성능 최적화
데이터를 사용한 성능 최적화
- 일반적으로 ML/DL 알고리즘은 데이터양이 많을수록 성능이 좋기 때문에 가능한 많은 데이터를 수집
- 많은 데이터를 수집할 수 없다면 직접 데이터를 만들어 사용
- 활성화 함수로 시그모이드(0~1의 값), 하이퍼볼릭 탄젠트(-1~1의 값) 등을 사용하여 데이터셋 범위를 조정
- 정규화, 규제화, 표준화 등도 성능 향상에 도움
알고리즘을 사용한 성능 최적화
ML/DL을 위한 다양한 알고리즘 중 유사한 용도의 알고리즘들을 선택하여 모델을 훈련시켜 보고 최적의 성능을 보이는 알고리즘을 선택해야 한다.
알고리즘 튜닝을 위한 성능 최적화
모델을 하나 선택하여 훈련시키려면 다양한 하이퍼파라미터를 변경하면서 훈련시키고 최적의 성능을 도출해야 한다.
- 진단 : 성능 향상이 어느 순간 멈췄을 때, 모델에 대한 평가를 바탕으로 모델이 `과적합(overfitting)`인지 혹은 다른 원인이 있는지에 대한 인사이트를 얻을 수 있다.
- 훈련 성능이 검증보다 눈에 띄게 좋다면 과적합을 의심할 수 있으며, 이를 위해 규제화를 진행
- 훈련과 검증 결과가 모두 좋지 않으면 `과소적합(underfitting)`을 의심할 수 있으므로 네트워크 구조를 변경하거나 훈련을 늘리기 위해 에포크 수를 조정
- 훈련 성능이 검증을 넘어서는 변곡점이 있다면 조기 종료를 고려
- 가중치 : 가중치에 대한 초깃값은 작은 난수를 사용
- 작은 난수라는 숫자가 애매하면 오토인코더 같은 비지도 학습을 이용해 가중치 정보를 얻기 위한 사전 훈련을 진행한 후 지도 학습을 진행
- 학습률 : 학습률은 모델의 네트워크 구성에 따라 다르므로 초기에 매우 크거나 작은 임의의 난수를 선택하여 학습 결과를 보고 조금씩 변경
- 네트워크의 계층이 많다면 학습률은 높아야 하며, 네트워크의 계층이 몇 개 되지 않는다면 학습률은 작게 설정
- 활성화 함수 : 활성화 함수의 변경은 손실 함수도 함께 변경해야 하는 경우가 많기 때문에 신중하게 결정
- 일반적으로 활성화 함수로 시그모이드나 하이퍼볼릭 탄젠트를 이용했다면 출력층은 소프트맥스 혹은 시그모이드 함수
- 배치와 에포크 : 일반적으로 큰 에포크와 작은 배치를 사용하는 것이 최근 딥러닝의 트렌드
- 옵티마이저 및 손실 함수 : 일반적으로 경사 하강법을 사용하지만 네트워크 구성에 따라 `아담(Adam)`이나 `RMSProp` 사용
하이퍼파라미터를 이용한 성능 최적화
배치 정규화를 이용한 성능 최적화
`정규화(normalization)`는 데이터 범위를 사용자가 원하는 범위로 제한하는 것을 말한다. 이는 각 특성 범위(scale)를 조정한다는 의미로 `특성 스케일링(feature scaling)`이라고도 한다. `규제화(regularization)`는 모델 복잡도를 줄이기 위해 제약을 두는 방법이다. 여기서의 제약은 데이터가 네트워크에 들어가기 전에 필터를 적용하는 것이다. 규제화와 관련해서는 `드롭아웃(Dropout)`, `조기 종료(early stopping)` 등이 있다. `표준화(standardization)`는 기존 데이터를 평균은 0, 표준편차는 1인 형태의 데이터로 만드는 방법이다. 표준화는 평균을 기준으로 얼마나 떨어져 있는지 살펴볼 때 사용한다.
