부스팅(Boosting)
`부스팅(Boosting)`이란 여러 개의 learning 모델을 순차적으로 구축하여 최종적으로 합치는 방법이다. 여기서 사용하는 learning 모델은 매우 단순한 모델이다. 여기서 단순한 모델이란 Model that slightly better than chance, 즉 이진 분류에서 분류 성능이 0.5를 조금 넘는 정도의 수준의 모델을 말한다. 부스팅은 모델 구축에 순서를 고려하기 때문에 각 단계에서 새로운 base learner를 학습하여 이전 단계의 base learner의 단점을 보완하며, 각 단계를 거치면서 모델이 점차 강해진다. 부스팅 모델의 종류로는 `AdaBoost`, `GBM`, `XGBoost`, `Light GBM`, `CatBoost` 등이 있다.
Adaptive Boosting(AdaBoost)
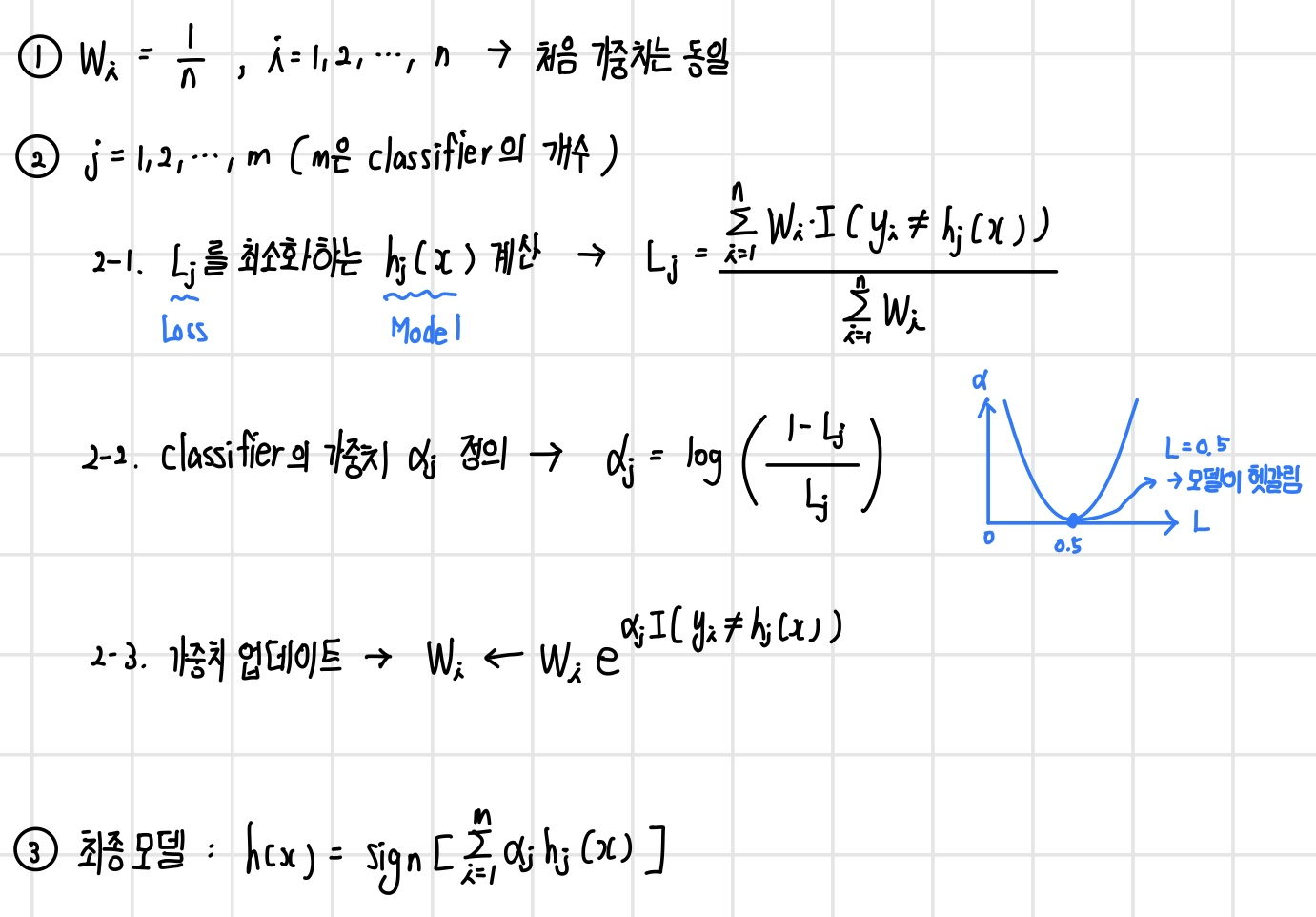
