
RoBERTa: A Robustly Optimized BERT Pretraining Approach
0. Abstract
- Language Model의 Pre-training 과정은 상당한 성능 향상을 가지고 왔지만, 다양한 approach 간에 신중한 비교 필요
- 학습은 상당한 계산 비용이 필요하고, 다양한 크기의 private dataset을 통해 훈련하는 경우가 많음
- hyperparameter에 대한 선택이 최종 결과에 커다란 영향을 끼침
- 본 논문은 `BERT`의 여러 key hyperparameter와 training data size의 영향력을 신중하게 측정하는 replication study
- BERT의 학습이 매우 부족했다는 것을 발견했으며, BERT만으로 이후 개발된 모델들의 성능을 이길 수 있음
- 본 논문의 Best model은 GLUE, RACE, SQuAD에서 SOTA를 달성
- 이러한 결과는 이전에 간과했던 모델 설계의 중요성을 강조
1. Introduction
- `ELMo`, `GPT`, `BERT`, `XLM`, `XLNet` 등의 self-training method들은 대단한 성능을 가졌지만, 해당 모델들의 어떠한 측면이 가장 많이 기여를 했는지 결정하는 것은 쉽지 않음
- 훈련 과정에서의 계산 비용이 비싸기 때문에 파라미터에 대한 tuning의 양도 제한되며, 다양한 크기의 private training data로 훈련되는 경우가 많아 모델링을 통한 개선을 측정하는 것에 한계점 존재
- BERT는 학습이 매우 부족했으며, BERT 이후의 모델들의 성능과 비슷하거나 능가할 수 있는 `RoBERTa`라 부르는 BERT 모델을 훈련하는 recipe를 제안
- BERT에 대한 변경점은 다음과 같음
- training the model longer, with bigger batches, over more data
- NSP loss 제거
- longer sequences를 통해 training
- training data에 따라 masking pattern을 static → dynamic masking으로 변경
- training set size의 효과를 더 잘 제어하기 위해 다른 privately used dataset과 비슷한 크기의 새로운 dataset(`CC-EWS`)를 수집
- 본 논문의 contributions
- 중요한 BERT의 design choice 및 학습 전략과 더불어 downstream task에서 더 좋은 성능을 나타내는 대안을 제시
- 새로운 dataset인 CC-NEWS를 사용하여 pre-training 과정에서 더 많은 데이터를 사용하면 downstream task에서 성능이 향상됨을 확인
- 본 논문의 training imporvements에 따르면 MLM은 올바른 design을 선택하면 최근에 발표된 모든 다른 방법론과 경쟁력이 있음
2. Background
본 챕터에선 BERT 모델에 대한 간략한 설명이 포함되어 있으며, 이는 BERT 논문 리뷰를 통해 더 자세히 확인이 가능하다.
3. Experimental Setup
3.1 Implementation
- 대부분의 hyperparameter는 기존에 BERT와 동일하지만, peak learning rate와 warmup step의 수에서 차이
- Adam epsilon을 민감하게 변경하였고, tuning 이후 더 나은 성능과 안정성의 개선을 이루어냄
- large batch size로 훈련할 시 Beta2 = 0.98로 설정하는 것이 안정성을 향상시킨다는 것을 발견
💡 BERT에서 Adam learning rate의 Beta2 = 0.999로 설정
- pre-train 과정에서 sequence는 대부분 T = 512 tokens으로 학습
- BERT에서는 pre-training 속도 향상을 위해 90%의 update에서 줄어든 sequence length(128 tokens)로 학습
- 이를 개선해 RoBERTa는 오로지 full-length sequence(512 tokens)으로 학습
- Infiniband로 상호 연결된 8개의 32GB Nvidia V100 GPU가 각각 장착된 DGX-1 머신으로 mixed precision floating point 연산 수행
3.2 Data
- 실험을 위해 가능한 많은 데이터를 수집해 각 비교에 적합한 데이터의 전반적인 품질과 양을 맞춤
- 다양한 크기와 도메인을 가진 5개의 English-language corpora를 고려하며, 이는 총 160GB를 넘음
- BOOKCORPUS(16GB) : BERT에서 pre-training에 사용한 데이터(+ Wikipedia)
