로세스들이 데이터를 주고 받을 수 있도록 메시지라는 간접 정보를 주고 받는 것을 말한다. Large-scale 모델 개발 시에 사용되는 분산 통신에는 대부분 Message Passing 기법이 사용된다.
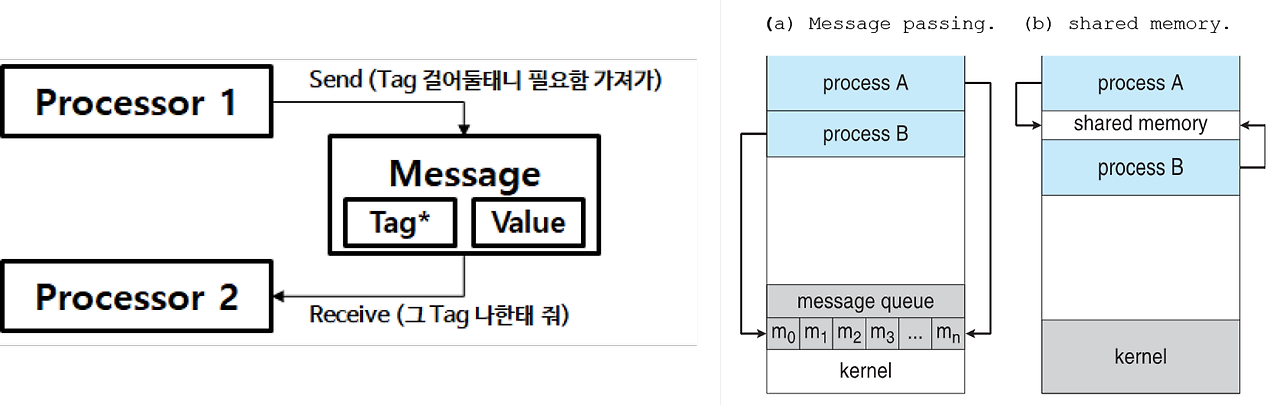
MPI, NCCL, GLOO
`MPI(Message Passing Interface)`는 프로세스 간의 Message Passing에 사용되는 다양한 연산(Broadcast, Reduce, Scatter, Gather 등)이 정의되어 있는 표준 인터페이스로, 대표적으로 `OpenMPI`라는 오픈소스가 존재한다. 그러나 OpenMPI를 써야할 특별한 이유가 있는 것이 아니라면 `NCCL(NVIDIA Collective COmmunication Library)` 혹은 `GLOO(Facebook's Collective Communication Library)`를 사용하게 된다. 편하게 생각해서 GPU에서 사용 시에는 NCCL, CPU에서 사용 시에는 GLOO를 사용하면 된다.
torch.distributed 패키지
pytorch에서 `GLOO`, `NCCL`, `OpenMPI`를 모두 wrapping하는 패키지로 `torch.distributed`가 있다. 실제 활용 시 대부분의 경우 이러한 하이레벨 패키지를 사용하여 프로그래밍하게 된다.
Process Group
많은 프로세스를 관리하는 것은 어려운 일이기 때문에 프로세스 그룹을 만들어 관리한다. `init_process_group`을 호출하면 전체 프로세스가 속한 default_pg(process group)가 생성된다. 프로세스 그룹을 초기화하는 `init_process_group`은 반드시 서브프로세스에서 실행되어야 하며, 추가적으로 원하는 프로세스만을 통해 새로운 프로세스 그룹을 구성하고 싶은 경우 `new_group`을 호출하면 된다.
