다양한 source의 text로 pre-training을 수행한 모델은 오늘날 NLP의 토대를 형성
pre-trained model을 target task의 도메인에 맞게 조정하는 것이 여전히 도움이 되는지 확인
4개의 도메인(biomedical, computer science publications, news, reviews)과 8개의 classification task를 통해 study
`domain-adaptive pretraining`이 리소스가 많은 환경과 적은 환경 모두에서 성능 향상을 이루어냄을 보임
unlabeled data에 adapting 하는 `task-adaptive pretraining`을 통해 domain-adaptive pretraining 이후에도 성능 향상
간단한 data selection 전략을 사용해 augmented 된 task corpus에 adapting 하는 것이 특히 domain-adaptive pretraining을 위한 리소스를 사용할 수 없을 때 효과적인 대안임을 입증
전반적으로 multi-phase adaptive pretraining이 task performance를 크게 향상시킴
1. Introduction
오늘날의 pretrained LM은 매우 거대한 corpora를 통해 학습
RoBERTa의 경우 약 160GB의 uncompressed text로 훈련
이러한 모델을 통해 학습된 representation은 수많은 task에서 강력한 성능을 보임
특정 주제나 장르(과학 혹은 추리 소설)를 특징짓는 언어 분포를 나타내는데 일반적으로 사용되는 task의 `textual domain`이 여전히 적절한지 의문
최근에 나온 large pretrained model이 광범위하게 작동하는가?
특정 도메인에 대해 별도의 pre-trained model을 구축하는 것이 도움이 되는가?
💡 본 논문에서 제시하는 Language Distribution에 대한 그림. 풀고자 하는 task는 검은색으로 표현되어 있으며, 해당 task에 대한 분포는 회색으로 표현되어 있다. 즉, 회색의 영역에서는 풀고자 하는 task에 대한 다른 unlabeled data가 포함되어 있을 수 있다. 파란색 영역은 타겟 도메인(specific)의 영역이며, 주황색 영역은 일반적인 original LM 도메인의 영역(general)이다. 타겟 도메인의 경우 LM의 pre-training 도메인에 반드시 포함되어야 하진 않기 때문에 overlap이 가능하다. 본 논문에서는 회색 영역에 해당하는 task distribution(TAPT)과 파란색 영역에 해당하는 domain distribution(DAPT)에서의 continued pre-training의 이점을 확인한다.
몇몇 연구들이 특정 도메인의 unlabeled data를 통한 `continued pretraining`의 이점을 증명했지만, 이는 하나의 도메인만 고려하고 최근의 Language Model보다는 더 작고 덜 다양한 corpus에서 사전 학습된 언어모델을 사용
continued pretraining의 이점이 사용가능한 labeled task data의 총합 또는 타겟 도메인과 오리지널 LM 도메인 간의 거리(근접성)와 같은 요인에 따라 어떻게 달라지는지 밝혀지지 않음
이러한 질문에 대해 고성능 모델 중 하나인 `RoBERTa`를 통해 해결
4개의 도메인(biomedical and computer science publications, news, reviews) 각각 2개씩, 총 8개의 classification task를 고려
RoBERTa의 in-domain이 아닌 target의 경우 도메인에 대한 continued pretraining(`Domain-Adaptive PreTraining(DAPT)`)이 리소스가 많은 경우와 적은 경우 모두에서 성능이 일관적으로 향상됨을 확인
모델의 supervised training에 사용되는 것과 같이 task에 사용되는 특정 corpus에서 도메인을 유도하는 것도 가능