- CC-NEWS(76GB) : 본 논문에서 수집한 데이터로 약 6,300만개의 뉴스 기사 포함
- OPENWEBTEXT(38GB) : Web text corpus
- STORIES(31GB)
3.3 Evaluation
- 3개의 benchmark를 통해 pre-trained model을 평가
- GLUE, SQuAD, RACE
4. Training Procedure Analysis
- 어떠한 선택이 성공적으로 BERT를 pre-training하는지를 살펴보고, 이를 정량화
- 모델의 architecture는 고정
- BERT_BASE 모델과 같은 구성(L=12, H=768, A=12, 110M params)
4.1 Static vs Dynamic Masking
- original BERT에선 data preprocessing 과정에서 `single static mask`를 한 번 생성
- 모든 epoch의 sequence에서 동일한 masking을 사용하는 것을 피하기 위해 훈련 데이터를 10번 복제하여 40 epoch 동안 각 sequence는 총 10가지의 다른 방식으로 masking
- 따라서 각 training sequence는 training 동안 총 4번의 epoch 동안은 동일하게 masking되어 효과가 떨어지고, 과적합의 위험 존재
💡 Epoch vs Step(Iteration) vs Batch size
- epoch : 전체 데이터를 딥러닝 모델이 총 몇 번 반복해서 학습할지를 결정하는 값
- step(iteration) : 파라미터를 업데이트하는 횟수
- batch size : 파라미터를 업데이트하는데 활용하는 데이터의 개수
- 모델에 sequence를 입력할 때마다 새롭게 masking pattern을 생성하는 `dynamic masking`방식을 비교
- 이는 더 많은 step 혹은 더 큰 dataset을 통해 pre-training할 때 중요한 요소가 됨

- XLNet(reference) 과 static(BERT_BASE), dynamic masking 방법론의 비교
- dynamic masking 기법이 기존에 static masking 기법보다 근소한 성능 우위를 보이며, 추가적인 이점을 고려하여 향후 실험에선 dynamic masking 기법을 활용
4.2 Model Input Format and Next Sentence Prediction
- BERT에선 0.5의 확률로 실제 연속적인 sentence 혹은 랜덤으로 뽑은 sentence를 함께 input sequence에 포함시켜 이것을 구분하는 `Next Sentence Prediction(NSP)` loss를 포함하여 pre-training
- 해당 논문에서 NSP를 수행하지 않을 경우 QNLI, MNLI, SQuAD v1.1 등의 벤치마크에서 주요한 성능 하락이 있음을 보임
- 그러나 최근 연구에선 이 NSP loss의 필요성에 의문을 품고 있으며, 이를 확인하기 위해 여러 대안을 만들어 비교
- SEGEMENT-PAIR+NSP
- BERT의 input과 동일한 구성
- 각 input의 segment 쌍은 여러 natural sentences로 구성 가능하며, 총합 512 토큰을 넘지 않음
- NSP loss 사용
- SENTENCE-PAIR+NSP
- 하나의 문장으로 구성된 하나의 pair로 구성
- 해당 pair는 token의 수가 부족하기 때문에 SEGMENT-PAIR의 토큰 수와 유사하게끔 batch 수를 늘림
- sentence는 연속적이거나 다른 문서에서 가져옴
- NSP loss 사용
- FULL-SENTENCES
- 각 입력은 하나 이상의 문서에서 인접하게 샘플링된 full-sentence
- 총 길이는 최대 512 토큰
- 문서를 넘어가 다음 문서에서 샘플링할 경우 두 문서 사이에 seperate token을 추가
- NSP loss 사용 x
- DOC-SENTENCES
- FULL-SENTENCES와 비슷하게 구성되지만 하나의 문서를 넘어가지 않음
- 이로 인해 512 토큰보다 부족할 수 있기 때문에 FULL-SENTENCES와 토큰 수가 유사하게 batch size를 늘 림
- NSP loss 사용 x
💡 NSP loss를 사용하는 경우는 input이 pair 형태로 들어가지만 각 pair 내에 문장의 개수가 1개인지, 여러 개가 가능한지의 차이이다. 또한 NSP loss를 사용하지 않는 경우에 input은 pair 형태가 아닌 그냥 sentence가 입력되며, 하나의 documnet에서 샘플링했는지, 여러 document를 넘나들며 샘플링했는지의 차이점이 존재한다.