import torch.multiprocessing as mp
import torch.distributed as dist
import os
# 서브프로세스에서 동시에 실행되는 영역
def fn(rank, world_size):
dist.init_process_group(backend='nccl', rank=rank, world_size=world_size) # 프로세스 초기화(nccl, mpi, gloo 사용 가능)
group = dist.new_group([_ for _ in range(world_size)])
# 통신에 필요한 주소 설정
os.envrion["MASTER_ADDR"] = "localhost" # 통신할 주소 - 보통 localhost 사용
os.environ["MASTER_PORT"] = "29500" # 통신할 포트 - 임의의 값 설정 가능
os.environ["WORLD_SIZE"] = "4"
mp.spawn(
fn=fn,
args=(4,) # world_size
nprocs=4,
join=True,
daemon=False,
start_method='spawn')
P2P Communication(Point to point)
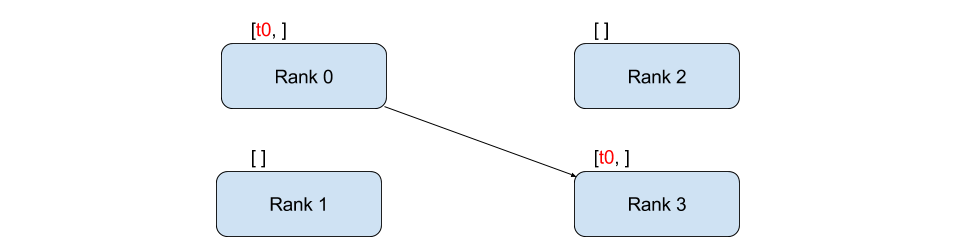
`P2P(Point to point, 점 대 점) 통신`은 특정 프로세스에서 다른 프로세스 데이터를 전송하는 통신에 해당한다. 이는 `torch.distributed` 패키지에서 `send`, `recv` 함수를 활용하여 통신할 수 있다. 여기서 주의할 점은, 해당 함수들이 동기적으로 통신한다는 것이다. `비동기 통신(non-blocking)`에는 `isend`, `irecv`를 사용한다. 비동기적으로 작동하는 경우 `wait()` 메서드를 통해 다른 프로세스의 통신이 끝날때까지 기다린 후 접근해야한다.
import torch
import torch.distributed as dist
dist.init_process_group("gloo")
if dist.get_rank() == 0:
tensor = torch.randn(2,2)
dist.send(tensor, dst=1)
elif dist.get_rank() == 1:
tensor = torch.zeros(2,2)
print(f"rank 1 before: {tensor}\n")
dist.recv(tensor, src=0)
print(f"rank 1 after: {tensor}\n")
else:
raise RuntimeError("wrong rank")
Collective Communication
`집합통신(Collective Communication)`은 여러 프로세스가 참여하는 통신을 의미한다. 기본적으로 다음과 같은 4개의 연산 `broadcast`, `scatter`, `gather`, `reduce`가 기본 세트에 해당한다. 여기에 추가적으로 `all-reduce`, `all-gather`, `reduce-scatter` 등의 복합 연산과 `barrier`에 해당하는 동기화 연산이 있다. 추가로 이러한 연산들을 비동기 모드로 수행하려면 `async_op` 파라미터의 값을 `True`로 설정하면 된다.