task distribution에서 추출한 `unlabeled task dataset`이라는 작지만 직접적으로 task와 관련된 corpus를 통해 DAPT와 `Task-Adaptive PreTraining(TAPT)`를 비교
최신 모델에서 일반적으로 사용되지 않는 TAPT가 효과적임을 확인
DAPT와 TAPT를 함께 사용하거나 혹은 TAPT만 단독으로 RoBERTa의 성능을 크게 향상시키는 것을 확인
task designer 혹은 annotator가 수동으로 curating한 task distribution으로부터의 추가적인 unlabeled data가 있을 경우 TAPT의 이점이 증가
자동으로 additional task-relevant unlabeled text를 선택하는 방법을 제안하며 이를 통해 리소스가 적은 경우 성능을 향상시키는 방법을 보임
모든 task에서 adaptive pretraining technique을 적용한 결과가 SOTA 모델들과 비교해 경쟁력이 있음
본 논문의 contribution
리소스가 적거나 많은 환경에서 4개의 도메인과 8개의 task에 걸쳐 `DAPT`와 `TAPT`를 철저히 분석
도메인과 task에 대한 `adapted LM`의 `trasferability` 조사
사람이 curating한 dataset에 대한 pre-training의 중요성을 강조하며, 자동으로 이러한 performance를 낼 수 있는 간단한 `data selection` 방법을 연구
2. Background: Pretraining
2018부터 NLP research system은 두 가지 단계에 걸쳐 학습을 진행
large unlabeled corpora를 통해 수백만 개의 파라미터로 구성된 `Language Model` 훈련
pretrained model을 통해 학습된 word representation과 network은 선택적으로 update되어(`fine-tuning`) downstream task를 위한 supervised training에 재사용
pretrained LM 중 하나는 `RoBERTa`
`BERT`와 동일한 transformer-based architecture 사용
`Masked Language Modeling` objective, 즉 randomly masked token의 예측에 대한 `cross-entropy loss`를 통해 훈련
RoBERTa를 사전 학습시키기 위한 unlabeled pretraining corpus는 160GB가 넘는 uncompressed raw text로 구성
RoBERTa의 pretraining corpus는 다양한 출처를 통해 파생되었지만, 이러한 source가 영어의 대부분의 변화를 일반화하기에 충분한지는 아직 확립되지 않음
RoBERTa의 영역을 벗어난 도메인이 무엇인지 탐색하며, 이를 위해 unlabeled data의 두 가지 범주로 이 대규모 LM을 지속적으로 pre-training 하여 추가 adaptation을 모색
domain-specific text로 구성된 large corpora
주어진 task와 관련된 사용가능한 unlabeled data
3. Domain-Adaptive Pretraining
`Domain-Adaptive PreTraining(DAPT)`은 unlabeled domain-specific text를 통해 RoBERTa를 지속적으로 pre-training
도메인은 Biomedical(BIOMED) papers, Computer Science(CS) papers, news text from REALNEWS, AMAZON reviews 4개
이러한 도메인은 이전에 자주 사용되었으며, 각 도메인마다 text classficiation을 위한 dataset이 존재하기 때문에 선택
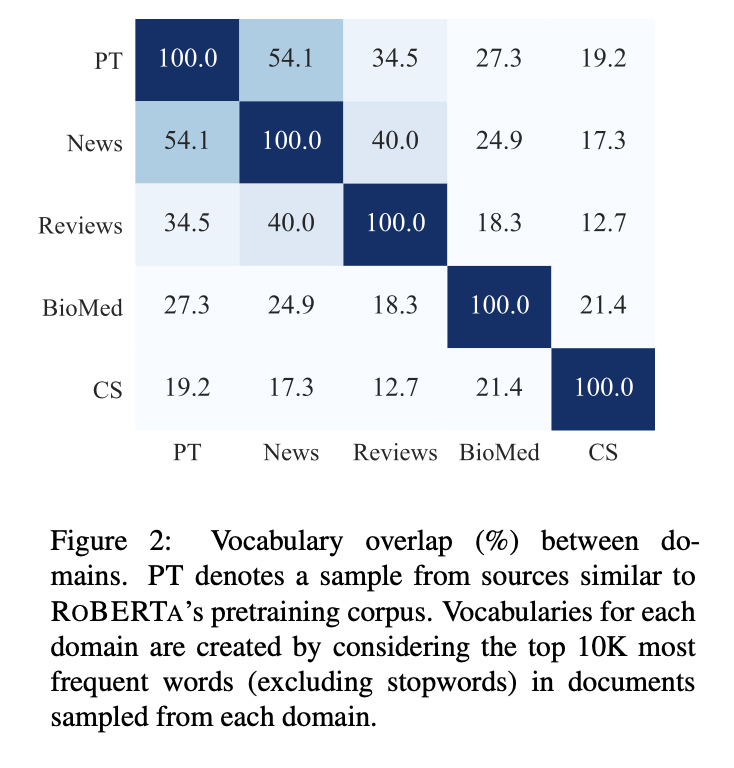
