
Language Models are Unsupervised Multitask Learners
0. Abstract
- Question Answering, Machine Translation, Reading Comprehension, Summarization 등의 NLP task들은 task-specific dataset을 통한 Supervised Learning을 활용
- 수백 만개의 webpage들로 구성된 `WebText`라는 dataset을 통해 train할 때 Language Model이 명시적인 supervision 없이도 이러한 task들을 수행하기 시작한다는 것을 입증
- Language Model의 용량은 `zero-shot` task transfer의 성공에 매우 필수적이며, 이것이 개선되면 작업 전반에서 성능이 log-linear 방식으로 향상
- 본 논문의 `GPT-2` 모델은 1.5B parameter를 포함한 Transformer이며, zero-shot으로 설정된 language modeling dataset에서 8개 중 7개 부분에서 SOTA를 달성
- 그러나 여전히 WebText에 대해선 underfit
1. Introduction
- 당시의 Machine Learning system은 generalist보단 좁은 분야에서의 expert와 같은 모습이었지만, 특정 분야를 위해 dataset을 만들고, 각각에 대해 labeling할 필요 없이 다양한 task에 적용시킬 수 있는 general system을 만드려함
- 현재의 ML system에서 single domain dataset에 대한 single task training의 보급이 generalization을 결여시키는 주요한 원인
- robust한 system에 대해 평가하기 위해선 넓은 범위의 도메인과 task에서의 평가가 필요(GLUE, decaNLP 등의 벤치마크)
- `Multi-task Learning`은 모델의 일반화 성능을 평가하기 위해 제안되었지만, NLP에서는 아직 초기에 불과
💡`Multi-task Learning`이란, 하나의 모델을 이용하여 다양한 task를 처리하는 학습 방법을 의미한다. 이와 같이 각 task마다 개별적으로 동작하지 않고 한 개의 모델을 이용하여 multi-task를 처리하게 되면 `one forward propagation`, `one backpropagation`, `lower parameter`와 같은 장점을 얻을 수 있다. 이 뿐만 아니라 여러 모델을 사용할 때보다 메모리 사용량도 적어 실시간으로 동작할 때 효율적일 수 있다. 또한 multi-task가 서로 연관되어 있으면 task를 같이 학습하는데 전체적인 성능을 향상시킬 수도 있다. 일반적으로 multi-task learning은 `shared network`를 통하여 공통의 feature를 추출하고, 그 이후 task별로 추가 학습되는 구조를 가진다.
- `Meta-Learning` 관점에서 각 (dataset, objectives) pair는 dataset과 objective의 분포에서 샘플링된 단일 학습 예제
- 현재의 ML system은 좋은 일반화를 위한 함수를 유도하기 위해 수백 개에서 수천 개의 example이 필요
- 이는 Multitask Learning이 현재의 접근 방식으로는 그 잠재력을 실현하기 위해 그만큼 수많은 effective training pair가 필요함을 나타냄
- 현재의 기술로는 dataset의 생성과 objective의 설계를 필요한 수준으로 계속 확장하는 것은 어렵기 때문에 이에 대한 추가적인 설정을 모색하게 됨
- 현재 NLP task에서 좋은 성능을 내는 모델들은 `pre-training`과 `supervised fine-tuning`을 결합한 형태를 이용
- 그러나 이 또한 여전히 어떠한 task를 수행하는 데 supervised training이 필요
- supervised data가 없거나 매우 적은 상황에서 `commonsense reasoning` 혹은 `sentiment analysis` 등의 task를 수행하는 language model의 가능성을 보여준 연구들 존재
- 본 논문은 language model이 어떠한 파라미터 혹은 architecture의 변경 없이 zero-shot 환경에서 downstream task을 수행할 수 있음을 증명
2. Approach
- Language Modeling에서 general system은 같은 input을 통해서도 다양한 task를 수행해야 하기 때문에, input뿐만 아니라 task에 대해서도 고려해야 함 → p( output | input, task )
- single task에 활용하는 모델링의 경우 p( output | input )
- GPT-2는 fine-tuning을 따로 수행하지 않는 대신 input에 task 정보를 함께 포함하여 입력
- 언어는 task, input, output을 모두 sequence의 형태로 표현할 수 있는 유연성을 제공
- translation training → ( translate to french, english text, french text )
- reading comprehension training → ( answer the question, document, question, answer )
- 이는 `MQAN`이라는 단일 모델을 훈련시켜 다양한 task를 추론하고 수행하는 논문을 통해 입증