`AdaBoost`는 각 단계에서 새로운 base learner를 학습하여 이전 단계의 base learner의 단점을 보완하는 모델이다. AdaBoost는 training error가 큰 관측치의 선택 확률(가중치)을 높이고, training error가 작은 관측치의 가중치를 낮춰 오분류한 관측치에 보다 더 집중한다. 이렇게 조정된 가중치를 기반으로 다음 단계에서 사용될 training dataset을 구성하여 다시 새로운 base learner를 학습하고 이전 단계의 base learner의 단점을 보완한다. 최종 결과물은 각 모델의 성능지표를 가중치로 하여 결합한다. AdaBoost의 알고리즘은 다음과 같다.
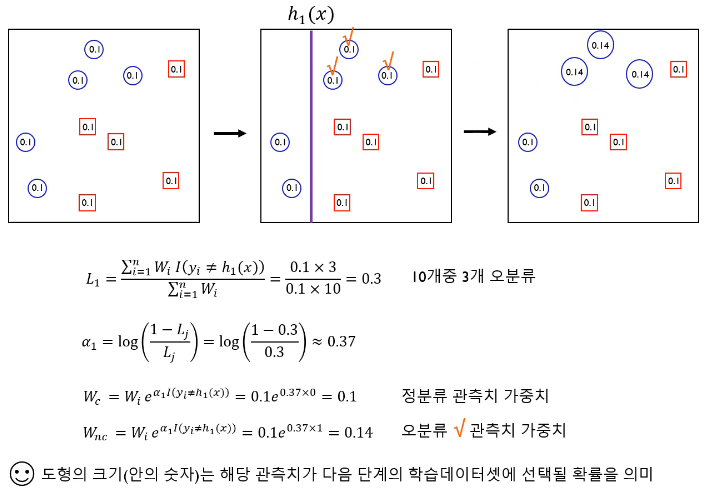
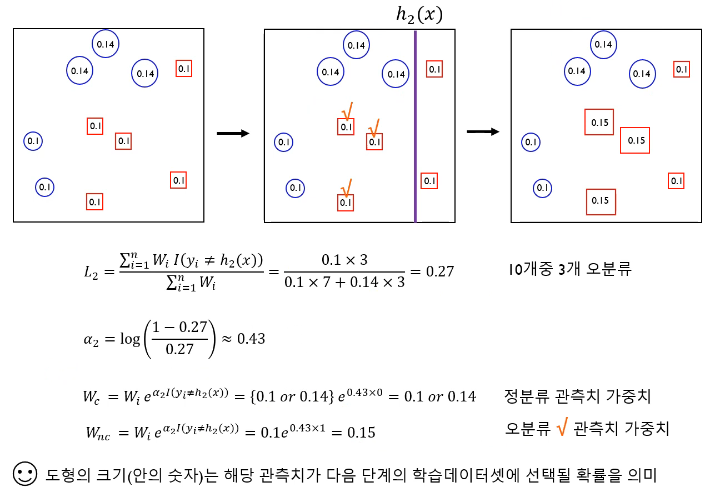