3.1 Analyzing Domain Similarity
`DAPT`를 적용하기 전에 target domain과 RoBERTa의 pre-training domain 간의 `similarity`를 정량화
각 도메인에서 가장 빈번한 10,000개의 상위 `unigram`(stopwords 제외)을 포함한 domain vocabulary 사용
REVIEWS는 데이터의 길이가 짧기 때문에 150K 개의 문서를 사용
REVIEWS를 제외한 다른 3개의 도메인은 50K개의 문서를 사용
RoBERTa의 original pretraining corpus는 공개되지 않았기 때문에 pretraining domain vocabulary를 구성하기 위해 이와 비슷한 Source(BOOKCORPUS, STORIES, WIKIPEDIA, REALNEWS)에서 50K개의 문서를 샘플링
RoBERTa의 pretraining domain은 NEWS와 REVIEWS와의 강한 vocabulary overlap이 있음
CS와 BIOMED는 다른 도메인에 비해 RoBERTa의 pretraining domain과 덜 비슷함
RoBERTa를 다양한 도메인에 적용시켜 기대할 수 있는 이점의 정도를 나타내며, 도메인이 유사하지 않을수록 DAPT의 잠재력은 올라감
3.2 Experiments
본 논문의 LM adaptation은 RoBERTa의 실험 세팅을 따르며, RoBERTa를 각 도메인에 대해 12.5K step으로 학습
step과 batch size가 고정되어 있어 모든 도메인의 dataset에 대해 훈련에 사용되는 데이터의 총합은 동일
각 도메인에 대해 랜덤으로 샘플링된 50K개의 held-out documents에 대한 RoBERTa의 `masked LM loss`를 확인
Table 1에 명시된 pretraining corpus로 사전 학습을 진행하는 `DAPT`의 적용 전과 후의 결과
held-out documents이기 때문에 Pretraining Corpus에서 미리 50K개의 데이터를 test data로 추출시킨 후, 나머지 데이터를 통해 RoBERTa에 대한 사전 학습 진행
💡 hold-out validation
NEWS 도메인에서는 loss 값이 살짝 증가했지만, 다른 모든 도메인에서는 loss 값이 감소
RoBERTa의 pre-training 도메인과의 유사도가 가장 낮았던 CS, BIOMED 도메인에 대한 loss 값이 많이 감소
도메인 유사도가 낮을수록 DAPT의 잠재력은 더 올라감을 확인
각 도메인마다 2개의 classification task에 대해 Labeled data를 통한 fine-tuning
high resource와 low resource(≤ 5K labeled training examples, no additional unlabeled data) 두 가지 경우에 대해 실험
Baseline
Baseline의 경우 RoBERTa의 기본 모델을 사용하며, 각 classification task에 대해 해당 파라미터를 supervised fine-tuning
평균적으로 RoBERTa Baseline은 SOTA 모델에 크게 뒤떨어지지 않는 성능을 보임
다양한 도메인에 대해 단일 LM 모델을 적용하기 때문에 좋은 기준이 됨
Classification Architecture
`BERT`와 동일하게 최종 layer의 [CLS] 토큰의 representation을 예측을 위해 task-specific feed-forward layer에 입력
Results
DAPT가 모든 도메인에서 RoBERTa의 성능을 앞섬
BIOMED, CS, REVIEWS에서 분명한 성능 향상이 있는 것으로 보아, 타겟 도메인과 RoBERTa의 LM 도메인 간의 거리가 멀수록 이점이 있음을 확인
AGNEWS에서는 DAPT의 성능 향상이 없었지만, HYPERPARTISAN을 통해 RoBERTa의 source domain과 밀접한 관련이 있는 도메인에 대해서도 유용함을 확인
3.3 Domain Relevance for DAPT