- McCann et al., (2018)에 따르면 Language Modeling이 Multitask Learning의 경우 어떠한 symbol이 예측해야할 output인지를 supervision 없이 해당 task를 원칙적으로 수행할 수 있다 언급
- supervised objective가 sequence의 일부 subset을 통해 평가하는 것 외에 unsupervised objective가 동일하기 때문에, unsupervised objective의 global minimum은 supervised objective에서도 동일
- 대신 unsupervised objective가 convergence에 최적화될 수 있는지가 문제가 됨
- 실험을 통해 충분히 큰 Large Language Model은 이러한 환경 속에서 충분히 multitask learning이 가능하지만, 학습 속도는 supervised approach보다 느림
2.1 Training Dataset
- 가능한 한 다양한 domain과 context에서 natural language demonstrates를 수집하기 위해 크고 다양한 dataset 구축
- 가장 다양하고, 거의 무제한에 가까운 Common Crawl과 같은 web scrape가 주요 출처
- 이러한 자료들은 현재의 dataset보다 매우 큰 규모이지만, 데이터 품질에 문제가 있음

- 따라서 document quality에 집중한 새로운 web scrape를 만들었고, 이를 위해 사람에 의해 선별/필터링된 web page만 스크랩
- 처음부터 모두 사람이 직접 하는 것은 매우 비싸기 때문에, 소셜 미디어 Reddit에서 최소 3개의 karma를 받은 모든 outbound link를 스크랩
- 이러한 자료들은 다른 사용자가 해당 링크에 대해 흥미롭거나, 교육적이거나, 재밌다고 생각한 heuristic indicator
- 그 결과 `WebText` dataset은 4500만 개의 link의 text subset을 포함
- HTML에서 text를 추출하기 위해 `Dragnet`과 `Newspaper content extractor`를 조합
- GPT-2에서의 모든 실험은 2017년 12월 이후에 생성된 link를 포함하지 않는 예비 WebText를 사용했으며, 중복 제거 및 heuristic 기반 정리 과정을 거쳐 총 40GB의 텍스트에 800만 개가 조금 넘는 document를 포함
- WebText 내 Wikipedia에 해당하는 데이터는 다른 dataset에서도 일반적으로 사용하는 데이터이며, 훈련 및 테스트 과정에서 중복으로 인해 분석이 복잡해지는 것을 막기 위해 제거
2.2 Input Representation
- 일반적인 LM은 모든 문자열에 대한 확률을 계산하고, 생성할 수 있어야 하지만 현재의 Large scale LM은 lower casing, tokenization, out-of-vocabulary token과 같은 전처리 과정이 있어 문자열의 공간을 제한
- `Byte Pair Encoding(BPE)`는 character와 word level language model의 중간 지점
- 빈번한 symbol sequence에 대한 word-level input과 빈번하지 않은 symbol sequence에 대한 character-level input 간에 적절한 보간
- 이름과 달리 BPE는 byte sequence보단 Unicode code point에 작동하는 경우가 많음
- Unicode sequence를 위해 사용하는 BPE는 13만 개 이상의 거대한 Vocabulary가 필요
- Byte 수준의 BPE는 단 256개의 vocabulary가 필요해 BPE를 Unicode 수준이 아닌 Byte 수준으로 string에 적용하는 것을 시도
- 그러나 Byte 수준의 BPE에는 dog. , dog! , dog? 와 같이 단어에 무의미한 variation을 추가하는 경향이 있음
- 이는 한정된 Vocabulary 크기를 최적으로 사용하지 못하게 할 수 있어 character 수준 이상의 병합을 막음
- input representation을 통해 word-level LMs의 이점과 byte-level approach의 일반성을 결합
- 이러한 approach 방식은 모든 Unicode에 확률을 할당할 수 있기 때문에 전처리, 토큰화, vocab size에 상관없이 모든 dataset에서 LM을 평가 가능
2.3 Model
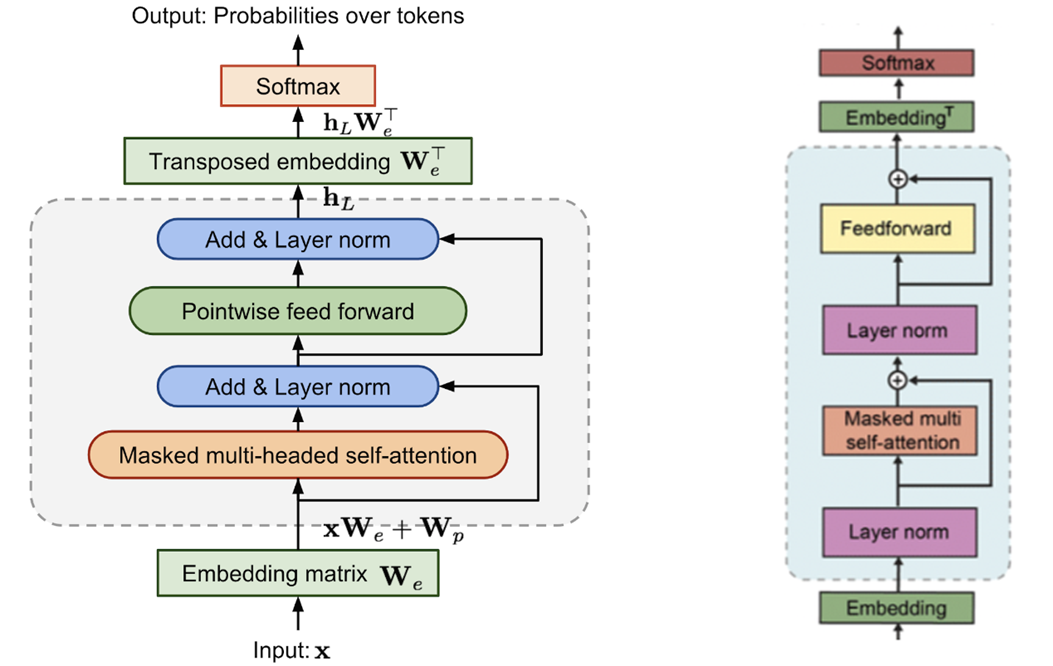
- Transformer 기반의 기존 OpenAI GPT 모델과 몇 가지 차이점 말고는 architecture가 동일
- `Layer Normalization`이 각 sub-block의 input으로 옮겨짐(`pre-activation residual network`와 유사)
- final self-attention block 이후 추가적인 layer normalization이 추가
- 모델 깊이에 따른 residual path의 누적에 관한 부분을 설명하는 initialization 변경
- N 이 residual layer의 개수라고 할 때, initialization의 residual layers의 가중치에 1/√N 을 곱해줌
- vocabulary가 50,257개로 확장
- context size를 512에서 1,024 token으로 증가시키고 batch size 또한 512로 증가
💡 `GPT` 모델에서는 Layer Normalization을 Transformer Decoder block에서 Masked-Self Attention 및 FFNN 이후에 적용했다. 또한 vocabulary 개수는 40,478개이다.