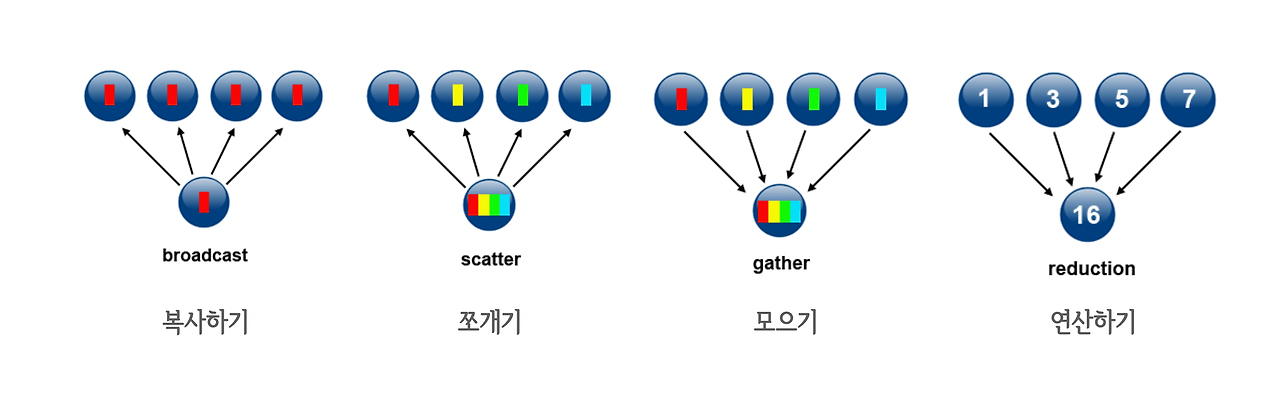
Broadcast
`Broadcast`는 특정 프로세스에 있는 데이터를 그룹 내의 모든 프로세스에 복사하는 연산이다. `send`나 `recv` 등의 P2P 연산이 지원되지 않을때 `broadcast`를 P2P 통신 연산으로 사용하기도 한다. src=0, dst=1일 때 `new_group([0,1])` 그룹을 만들고 `broadcast` 연산을 수행하면 0 -> 1 P2P와 동일하다.
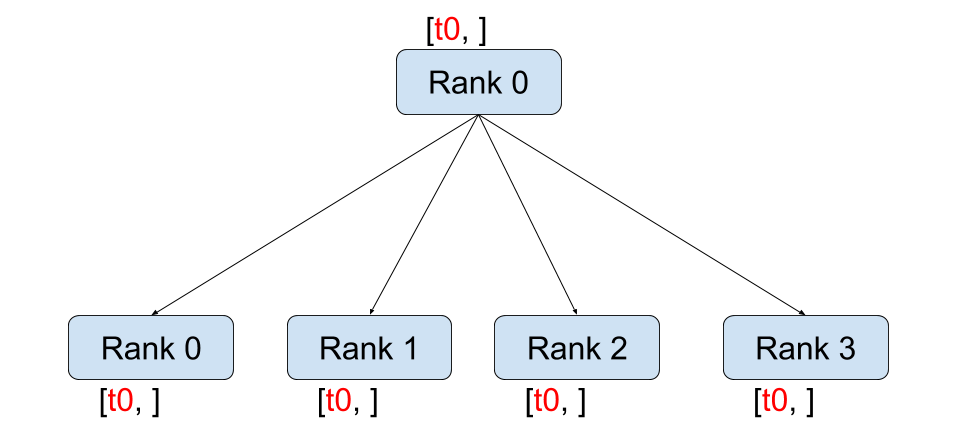
import torch
import torch.distributed as dist
dist.init_process_group("nccl")
rank = dist.get_rank()
torch.cuda.set_device(rank)
if rank == 0:
tensor = torch.randn(2,2).to(torch.cuda.current_device())
else:
tensor = torch.zeros(2,2).to(torch.cuda.current_device())
dist.broadcast(tensor, src=0)
Reduce
`Reduce`는 각 프로세스가 가진 데이터로 특정 연산을 수행해서 출력을 하나의 디바이스로 모아주는 연산에 해당한다. 연산에서 사용가능한 것으로는 `sum`, `max`, `min` 등이 있다.