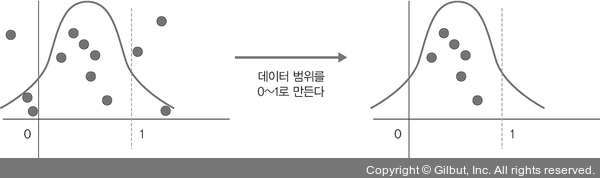
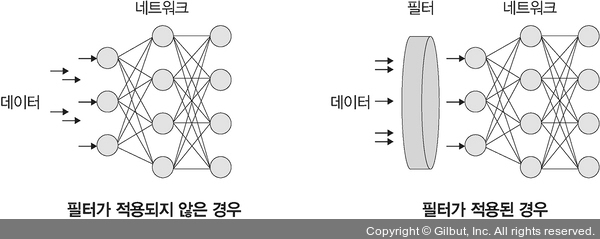
`배치 정규화(batch normalization)`는 `기울기 소멸(gradient vanishing)`이나 `기울기 폭발(gradient exploding)` 같은 문제를 해결하기 위한 방법으로, 데이터 분포가 안정되어 학습 속도를 높일 수 있다. 일반적으로 기울기 소멸이나 기울기 폭발 문제를 해결하기 위해 손실 함수로 `ReLU`를 사용하거나 초기값 튜닝, `학습률(learning rate)` 등을 조정한다.
- 기울기 소멸 : 오차 정보를 역전파시키는 과정에서 기울기가 급격히 0에 가까워져 학습이 되지 않는 현상
- 기울기 폭발 : 학습 과정에서 기울기가 급격히 커지는 현상
기울기 소멸과 기울기 폭발의 원인은 `내부 공변량 변화(internal covariance shift)` 때문인데, 이는 네트워크의 각 층마다 활성화 함수가 적용되면서 입력 값들의 분포가 계속 바뀌는 현상을 말한다. 이를 해결하기 위해 분산된 분포를 정규분포로 만들기 위해 표준화와 유사한 방식을 `미니 배치(mini-batch)`에 적용하여 평균은 0으로, 표준편차는 1로 유지하도록 한다.
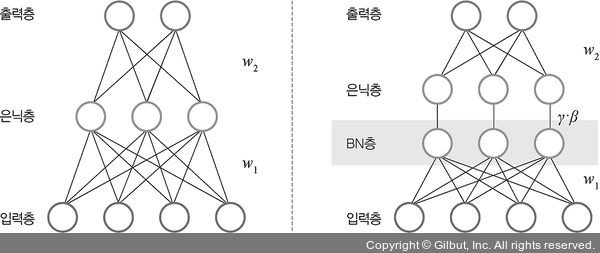
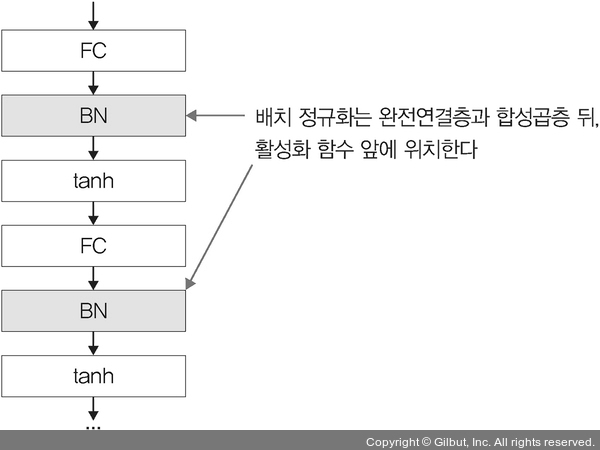
배치 정규화의 순서와 수식은 다음과 같다. 이를 통해 매 단계마다 활성화 함수를 거치면서 데이터셋 분포가 일정해지기 때문에 속도를 향상시킬 수 있지만 이에 따른 단점도 존재한다. 먼저, 배치 크기가 작을 경우에는 정규화한 값이 기존 값과 다른 방향으로 훈련될 수 있다. 또한 `RNN`은 네트워크 계층별로 미니 정규화를 적용해야하기 때문에 모델이 더 복잡해져 비효율적일 수 있다. 따라서 가중치 수정 네트워크 구성 변경 등을 수행하지만 배치 정규화를 적용했을 때 성능이 좋아져 많이 사용된다. 이러한 배치 정규화를 적용한 간단한 신경망 모델은 다음과 같이 구현할 수 있다.