3. Experiments
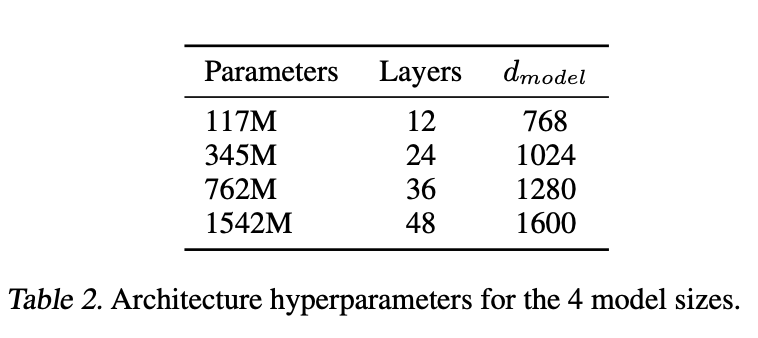
- 가장 작은 LM은 `GPT-1` 아키텍쳐와 동일
- 두번째 작은 LM은 BERT_LARGE 아키텍쳐와 동일
- `GPT-2`는 GPT-1보다 훨씬 많은 파라미터를 보유(3,4번째 LM)
- 각 모델의 `learning rate`는 5%의 WebText 샘플에서 최상의 perplexity를 얻기 위해 수동으로 조정
- 모든 모델은 WebText dataset을 충분히 학습하지 못했으며, 더 많은 training time을 통해 개선 가능
3.1 Language Modeling
- 다양한 benchmark dataset에 zero-shot setting에서의 성능을 검증
- GPT-2는 byte-level로 작동하기 때문에 lossy pre-processing 혹은 토큰화 과정이 필요 없어 어떤 language model benchmark에서도 평가가 가능
- <UNK>은 WebText의 약 400억 byte 중 단 26개에 불과
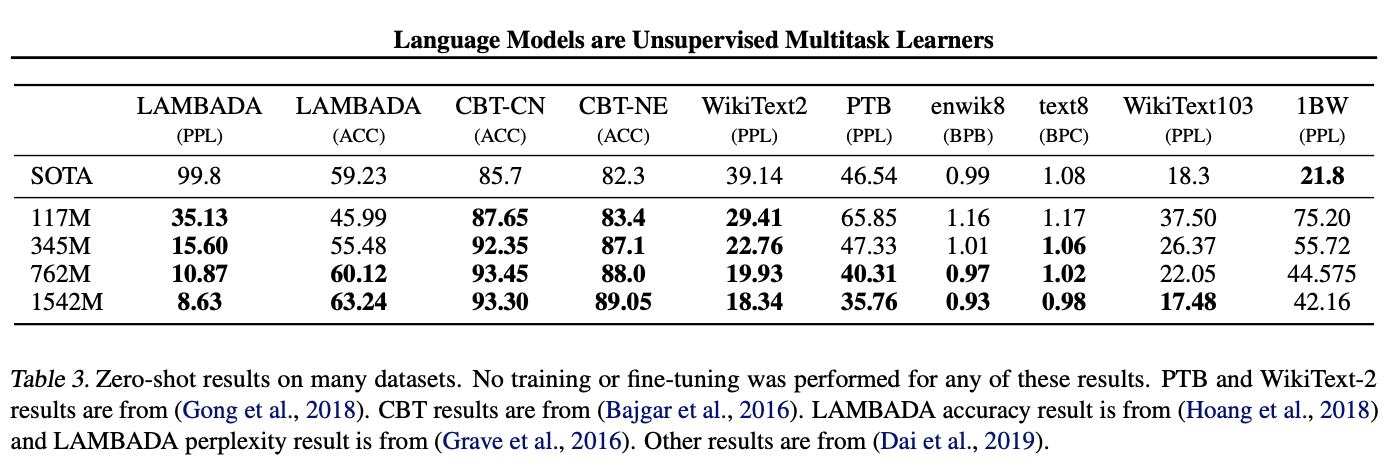
- WebText LM은 도메인과 dataset을 넘나들며 잘 transfer되며, fine-tuning을 거치지 않는 zero-shot 환경임에도 불구하고 총 8개의 dataset에서 7개 분야에 SOTA 달성
- 1백만 개에서 2백만 개 정도의 training token으로 구성된 `WikiText-2` 혹은 `Penn Treebank`와 같은 작은 dataset에서도 큰 성능 향상을 이룸
- long-term dependency를 측정하기 위해 사용하는 `LAMBADA`와 `Children's Book Test` 등의 dataset에서도 좋은 성능을 보임
- `One-Billion Word Benchmark` dataset에서는 이전보다 훨씬 좋지 못한 성능을 보임
- 1BW dataset이 가장 큰 데이터세트인 동시에 sentence level shuffling을 통해 모든 long-range 구조를 제거하는 파괴적인 전처리를 하기 때문으로 보임
3.2 Children's Book Test
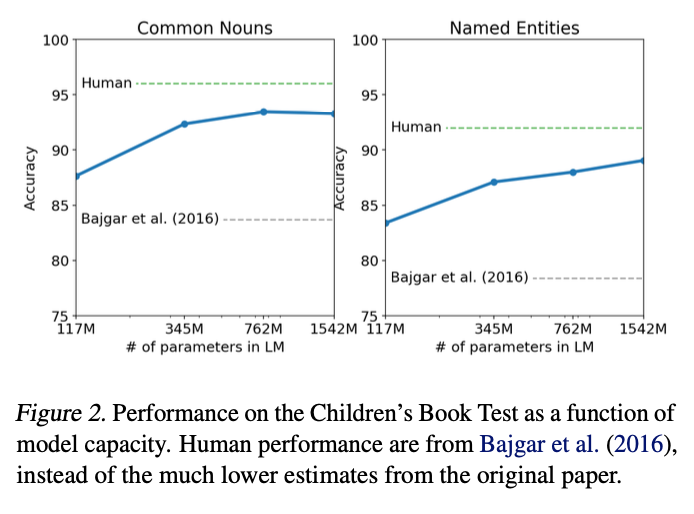