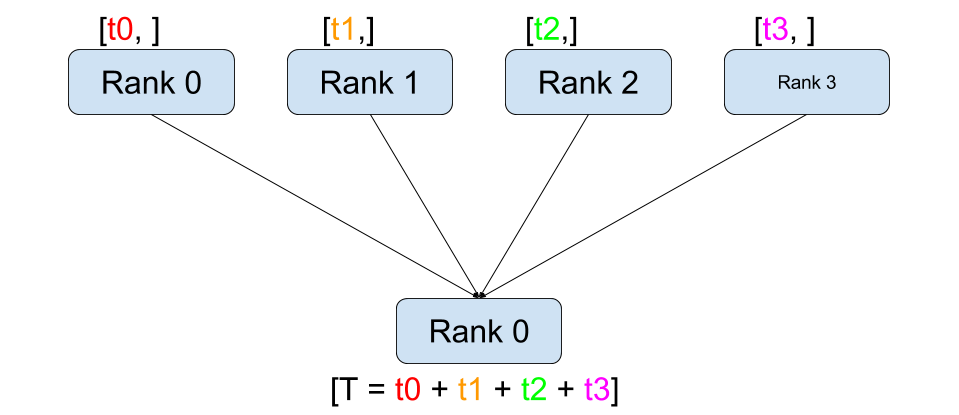
import torch
import torch.distributed as dist
dist.init_process_group("nccl")
rank = dist.get_rank()
torch.cuda.set_device(rank)
tensor = torch.ones(2, 2).to(torch.cuda.current_device()) * rank
# rank==0 => [[0, 0], [0, 0]]
# rank==1 => [[1, 1], [1, 1]]
# rank==2 => [[2, 2], [2, 2]]
# rank==3 => [[3, 3], [3, 3]]
dist.reduce(tensor, op=torch.distributed.ReduceOp.SUM, dst=0)
if rank == 0:
print(tensor)
Scatter
`Scatter`는 여러 개의 element를 쪼개서 각 디바이스에 뿌려주는 연산이다.
import torch
import torch.distributed as dist
dist.init_process_group("gloo")
rank = dist.get_rank()
torch.cuda.set_device(rank)
output = torch.zeros(1)
print(f"before rank {rank}: {output}\n")
if rank == 0:
inputs = torch.tensor([10.0, 20.0, 30.0, 40.0])
inputs = torch.split(inputs, dim=0, split_size_or_sections=1)
# (tensor([10]), tensor([20]), tensor([30]), tensor([40]))
dist.scatter(output, scatter_list=list(inputs), src=0)
else:
dist.scatter(output, src=0)
print(f"after rank {rank}: {output}\n")
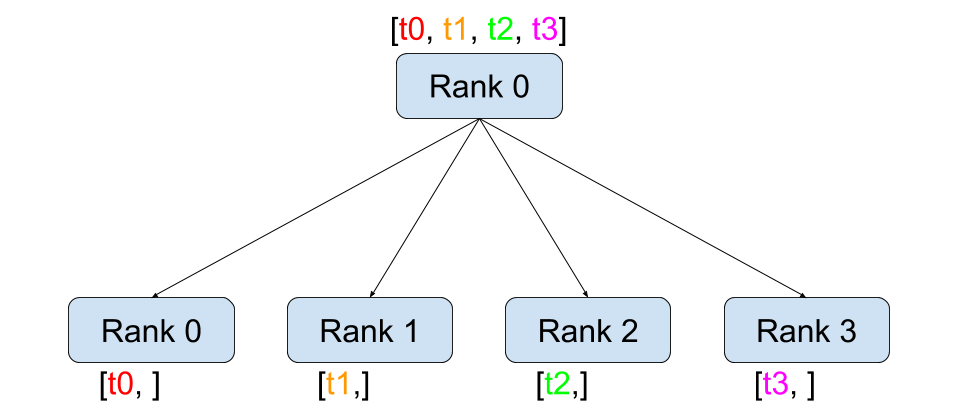
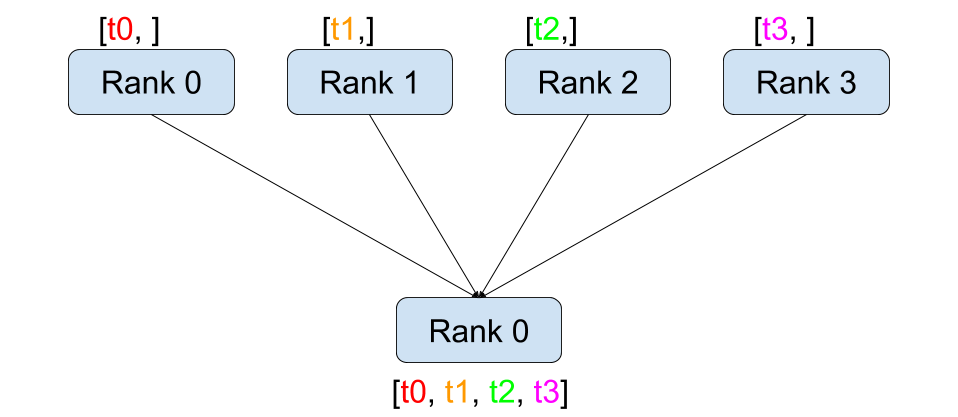
Gather
`Gather` 연산은 여러 디바이스에 존재하는 텐서를 하나로 모아주는 연산에 해당한다.