- NSP loss가 포함되어 있는 SEGMENT-PAIR와 SENTENCE-PAIR를 비교했을 때, 하나의 문장을 사용했을 때 긴 범위의 dependencies를 학습할 수 없기 때문에 downstream task의 성능에 나쁜 영향을 끼침
- NSP loss를 제거하는 것이 original BERT 모델보다 성능을 조금 향상시킴
- FULL-SENTENCES와 DOC-SENTENCES를 비교한 결과 sequence를 하나의 문서에서 샘플링하는 것이 더 나은 성능을 내는 것을 확인
- 그러나 DOC-SENTENCES는 batch의 크기가 가변적이기 때문에 비교를 쉽게 하기 위해 FULL-SENTENCE를 향후 실험에서 사용
4.3 Training with large batches
- Neural Machine Translation의 기존 연구에 따르면 mini-batch의 크기를 매우 크게 하면 learning rate가 적당하게 증가할 때 최적화 속도와 end-task에서의 성능을 개선시킨다고 알려짐
- BERT는 256 sequence의 batch size와 1M step으로 학습
- 최근 연구에 따르면 BERT 또한 대규모 batch training이 가능함
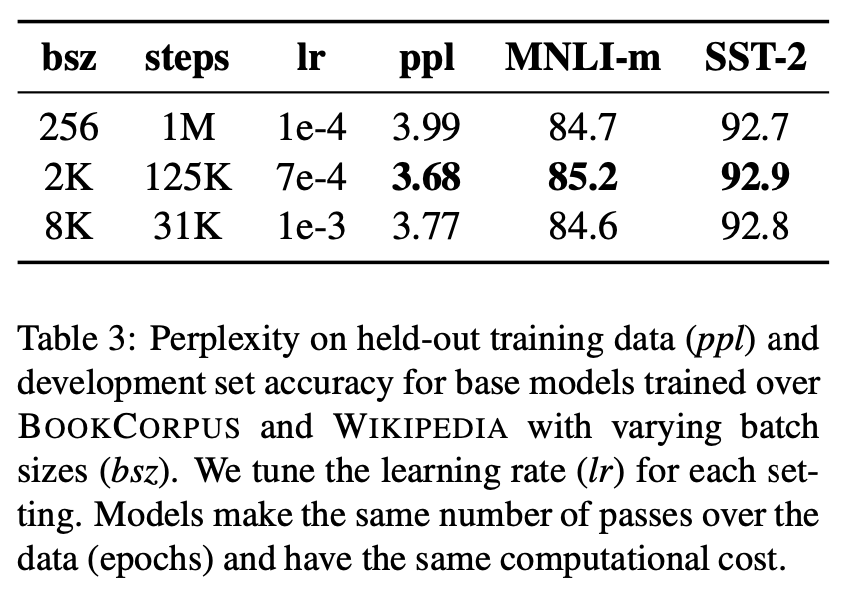
- batch size를 크게 하여 training을 수행했을 때 MLM의 perplexity 및 end-task accruacy를 향상시킴
- batch size를 크게 하는 경우 분산 데이터 병렬 학습에서도 더 쉽게 병렬화를 수행
- 향후 실험에서 8K sequences로 구성된 batch size로 실험 진행
4.4 Text Encoding
- `BPE(Byte-Pair Encoding)`은 character와 word-level의 representation의 조합으로 natural language corpora에서 흔한 large vocabularies를 처리할 수 있음
- BPE는 full words 대신 training corpus의 통계적 분석을 통해 추출한 subwords units을 사용
- BPE의 vocabulary size는 일반적으로 10K-100K개의 subword units
- 그러나 크고 다양한 corpora를 모델링하는 경우 unicode 문자가 어휘의 상당 부분을 차지
- openAI의 GPT-2에선 unicode 문자 대신 bytes를 기본 subword units으로 사용하는 방법을 제시
- bytes를 사용하면 unknown 토큰 없이 모든 입력 텍스트를 encoding할 수 있는 적당한 크기(50K units)의 subword vocabulary를 학습 가능
- original BERT는 character-level의 30K size의 BPE vocabulary를 사용
- 이러한 방식 대신 추가적인 input에 대한 전처리 혹은 토큰화 없이 더 거대한 50K subword units을 포함한 byte-level BPE vocabulary를 사용하여 BERT를 훈련
- 이는 대략 15M, 20M의 추가적인 파라미터 수를 BERT_BASE 및 BERT_LARGE에 더함
5. RoBERTa
- `RoBERTa(Robustly optimized BERT approach)`는 결국 original BERT 모델의 아키텍쳐를 다음과 같이 변경
- Dynamic masking
- FULL-SENTENCES without NSP loss
- Large mini-batches
- larger byte-level BPE
- 추가적으로 BERT모델에선 덜 강조되었던 pre-training 과정에서의 데이터와 학습량(epoch, batch size 등)도 고려
- 실제로 `XLNet`의 경우 BERT보다 10배나 큰 데이터와 8배 큰 batch size로 4배 더 많은 sequence를 pre-training함
- 이러한 요소들을 비교하기 위해 BERT_LARGE (L=24, H=1024, A=16, 335M parameters) architecture를 통해 RoBERTa를 training

- 동일한 데이터(BOOK + WIKI)로 pre-training을 해도 design을 수정한 RoBERTa의 성능이 BERT보다 좋음
- 3개의 추가적인 데이터(16GB → 160GB)를 같은 training steps(100K)로 학습시켰을 때 성능이 향상
- 같은 data 크기와 batch size에서 pre-training steps을 100K → 300K → 500K로 점차 늘렸을 때 XLNet_LARGE 모델보다 성능이 더 좋음
- 가장 긴 training steps을 가진 모델이 overfit하지 않고 추가적인 학습을 통해 성능 향상을 보이는 것을 확인
5.1 GLUE Results

- (single-task single models on dev) setting
- batch sizes : 16, 32
- learning rates : 1e-5, 2e-5, 3e-5
- linear warmup for the first 6% of steps followed by a linear decay to 0