- named entities, nouns, verbs, prepositions와 같은 word의 다른 category에 대한 LM의 성능을 평가
- CBT에서는 perplexity 대신 생략된 단어에 대해 10개의 가능한 선택지 중 올바른 정답을 예측하는 과제의 정확도로 평가
- 각 선택지와 해당 선택지와 관련된 나머지 문장에 대한 확률을 계산한 후 가장 높은 확률에 해당하는 단어를 예측
- model size가 증가할수록 성능은 계속해서 증가했으며, 인간의 능력에 버금가는 성능을 보여줌
- 데이터 중복 검사를 한 결과 CBT의 The Jungle Book이라는 책이 WebText에 포함되어 있어, 크게 중복되지 않는 검증 세트를 통해 결과를 확인
- GPT-2는 common nouns에서 93.3%, named entities에서 89.1%의 성능으로 SOTA 달성
3.3 LAMBADA
- text의 `long-range dependency`을 modeling하는 성능을 평가하는 dataset
- 인간은 예측할 수 있는 최소 50 토큰 이상의 sentences에 대해 마지막 word를 예측하는 task
- GPT-2는 해당 dataset에서 SOTA 달성
- perplexity는 99.8에서 8.6으로 굉장한 성능 향상을 이루어냈으며, 정확도 또한 19%에서 52.66%로 상승
- GPT-2의 오류를 분석해보면 문장의 유효한 연속적인 예측이지만, 유효한 최종 단어는 아님
- 이는 LM이 단어가 문장의 마지막이 되어야한다는 유용한 constraint를 사용하지 않은 것을 의미
- 기존 SOTA 모델은 context에서 나타나는 단어로만 model의 output을 구성하게끔 예측을 제한
- stop-word filter를 추가한 결과 accuracy는 63.24%까지 상승해 기존 SOTA 성능에 비해 4%가 향상
3.4 Winograd Schema Challenge
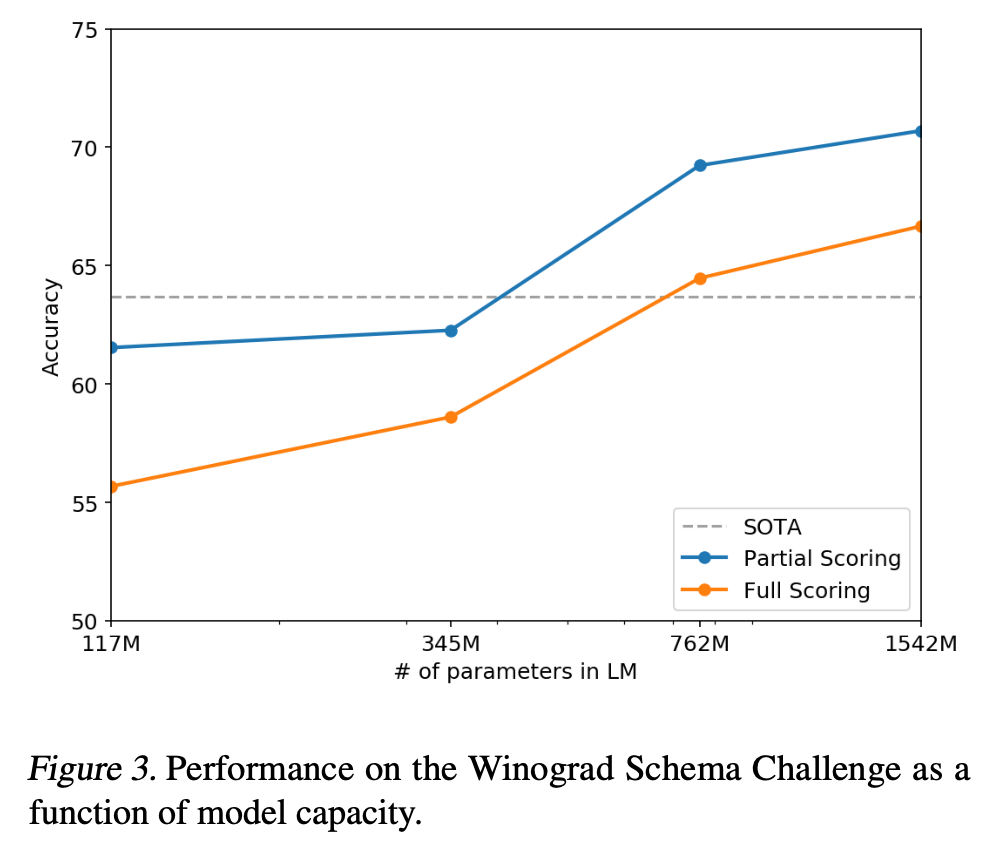
- 텍스트의 모호성을 해결하는 능력을 측정하여 상식적인 추론을 수행하는 시스템의 능력을 평가
- GPT-2는 70.70%의 정확도로 7% 상승시켜 SOTA 달성
3.5 Reading Comprehension
- `CoQA(The Coversation Quesion Answering)` dataset은 7개의 다른 도메인에서 질문자와 답변자의 자연어 대화로 구성