각 task에 대해 LM을 관심 영역 외부의 도메인에 적용하는 setting과 DAPT를 비교
이는 RoBERTa의 성능과의 비교를 통해 도메인에 관계없이 단순히 더 많은 데이터에 노출시키는 것이 더 좋은 결과를 얻을 수 있는지를 확인
DAPT가 관련 없는 도메인에 적용시킨 경우보다 성능이 훨씬 좋은 것을 통해 domain-relevant data를 통한 pre-training의 중요성을 확인
관련 없는 도메인에 대해 pre-training을 하는 경우 기존에 RoBERTa 모델보다 더 성능이 안좋아지기도 함
대부분의 환경에서 도메인 관련성을 고려하지 않고 무작정 더 많은 데이터에 노출시키는 것은 오히려 end-task performance를 저해시킬 수 있음
그러나 SCIERC와 ACL-ARC dataset에서는 관련 없는 도메인을 적용시킨 경우에 더 성능이 좋아짐
몇몇 경우에는 아무 추가적인 데이터에 대해서 continued pre-training을 하는 것이 유용함
3.4 Domain Overlap
DAPT에 대한 분석은 task data가 어떤 도메인에 적용될지에 대한 사전 직관에 기반함
예를 들어 HELPFULNESS(유용한 리뷰인지에 대한 분류)에 대한 DAPT를 수행하는 경우 AMAZON reviews 데이터만을 사용하며 REALNEWS article 데이터는 사용 x
그러나 Figure 2를 통해 도메인 간의 경계가 어떤 경우 모호함을 알 수 있음
REVIEWS와 NEWS는 40%의 unigram을 공유함
실제로 RoBERTa를 NEWS에 adapting 하는 경우 REVIEWS task에서도 좋은 성능을 보임
HELPFULNESS 65.5(2.3), IMDB 95.0(0.1)
비록 이러한 분석이 포괄적이지는 않지만, 도메인 간의 차이를 야기하는 요인들이 서로 배타적이지 않을 가능성이 있음
전통적인 도메인의 경계선을 넘는 pre-training 과정이 DAPT에 더 효과적일 수 있지만, 이는 향후 연구로 남겨둠
4. Task-Adaptive Pretraining
더 넓은 도메인에 대해 이를 좁게 정의한 subset을 task data라고 할 때, 이러한 task dataset 혹은 task와 관련된 데이터를 통해 사전 학습하는 것이 유용할 것이라는 가설을 설정
`Task-Adaptive Pretraining(TAPT)`은 주어진 task에 대한 unlabeled training set을 통한 사전 학습을 의미
TAPT는 DAPT와 비교했을 때 더욱 task와 관련된 작은 크기의 pretraining corpus를 사용
training set이 task를 더욱 잘 표현한다고 가정(task-relevant)
DAPT보다 훨씬 적은 비용으로 학습이 가능
4.1 Experiments
DAPT와 비슷하게 TAPT 또한 이용가능한 task-specific training data를 통한 RoBERTa 사전 학습의 두 번째 단계로 구성
DAPT는 12.5K step으로 훈련했지만, TAPT는 100 epochs로 훈련
에포크마다 무작위로 다른 단어들을 masking(probability : 0.15)
DAPT의 실험과 동일하게 최종 layer의 [CLS] 토큰의 representation을 task-specific feedforward layer에 입력하여 classification 수행
TAPT는 모든 도메인에서 RoBERTa baseline의 성능을 향상시킴
RoBERTa의 pre-training corpus였던 NEWS 도메인에서도 TAPT는 RoBERTa의 성능을 개선시켜 task adaptation의 이점을 확인
DAPT에 더 많은 resource가 활용됨에도 불구하고 TAPT는 SCIREC과 같은 몇몇 task에서 비슷한 성능을 보임
심지어 RCT, HYPERPARTISAN, AGNEWS, HELPFULNESS, IMDB와 같은 task에서는 DAPT의 성능을 TAPT가 앞서 더욱 저렴한 adaptation 기술의 효과를 강조