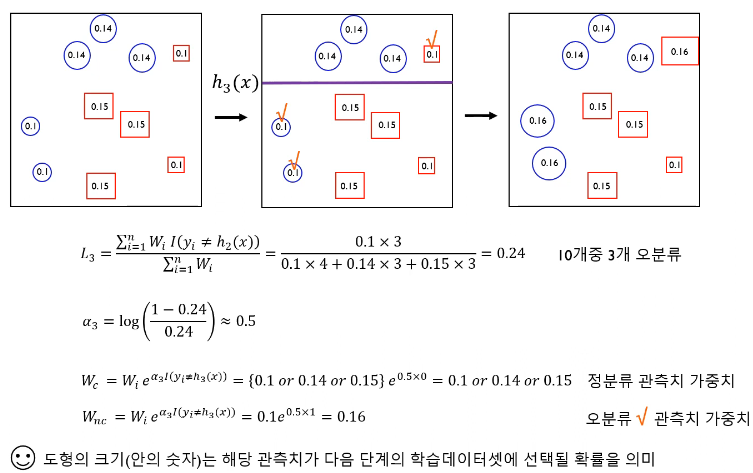
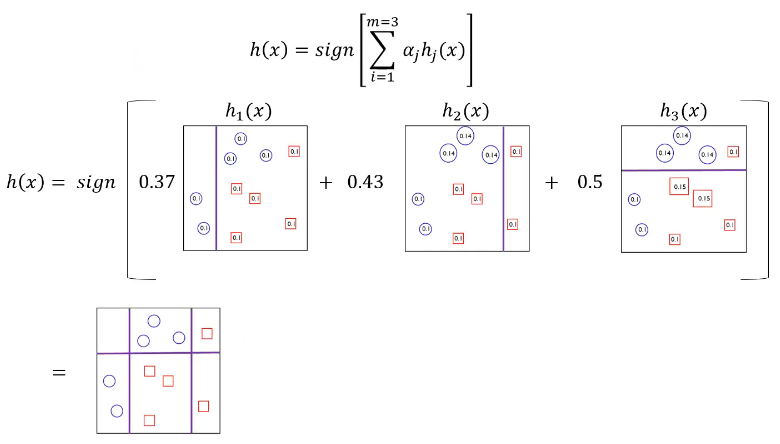
3개의 classifier에 기반한 AdaBoost의 예시를 보면 다음과 같다. Boosting 모델에서 많이 사용되는 base model은 간단한 구조를 가지고 있는 `Decision Tree`이다.
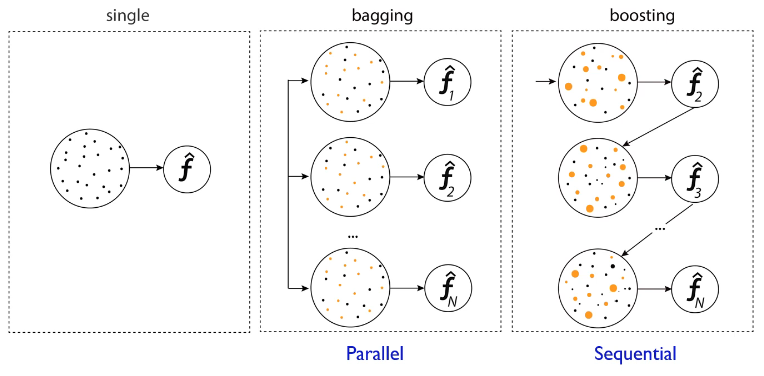
Bagging vs Boosting
`Bagging`은 하나의 train sample로부터 `Bootstrap`을 통해 여러 개의 샘플을 만든 후 각 샘플에 대해 모델을 학습해 이를 가중합하는 기법이다. `Boosting`은 Parallel한 Bagging과 다르게 하나의 train sample에 대해 모델을 구축하고, 해당 모델을 통해 가중치를 새롭게 업데이트하고 다음 모델을 구축하는 Sequential한 기법이다.