- 독해 능력과 대화 기록에 따라 달라지는 질문(ex> why?)에 대한 모델의 답변 능력을 테스트
- GPT-2는 127,000개가 넘는 supervised-learning data를 사용하지 않고도 55 F1 score를 기록
- SOTA를 달성한 BERT의 89 F1 score에는 미치지 못했지만, fine-tuning을 하지 않았다는 점에서 고무적
3.6 Summarization
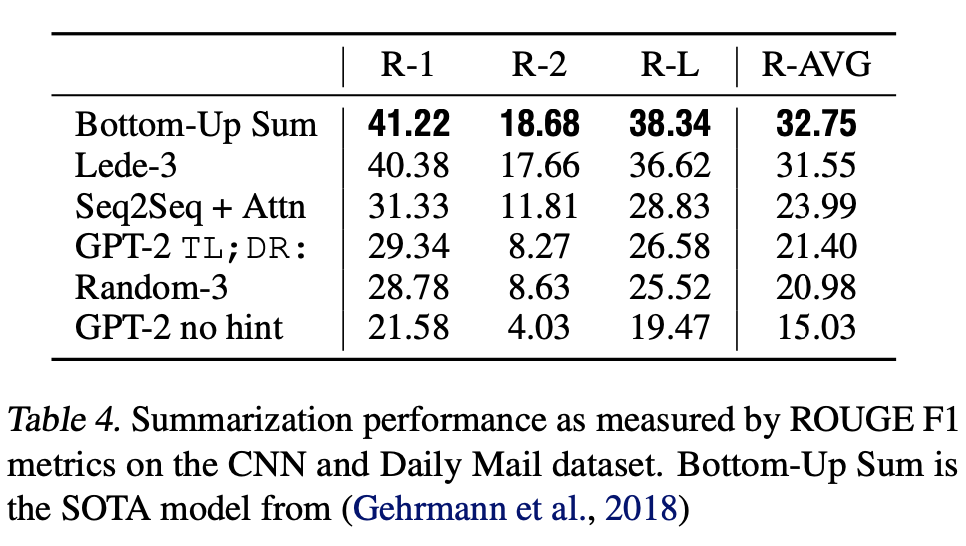
- CNN and Daily Mail dataset을 통해 summarization에 대한 GPT-2의 성능 평가
- summarization 동작을 유도하기 위해 기사 뒤에 TL; DR: text를 추가
- `greedy decoding` 방식보다 반복을 줄이고 더욱 추상적인 요약이 가능하게 하는 `Tok-k random sampling`을 통해 k=2로 100개의 토큰을 생성
- 생성된 100개의 토큰 중 첫 3개의 문장을 summary로 사용
- 생성된 요약은 질적으로는 summary에 비슷하지만, 기사의 최근 내용에 초점을 맞추거나 차량 추돌 사건에서의 차량의 수 혹은 모자나 셔츠에 로고가 있는지 여부와 같은 세부적인 사항에 대해 헷갈리는 경우가 있음
- 이러한 요약은 흔히 사용하는 ROUGE 1,2,L metric에서 랜덤으로 3개를 뽑은 경우의 성능을 간신히 넘김
- 힌트를 제거한 GPT-2 모델은 해당 성능보다 평균 6.4 point 떨어짐
3.7 Translation
- WMT-14 English-French test set을 통해 GPT-2는 5 BLEU를 얻었음
- 이는 word-by-word 모델보다도 낮은 성능으로, 해당 부문에서 좋지 못한 성능을 보임
- WMT-14 French-English test set에서는 11.5 BLEU로 나은 성능을 보였지만, 이는 SOTA 모델(33.5 BLEU)에 못미침
- WebText dataset에서 일부러 영어로 이루어지지 않은 webpage는 제거했기 때문에 성능이 기대 이하
- 이를 확인하기 위해 Webtext에 byte-level language detector를 실행시킨 결과 일반적으로 사용되는 monolingual French corpus에 비해 500배 적은 10MB의 프랑스어 데이터만 감지