- 10 epochs fine-tuning
- early stopping
- 나머지 hyperparameters는 pre-training 과정과 동일
- 모든 분야에서 SOTA 달성
- (Ensembles on test) setting
- GLUE leaderboard는 multi-task fine-tuning에 의존
- RoBERTa는 single-task fine-tuning만 진행
- 9개 분야 중 4개 분야에서 SOTA 달성
5.2 SQuAD Results
- BERT와 XLNet은 추가적인 QA dataset을 통해 training data를 증강시켰지만, RoBERTa는 주어진 SQuAD training dataㄹㄹ 통해서만 fine-tuning
- XLNet은 추가적으로 layer마다 다른 learning rate를 적용했지만, RoBERTa는 모든 layer에서 동일한 learning rate 적용
- SQuAD v1.1에서는 BERT와 동일한 과정으로 fine-tuning을 했으며, SQuAD v2.0의 경우 주어진 질문에 답변이 가능한지에 대해 추가적으로 분류기를 학습
- 해당 분류기는 classification과 span loss term을 합산해 span predictor와 함께 학습
💡 SQuAD v2.0은 SQuAD v1.1에서 대답하지 못할 가능성도 허락하는데, BERT는 이를 위해 answer span의 start와 end가 [CLS] token에 있는 경우를 대답을 모르는 경우로 간주하여, start와 end answer span의 포지션을 [CLS] 토큰까지 확장하였다.

- RoBERTa는 SQuAD v1.1에선 XLNet과 함께 SOTA를 달성했으며, SQuAD v2.0에서도 SOTA 달성
5.3 RACE Results

- 각 후보 anser을 일치하는 question과 passag와 concate하여 각각 encoding을 수행하고 정확한 답안을 예측하기 위한 full-connected layer에 결과와 [CLS] representation을 입력
- 128 토큰보다 긴 질문-답 pair가 필요한 경우 이를 잘라내 총 길이가 최대 512토큰이 되도록 함
- RoBERTa는 RACE test에서 SOTA 달성
7. Conclusion
- BERT model을 pre-training할 때 다양한 design decision들을 통해 평가
- 다음과 같은 방법들을 통해 성능이 상당히 개선됨을 발견
- Training the model longer, with bigger batches over more data
- Next Sentence prediction의 Loss 제거
- Training on longer sequences
- Training data에 맞게 masking 패턴을 dynamically changing
- RoBERTa고 불리는 개선된 pre-training 방법론은 GLUE에 대한 multi-task fine-tuning과 SQuAD에 대한 추가적인 data 없이 GLUE, RACe, SQuAD에서 SOTA를 달성
- 이전에 간과한 모델 설계에 대한 선택의 중요성을 강조하고, BERT의 pre-training 과정이 현재의 다른 대안들과도 경쟁력이 있음을 제안
Comment
💡 본 논문은 기존에도 좋은 성능을 보여주었던 BERT 모델의 pre-training 구조를 개선시켜 더욱 강력한 모델로 만든 RoBERTa에 대한 논문이다. RoBERTa는 기존 BERT의 구조에서 1) training step, batch size, epoch 및 데이터 크기 증가 2) NSP loss를 제거 3) pre-training 과정에서 sequence의 길이를 512 토큰에 가깝게 유지 4) 모델에 sequence를 입력할 때마다 masking을 변화시키는 dynamic masking 4가지를 변화시켰다.
먼저 1번의 경우, 사실 컴퓨팅 파워만 따라준다면 overfitting이 되지 않는 선에서 많은 데이터와 batch size 및 epoch를 크게 했을 때 학습 성능이 향상된다는 점은 이미 알고 있었던 사실이기에 크게 놀라운 결과는 아니었다. 이는 3번 또한 마찬가지로 pre-training의 속도보단 양을 생각한 선택의 연장선이라고 생각한다. 또한 section 4.3에서 batch size를 2K로 설정했을 때 성능이 가장 좋았는데, 향후 8K로 고정한 것은 데이터의 크기가 훨씬 커지기 때문이라고 생각한다.
NSP Loss를 제거했을 때 classification에 해당하는 fine-tuning 과정에서도 성능이 향상된다는 점은 인상적이었다. 아무래도 이러한 classfication 과정을 pre-training 하는 것보단, input sequence를 pair 형태가 아닌 최대한 많은 sentence를 포함시켜 하나의 sequence에 포함되는 token의 수를 늘리는 것이 pre-training에 더 효과적이라는 생각이 들었다.
Reference
[1] https://arxiv.org/abs/1907.11692
[2] https://xxxxxxxxxxxxxxxxx.tistory.com/entry/Epoch-Step-Batch-size