Combined DAPT and TAPT
두 adaptation 기술을 함께 사용하는 효과를 확인하기 위해 RoBERTa에 DAPT를 적용한 후 TAPT를 적용
3단계의 pre-training 단계는 모든 setting 중 가장 계산 비용이 많이 듬(Table 9)
DAPT와 TAPT를 조합하여 사전 학습한 경우 모든 task에서 가장 성능이 좋았음
DAPT 이후 TAPT를 적용하는 경우 도메인 및 task에 대한 인식 두 가지를 모두 달성하여 최고의 성능을 냄
Cross-Task Transfer
하나의 task에 adapting 했을 때 같은 도메인 내 다른 task로 transfer가 가능한지를 확인해 DAPT와 TAPT를 비교
예를 들어, LM을 RCT unlabeled data를 통해 사전 학습하고, CHEMPROT labeled data를 통해 fine-tuning 하여 효과 확인
이러한 세팅을 `Transfer-TAPT`라고 정의
모든 도메인에서 Transfer-TAPT의 성능이 기존에 TAPT보다 좋지 않음
특정 도메인 내에서 task들의 데이터 분포는 다를 수 있음
이를 통해 광범위한 도메인에 대해서만 adapting 하는 것이 왜 불충분한지, 그리고 왜 DAPT 이후 TAPT를 적용하는 것이 효과적인지를 설명
5. Augmenting Training Data for Task-Adaptive Pretraining
4장에서는 supervised task를 위한 training data만을 사용한 task adaptation을 위해 LM을 continued pretraining
TAPT의 우수한 성능에 영감을 받아, task distribution에서의 더 큰 unlabeled data(curated by human)가 존재하는 두 가지의 setting을 고려
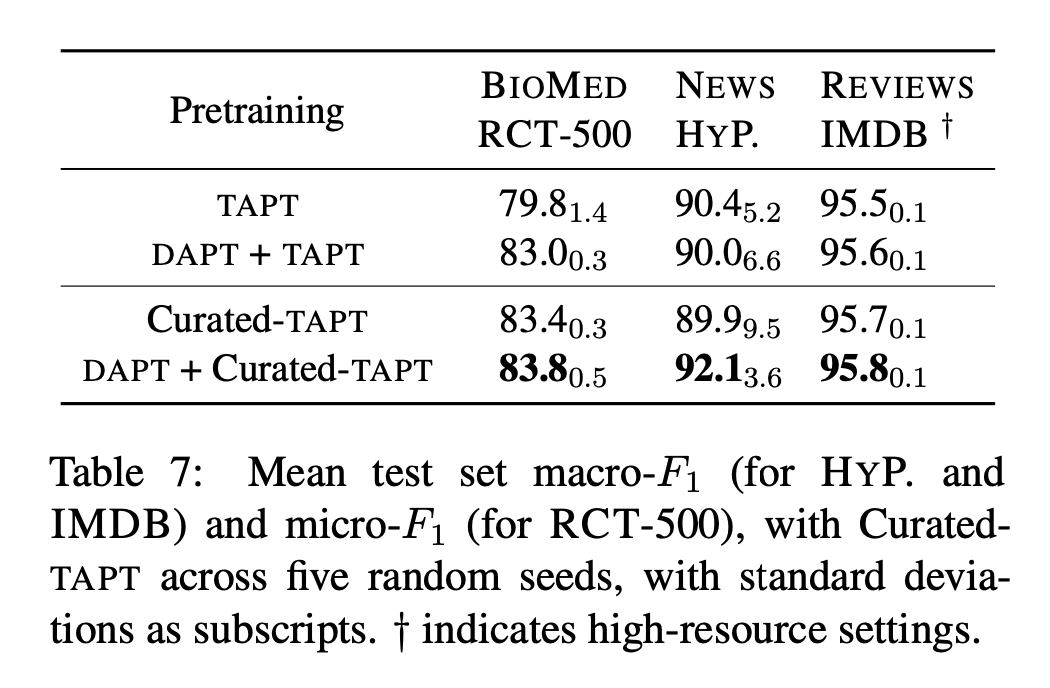
3개의 task(RCT, HYPERPARTISAN, IMDB)에 대해 더 큰 unlabeled data인 `human-curated corpus`를 통해 TAPT를 적용
human-curated data를 이용할 수 없는 경우 large unlabeled in-domain corpus에서 TAPT를 위한 related unlabeled data를 자동으로 찾아 TAPT를 적용
5.1 Human Curated-TAPT
명확한 출처를 통해 large unlabeled corpus를 수집해 annotation budget에 기초하여 annotation을 수행
따라서 task의 training data와 비슷한 분포를 가질 것으로 기대
Data
RCT dataset의 18,040개의 labeled data 중 500개의 데이터만 labeled data로 활용하고 나머지는 unlabeled data로 간주
HYPERPARTISAN의 5000개의 문서는 curated-TAPT unlabeled data로 활용하고, 나머지 데이터 515개는 task fine-tuning에 사용
IMDB의 경우 task annotation를 통해 labeled data와 같은 분포에서 직접 50,000개의 unlabeled data를 추가 수집
Results
`curated-TAPT`가 3개의 dataset 모두에서 이전의 결과보다 좋은 성능을 냄
DAPT 이후 curated-TAPT를 적용할 경우 모든 task에서 큰 개선을 보임
curated-TAPT는 0.3%에 해당하는 labeled data만 활용하고도 RCT의 모든 labeled data를 활용한 DAPT+TAPT의 95%에 해당하는 성능을 냄
task distribution에서 많은 양의 데이터를 curating 하는 것이 end-task performance에 큰 이익을 줌
pretraining을 통한 model adaptation에 도움을 주기 때문에 task designer들이 그들의 task에 대한 많은 양의 unlabeled task data를 푸는 것을 추천