- 훈련에 사용한 WebText 데이터셋에 프랑스어와 관련된 데이터가 매우 적어 성능이 낮은 것으로 보임
3.8 Question Answering
- GPT-2는 SQUAD와 같은 reading comprehension dataset에서 일반적으로 사용하는 metric(exatch match)으로 평가했을 때 전체의 약 4.1%에 해당하는 질문에 정답을 맞힘
- 매우 작은 크기의 모델들은 아직 정확도가 1.0%를 넘지 못하고 있으며 GPT-2는 약 5.3배의 질문에 정확한 대답을 했는데, 이는 이러한 task에서 Neural system이 저조한 성능을 보이는데 모델 용량이 주요한 원인임을 시사
- GPT-2가 생성한 대답에 대한 확률은 잘 교정되었으며, GPT-2가 가장 자신 있던 1%의 질문에 대한 정확도는 63.1%
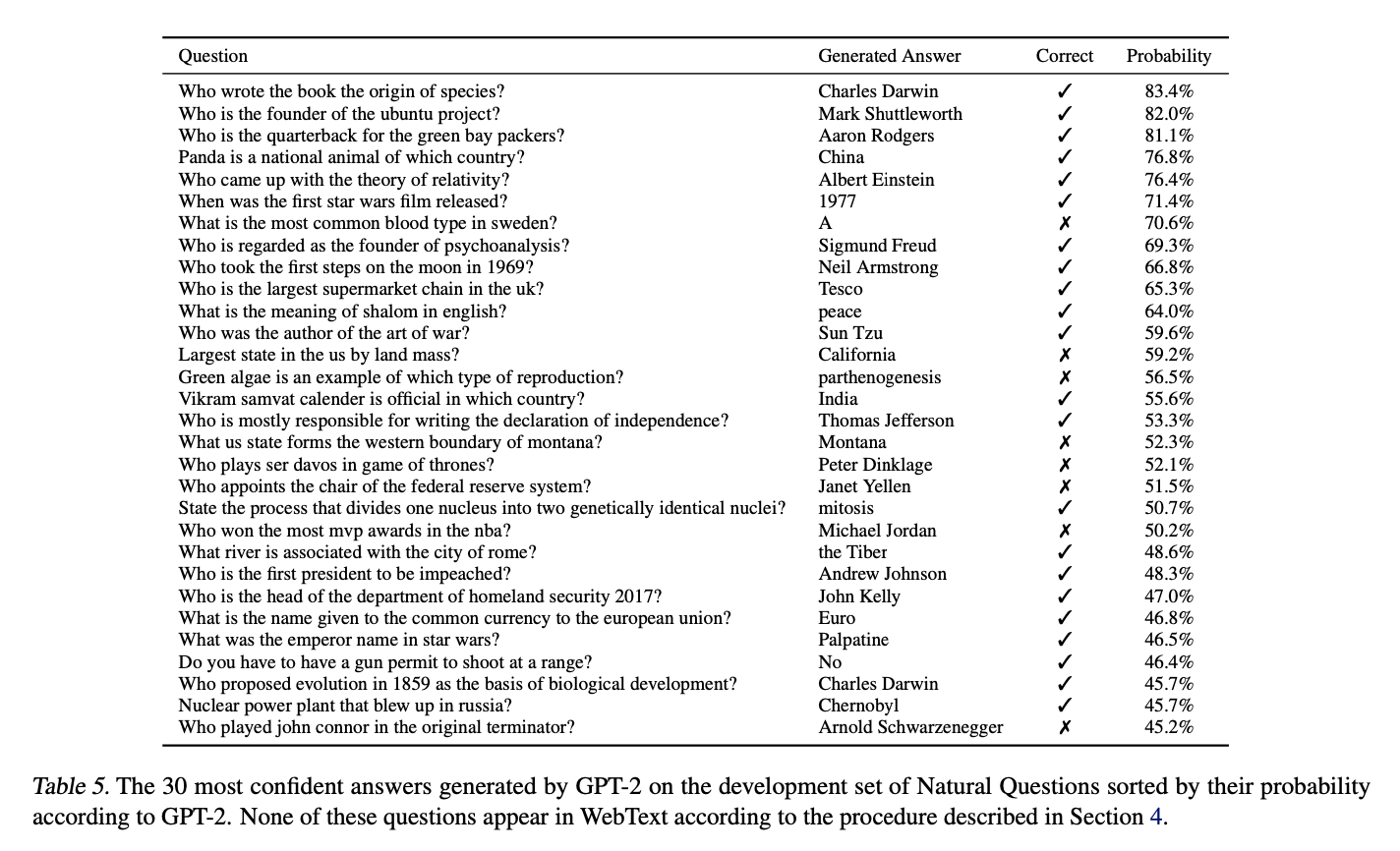
- Table 5의 경우 GPT-2가 가장 자신있게 생성한 30가지의 질문을 나타냄
- GPT-2는 information retrieval과 extractive document question answering을 혼합한 개방형 도메인 question answring 시스템의 30-50% 범위에 훨씬, 훨씬 못미치는 성능을 보유
4. Generalization vs Memorization
- 컴퓨터 비전의 최근 연구들에 따르면 일반적은 image dataset에서는 대부분 중복되는 이미지가 포함
- `CIFAR-10` dataset의 경우 trian과 test images의 3.3%가 overlap
- 이는 머신러닝 시스템의 일반화 성능을 과도하게 나타낼 수 있음
- 이러한 문제점은 WebText dataset 또한 나타날 수 있으며, 얼마나 많은 test data가 training data에 나타나는지 분석하는 것이 중요
- 이를 위해 WebText training set token의 `8-gram`을 포함하는 `Bloom filters`를 생성

- 일반적인 LM datset의 test set은 WebText를 통해 훈련하는 것과 1-6%의 overlap을 기록(평균은 3.2%)
- 많은 dataset은 자체적인 training split을 수행할 경우 평균 5.9%의 overlap이 발생