import torch
import torch.distributed as dist
dist.init_process_group("gloo")
rank = dist.get_rank()
torch.cuda.set_device(rank)
input = torch.ones(1) * rank
# rank==0 => [0]
# rank==1 => [1]
# rank==2 => [2]
# rank==3 => [3]
if rank == 0:
outputs_list = [torch.zeros(1), torch.zeros(1), torch.zeros(1), torch.zeros(1)]
dist.gather(input, gather_list=outputs_list, dst=0)
print(outputs_list)
else:
dist.gather(input, dst=0)
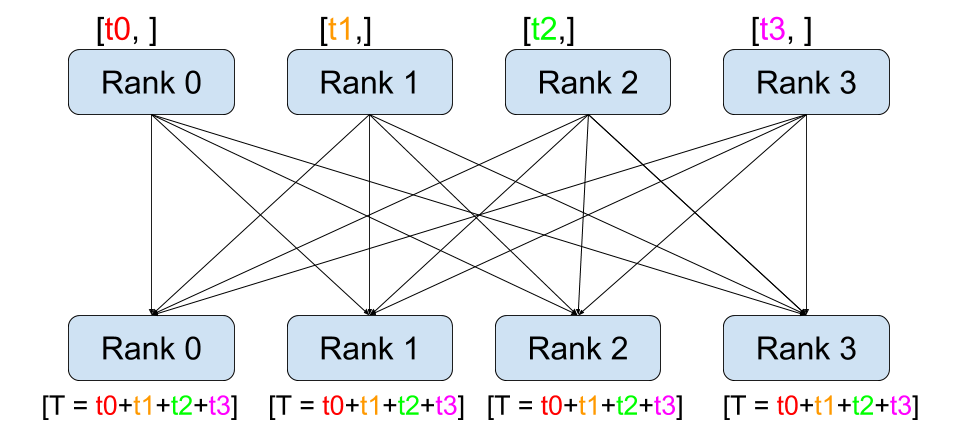
All-reduce
이름 앞에 All이 붙은 연산들은 해당 연산을 수행한 뒤 결과를 모든 디바이스로 broadcast하는 연산에 한다. `All-reduce`의 경우 `reduce`를 수행한 뒤, 계산된 결과를 모든 디바이스로 복사한다.