# 배치 정규화가 적용된 네트워크
class BNNet(nn.Module):
def __init__(self):
super(BNNet, self).__init__()
self.classifier = nn.Sequential(
nn.Linear(784, 48),
nn.BatchNorm1d(48),
nn.ReLU(),
nn.Linear(48,24),
nn.BatchNorm1d(24),
nn.ReLU(),
nn.Linear(24, 10)
)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x배치 정규화를 사용하는 이유는 은닉층에서 학습이 진행될 때마다 입력 분포가 변하면서 가중치가 엉뚱한 방향으로 갱신되는 문제가 종종 발생하기 때문이다. 즉, 신경망의 층이 깊어질수록 학습할 때 가정했던 입력 분포가 변화하여 엉뚱한 학습이 진행될 수 있는데 배치 정규화를 적용해서 입력 분포를 고르게 맞추어 줄 수 있다. 또한 배치 정규화의 위치는 다음과 같다.
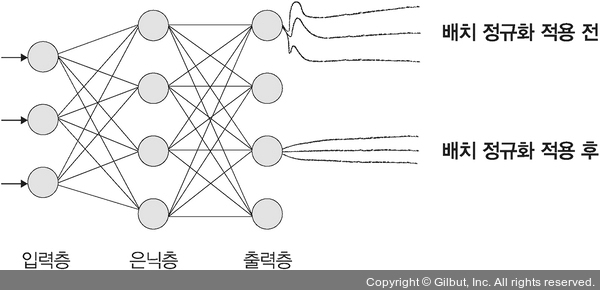
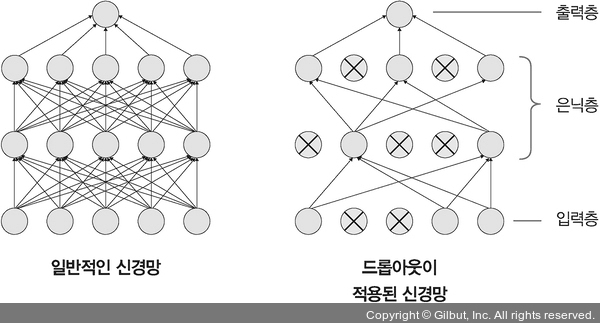
드롭아웃을 이용한 성능 최적화
`드롭아웃(Dropout)`은 훈련할 때 일정 비율의 뉴런만 사용하고, 나머지 뉴런에 해당하는 가중치는 업데이트하지 않는 방법이다. 물론 매 단계마다 사용하지 않는 뉴런은 무작위로 선정하여 매번 바꾸어 가며 훈련한다. 이를 통해 지나친 학습을 방지하여 과적합을 예방할 수 있다. 또한 테스트 데이터로 평가 시에는 노드를 모두 사용하여 출력하되 노드 삭제 비율(드롭아웃 비율)을 곱하여 성능을 평가한다.
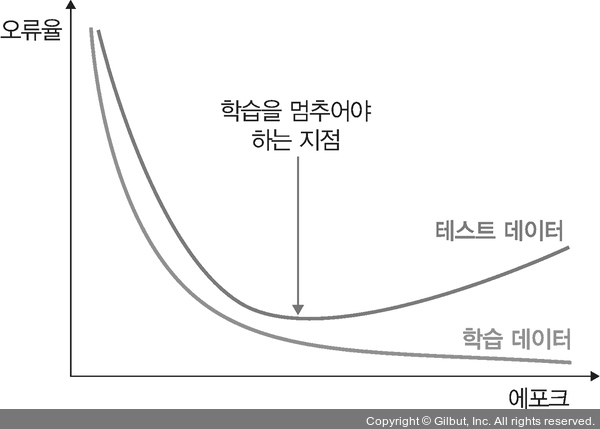
조기 종료를 이용한 성능 최적화
`조기 종료(early stopping)`는 뉴럴 네트워크가 과적합을 회피하는 규제 기법이다. 훈련 데이터와 별도로 검증 데이터를 준비하고, 매 에포크마다 검증 데이터에 대한 `오차(validation loss)`를 측정하여 모델의 종료 시점을 제어한다. 과적합이 발생하기 전까지 학습에 대한 오차와 검증에 대한 오차 모두 감소하지만, 과적합이 발생하면 훈련 데이터셋에 대한 오차는 감소하는 반면 검증 데이터셋에 대한 오차는 증가하는데 이때 오차에 대한 검증이 증가하는 시점에서 학습을 맞추도록 조정한다. 그러나 조기 종료는 학습을 언제 종료시킬지 결정할 뿐이지 최고의 성능을 갖는 모델을 보장하지는 않는다.
이 포스팅은 "딥러닝 파이토치 교과서"를 공부하고 작성한 글입니다.
(이미지 출처 - 더북)