5.2 Automated Data Selection for TAPT
TAPT를 적용할 많은 양의 unlabeled data에 접근할 수 없거나 컴퓨팅 환경에 제약이 있는 상황이 발생할 수 있음
large in-domain corpus에서 task distribution와 유사한 unlabeled text를 가져오는 간단한 unsupervised method
task 및 도메인 텍스트 데이터를 shared space에 함께 임베딩 한 후, 도메인 데이터 중 task-relevant data를 찾는 방식
task data를 사용한 query를 바탕으로 도메인으로부터 candidate를 선택
embedding 방법은 도메인 데이터의 크기가 비교적 크기 때문에 수백만 개의 문장을 합리적인 시간 내에 embed 할 수 있을 만큼 가벼워야 함
lightweight bag-of-words language model인 `VAMPIRE`를 사용
💡 `VAMPIRE`는 A lightweight bag-of-words Language Model이다. 이는 많이 사용하는 `contextual embedding` 방법이 low-resource 상황에서는 효율이 떨어짐을 지적하며 요즘은 잘 쓰이지 않는 `bag-of-words` 방식을 통해 embedding을 진행한다.
VAMPIRE는 unlabeled text의 word frequency matrix를 뽑아낸 후 VAE를 학습하고, 학습이 완료된 VAE의 internal state를 labeled text의 word vector와 결합해 downstream task에 사용하는 방법론이다. 이는 contextual embedding 방식을 사용하지 않기 때문에 `sequential information`는 무시하지만, 학습 비용이 감소하고 labeled data가 적어도 준수한 성능을 낸다는 장점을 가지고 있다.
중복이 제거된 대규모 도메인 샘플(BIOMED stences, 약 100만 개의 문장)과 task data(ChemProt)에 대해 VAMPIRE를 사전 학습시켜 task와 도메인 샘플 모두에서 text embedding을 얻음
VAMPIRE에 매핑하는 도메인 및 task data는 모두 unlabeled data
도메인 embedding에서 각 task sentence에 대한 k개의 후보군을 선택
k-nearest neighbors selection → `KNN-TAPT`
randomly selection → `RAND-TAPT`
TAPT에서 활용하는 task data와 선택된 candidate pool를 모두 사용한 augmented corpus에서 RoBERTa를 pretraining
여기서의 candidate pool은 도메인 데이터에서 선택된 데이터
Results
`kNN-TAPT`가 `TAPT`보다 모든 경우에 성능이 좋음
`RAND-TAPT`는 일반적으로 `kNN-TAPT`보다 성능이 좋지 않았지만 RCT와 ACL-ARC에는 표준 편차 안에 있음
k를 증가시키면 kNN-TAPT의 성능은 꾸준히 증가하며 `DAPT`의 성능에 근접
향후 연구를 통해 좀 더 정교한 data selection 방법에 대해 고려할 필요가 있음
5.3 Computational Requirements
TAPT의 학습 속도는 DAPT에 비해 약 60배 빠르며, DAPT의 저장 용량은 TAPT의 580만 배에 달함
best setting에 해당하는 DAPT + TAPT 모델은 3단계의 pre-training 단계를 거치며, 언뜻 보기에 매우 비용이 비싸 보임
그러나 LM이 한번 광범위한 도메인에 adapt 되면 도메인 내 여러 task에 대해 재사용될 수 있으며, task당 단 한 번의 추가 TAPT 단계만 거치면 됨
Curated TAPT가 비교적 가장 좋은 cost-benefit 비율을 가지고 있는 것처럼 보이지만 large in-domain data에서의 curating에 대한 비용 또한 고려해야 함