- 1BW dataset의 경우 자체적인 training set과 약 13.2%의 데이터가 overlap
- WebText training data와 특정한 evaluation dataset의 `data overlap`은 작지만 일관성 있게 결과에 이점을 줌
- 그러나 대부분의 dataset에는 training과 test set 사이에 분명하게 더 큰 overlap이 이미 존재(Table 6)
- data overlap은 중요한 부분이기 때문에 새로운 NLP dataset에 대해 training과 test split을 수행하는 경우 중복 제거에 기반한 n-gram overlap을 중요한 verification step과 sanity check로 사용하는 것을 추천
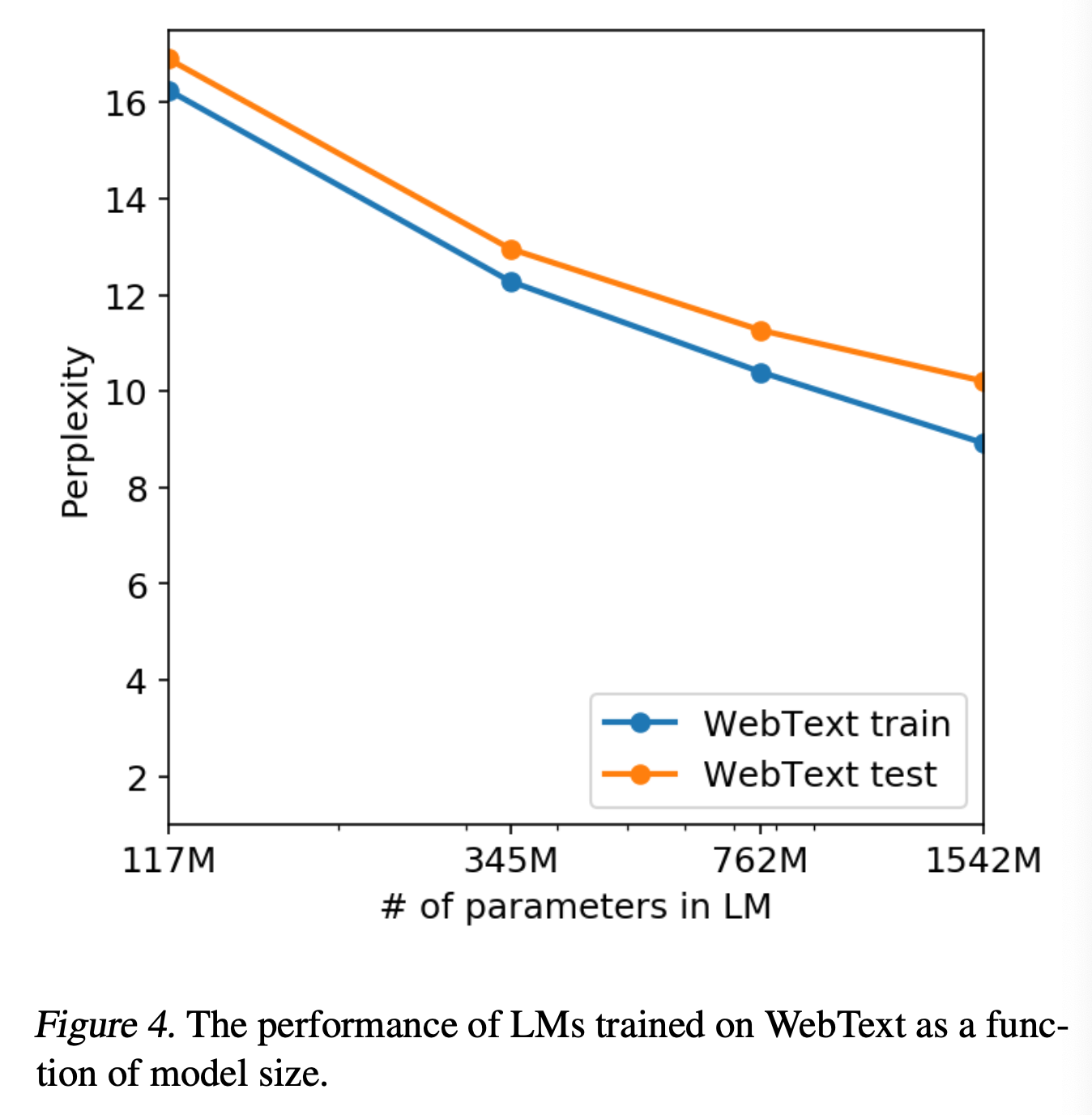
- WebText LM이 `memorization`에 기반하는지 확인하기 위한 또 다른 방법은 자체 hold-out set을 통해 성능을 확인하는 것
- training 및 test set 모두 성능이 비슷하며 모델의 크기가 증가함에 따라 점점 성능이 개선됨
- 이는 여전히 GPT-2가 WeText에 대해 `underfitting`되었다는 것을 확인
6. Discussion
- GPT-2는 supervised adaption 혹은 modification 없이 직접적으로 task를 수행함으로써 `unsupervised task learning`이 앞으로 연구해야 할 유망한 분야임을 시사
- reading comprehension과 같은 분야에서 GPT-2는 zero-shot setting에서 다른 supervised 모델들에 경쟁력을 갖춤
- summarization과 같은 다른 task에서는 정상적으로 task를 수행하긴 하지만, 성능 자체는 아직 초보 수준
- 특정 task에서는 아직 random보다도 더 나은 성능을 GPT-2가 보여주지 못함
- GPT-2의 zero-shot performance는 아직 더욱 연구가 필요
- GPT-2의 fine-tuning을 통한 성능의 한계점이 어디까지인지 불분명
- BERT에서 언급되었던 uni-directional representation의 한계를 GPT-2의 추가적인 용량과 training data를 통해 충분히 극복했는지 불분명