Gradient Boosting Machines(GBM)
Gradient boosting이란 Boosting with gradient decent를 의미한다. 즉, 첫 번째 단계의 모델 tree 1을 통해 Y를 예측하고, Residual을 다시 두번째 단계 모델 tree 2를 통해 예측하고, 여기서 발생한 Residual을 모델 tree 3로 예측하는 모델이다. 결국 Gradient boosted model = tree 1 + tree 2 + tree 3가 되며, 각 단계를 거침에 따라 점점 Residual은 작아지게 된다.
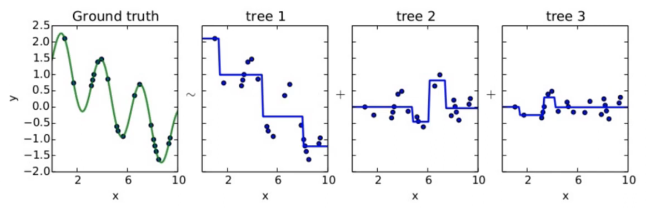
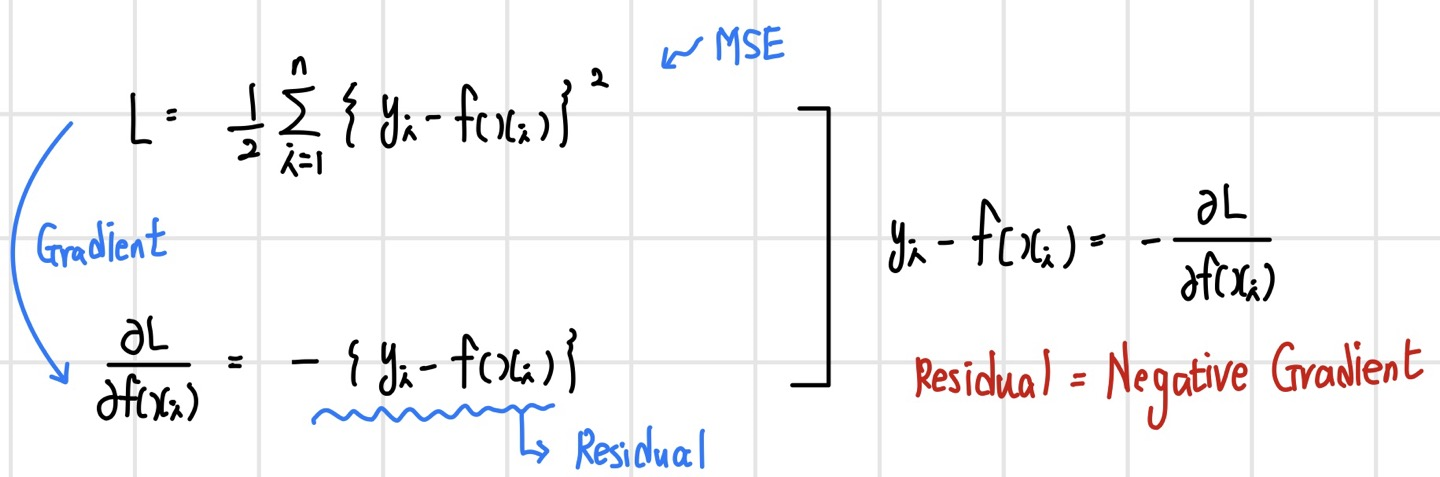
GBM은 Residual을 사용하는 모델이며, 이를 Gradient라고 표현하는 이유는 Residual이 Negative Gradient를 의미하기 때문이다.
이 포스팅은 고려대학교 산업경영공학부 김성범 교수님 유튜브의 핵심 머신러닝 강의를 듣고 작성한 글입니다.