dist.init_process_group("nccl")
rank = dist.get_rank()
torch.cuda.set_device(rank)
tensor = torch.ones(2, 2).to(torch.cuda.current_device()) * rank
# rank==0 => [[0, 0], [0, 0]]
# rank==1 => [[1, 1], [1, 1]]
# rank==2 => [[2, 2], [2, 2]]
# rank==3 => [[3, 3], [3, 3]]
dist.all_reduce(tensor, op=torch.distributed.ReduceOp.SUM)
print(f"rank {rank}: {tensor}\n")
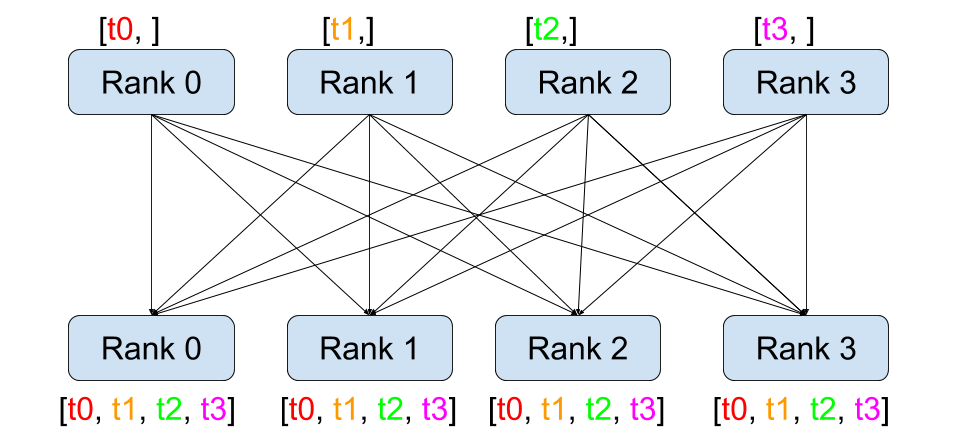
All-gather
`All-gather`은 gather를 수행한 뒤 모아진 결과를 모든 디바이스로 복사한다.
import torch
import torch.distributed as dist
dist.init_process_group("nccl")
rank = dist.get_rank()
torch.cuda.set_device(rank)
input = torch.ones(1).to(torch.cuda.current_device()) * rank
# rank==0 => [0]
# rank==1 => [1]
# rank==2 => [2]
# rank==3 => [3]
outputs_list = [
torch.zeros(1, device=torch.device(torch.cuda.current_device())),
torch.zeros(1, device=torch.device(torch.cuda.current_device())),
torch.zeros(1, device=torch.device(torch.cuda.current_device())),
torch.zeros(1, device=torch.device(torch.cuda.current_device())),
]
dist.all_gather(tensor_list=outputs_list, tensor=input)
print(outputs_list)
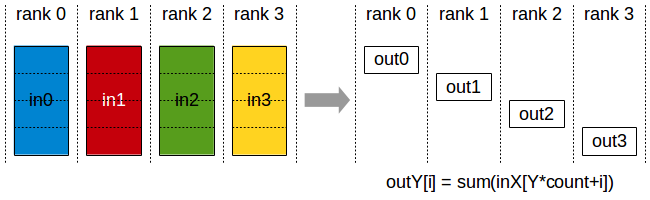
Reduce Scatter
`Reduce scatter`는 Reduce를 수행한 뒤 결과를 쪼개 모든 디바이스에 반환한다.
import torch
import torch.distributed as dist
dist.init_process_group("nccl")
rank = dist.get_rank()
torch.cuda.set_device(rank)
input_list = torch.tensor([1, 10, 100, 1000]).to(torch.cuda.current_device()) * rank
input_list = torch.split(input_list, dim=0, split_size_or_sections=1)
# rank==0 => [0, 00, 000, 0000]
# rank==1 => [1, 10, 100, 1000]
# rank==2 => [2, 20, 200, 2000]
# rank==3 => [3, 30, 300, 3000]
output = torch.tensor([0], device=torch.device(torch.cuda.current_device()),)
dist.reduce_scatter(
output=output,
input_list=list(input_list),
op=torch.distributed.ReduceOp.SUM,
)
print(f"rank {rank}: {output}\n")
Barrier
`Barrier`는 프로세스를 동기화하기 위해 사용한다. 먼저 barrier에 도착한 프로세스는 모든 프로세스가 해당 지점까지 실행되는 것을 기다린다.
import time
import torch.distributed as dist
dist.init_process_group("nccl")
rank = dist.get_rank()
if rank == 0:
seconds = 0
while seconds <= 3:
time.sleep(1)
seconds += 1
print(f"rank 0 - seconds: {seconds}\n")
print(f"rank {rank}: no-barrier\n")
dist.barrier()
print(f"rank {rank}: barrier\n")
Reference
[1] https://nbviewer.org/github/tunib-ai/large-scale-lm-tutorials/blob/main/notebooks/