kNN-TAPT와 같은 자동화 방법들은 DAPT에 비해 훨씬 비용이 쌈
💡본 논문의 방법론들에 대한 요약 1. `RoBERTa` : 이미 pre-training을 수행한 모델로, labeled task data만을 통해 task 수행 2. `DAPT` : 사전 학습된 RoBERTa에 대하여 추가적으로 domain unlabeled data를 통해 pre-training을 수행 3. `TAPT` : 사전 학습된 RoBERTa에 대하여 추가적으로 task unlabeled data를 통해 pre-training을 수행 4. `DAPT + TAPT` : 3단계에 걸쳐 사전 학습을 진행(RoBERTa + Domain + Task) 5. `kNN-TAPT` : task unlabeled data에 추가적으로 task data와 유사한 k개의 도메인 데이터를 추가적으로 pre-training 수행(K nearest와 random 두 가지 방식으로 데이터를 선택) 6. `Curated-TAPT` : 기존 task unlabeled data에 추가적으로 human-curated task unlabeled data를 사전 학습에 사용
7.Conclusion
실험 결과 수억 개의 파라미터로 구성된 모델조차도 모든 언어는 물론 단일 textual domain의 복잡성을 encoding 하는 데 어려움을 겪음
특정 task나 small corpus에 대해 모델을 pre-training을 해도 상당한 이점이 있음을 보임
본 논문의 연구 결과는 모델을 전문화하기 위해 task or domain relevant corpora를 식별하고 사용하기 위한 노력을 병행하여 더 큰 규모의 LM에 대한 작업을 보완하는 것이 가치가 있음을 시사
강력한 LM인 `RoBERTa`를 개선하는 연구를 수행했지만, 이는 다른 어떤 pretrained LM이어도 적용이 가능
향후 `TAPT`를 위한 더 나은 data selection, 잘 적용하지 못한 도메인에 대한 large pretrained LM의 효율적인 adaptation, adaptation 이후 재사용 가능한 LM의 구축 등의 향후 연구가 필요
Comment
💡 DAPT와 TAPT를 읽으며 드는 생각 - 어찌 보면 당연한 결과라는 생각이 든다. DAPT의 경우 해당 도메인에 관련된 데이터, 그것도 large size의 데이터를 통해 추가적인 사전 학습을 진행했을 때 해당 도메인과 관련된 task에서의 성능 향상은 예측할 수 있는 결과이다. TAPT 또한 해당 task distribution과 유사한 데이터를 확보만 할 수 있다면(비용이 커도 사람이 직접 curating을 하던, 좀 더 큰 범주에서의 도메인 데이터와의 연관성을 통해 추가를 하던, 혹은 더 좋은 data selection 방법을 가져오건) 해당 task를 수행하는 데 모델 성능을 끌어올릴 수 있다. 그러나 해당 논문에선 classification과 관련된 task들만 수행한다. 더 많은 종류의 task에서도 비슷한 결과를 이끌어낼 수 있을지 확인이 필요하다.(그래도 비슷하게 성능이 향상될 것 같다.)
- 이러한 나온지 몇 년이 지난 PLM 관련 논문을 현재 시점에서 읽으면, 아무래도 요즘 유행하고 있는 LLM과 비교하면서 생각하게 되는 것 같다. 결국 이 논문에서 생각할 수 있는 부분은, 도메인 혹은 태스크와 관련이 깊은 데이터를 더 많이 확보하고, 더 많이 학습시킬수록 더 좋은 성능을 낼 수 있다는 부분인 것 같다. 물론, 최근 PLM 모델들은 관련성을 고려하기보단 관련성이 없어도 매우 큰 규모의 데이터를 통해 general한 모델을 만들고 있다. 해당 논문이 나온 2020년과 비교했을 때 3년밖에 지나지 않았음에도 지금은 채팅창에 텍스트를 입력하는 것만으로도 어지간한 태스크는 모두 수행하고, 또 굉장히 많은 사람들이 이용하는 서비스가 되었다. 해당 분야에 대한 연구가 굉장히 빠른 속도로 발전해나가고 있다는 생각이 들었다.