- decaNLP와 GLUE와 같은 benchmark에서의 fine-tuning 계획을 가지고 있음
7. Conclusion
- Large Language Model이 충분히 크고 다양한 dataset을 통해 훈련되면 여러 도메인과 dataset에서 좋은 성능을 발휘할 수 있음
- GPT-2 zero-shots은 8개 중 7개의 language modeling dataset에서 SOTA 달성
- zero-shot setting에서 모델이 수행할 수 있는 task의 다양성은 매우 다양한 text corpus의 likelihood를 최대화도록 훈련된 high-capacity model이 명시적인 supervision 없이도 놀라운 양의 task를 수행하는 방법을 학습하기 시작했음을 시사
Comment
💡 `GPT-2`는 그동안의 pre-training 및 fine-tuning 과정을 통해 NLP의 다양한 task를 수행했던 기존에 방식들과는 다르게, 별다른 supervised fine-tuning 과정 없이 input sequence에 task를 포함하여 원하는 task를 수행하는 `zero-shot learning` 방식을 도입했다. 이를 위해 Large dataset인 `WebText` dataset을 직접 수집하여 모델을 훈련시켰고, 특정 task에서는 zero-shot setting에도 불구하고 8개의 benchmark dataset 중 7개에서 SOTA를 달성하여 dataset의 크기와 모델의 capacity가 중요함을 입증했다.
Summarization, Translation, Qustion-Answering 등 다양한 task에서의 GPT-2는 random으로 예측을 하는 것보다 크게 낫지 않은 성능을 보이는 등 아직 추가적인 연구를 통해 개선할 부분은 많다. 그러나 현실 세계에서 labeled data를 확보하여 모델에 supervised learning을 수행하는 것은 많은 한계점이 있기 때문에, 별다른 fine-tuning 과정 없이 대규모 unlabeled data를 통한 unsupervised learning으로 다양한 NLP task에서 좋은 성능을 보일 수 있는 방법에 대한 가능성을 보였다는 점에서 GPT-2는 의의가 있다.