시계열 데이터 예측 분석 방법론 트렌드
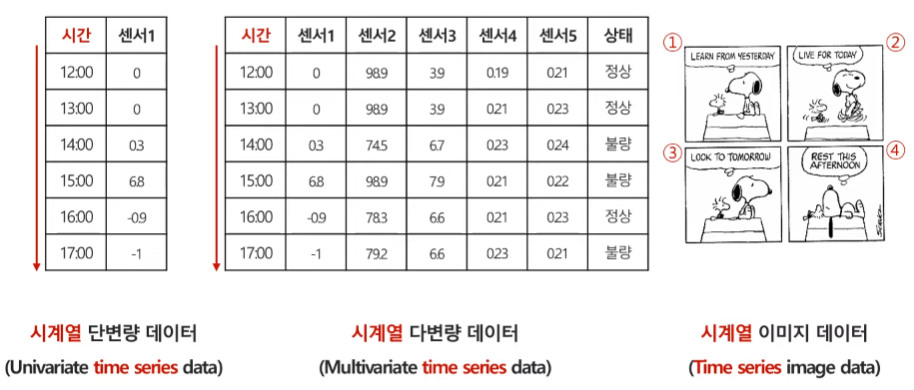
`시계열 데이터(Time Series Data)`란, 시간의 흐름에 따라 순서대로 관측되어 시간의 영향을 받게 되는 데이터를 말한다. 이러한 시계열 데이터에는 `시계열 단변량 데이터(Univariate time series data)`, `시계열 다변량 데이터(Multivariate time series data)`, `시계열 이미지 데이터(Time series image data)` 등이 있다.
전통 통계 기반 시계열 데이터 분석 방법론
- 이동평균법(Moving average)
- 지수평활법(Exponential smoothing)
- ARIMA(Autoregressive integrated moving average) 모델
- SARIMA(Seasonal ARIMA) 모델
- Binary variable model(해당 시점만 1, 나머지는 0으로 변환)
- Trigonometric model(sine과 cosine 함수의 조합으로 표현)
- Growth curve model
- Autoregressive integrated moving average exogenous(ARIMAX) (X변수를 이용하여 시계열 Y 예측)
- Prophet 등
머신러닝 기반 시계열 데이터 분석 방법론
- Support Vector Machine/regression
- Random forest
- Boosting
- Gaussian process
- Hidden Markov model(HMM)
인공지능 기반 시계열 데이터 분석 방법론
- Recurrent Neural Networks(RNN) (1986)
- LSTM (1997)
- GRU (2014)
- Seq2Seq (NIPS 2014)
- Seq2Seq with attention (ICLR 2015)
- CNN and variants (2016)
- Transformer (NIPS 2017)
- GPT-1 (2018), BERT (2019), GPT-3 (2020) 등등의 Transformer 계열 모델
Recurrent Neural Network(RNN)
`순환 신경망(Recurrent Neural Network, RNN)`이란, 이전 시점 정보들을 반영하여 시계열 데이터 모델링에 적합한 인공신경망 모델을 말한다. 기존에 `인공 신경망(DNN)`의 경우 시계열을 반영하지 않기 때문에 t 시점의 어떤 값을 예측할 때 현 시점 정보만 이용을 하게된다. 그러나 시계열을 반영하는 RNN의 경우 t 시점에 예측을 할 때 이전 시점 정보인 t-1, t-2 등의 시점을 반영하여 더 정확하게 t 시점의 예측을 수행한다.
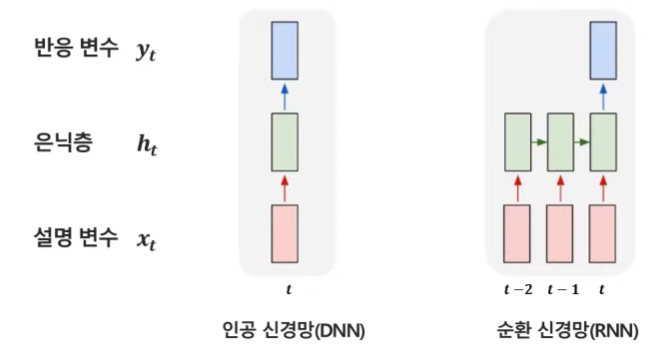
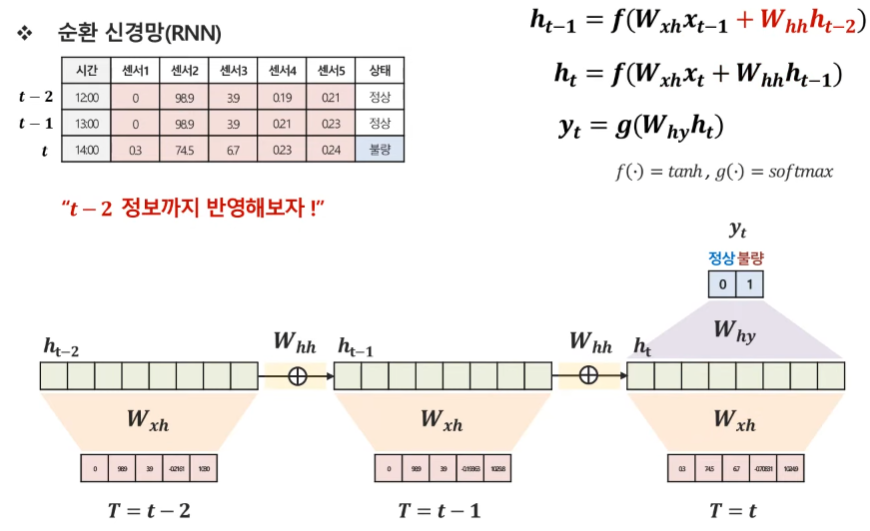
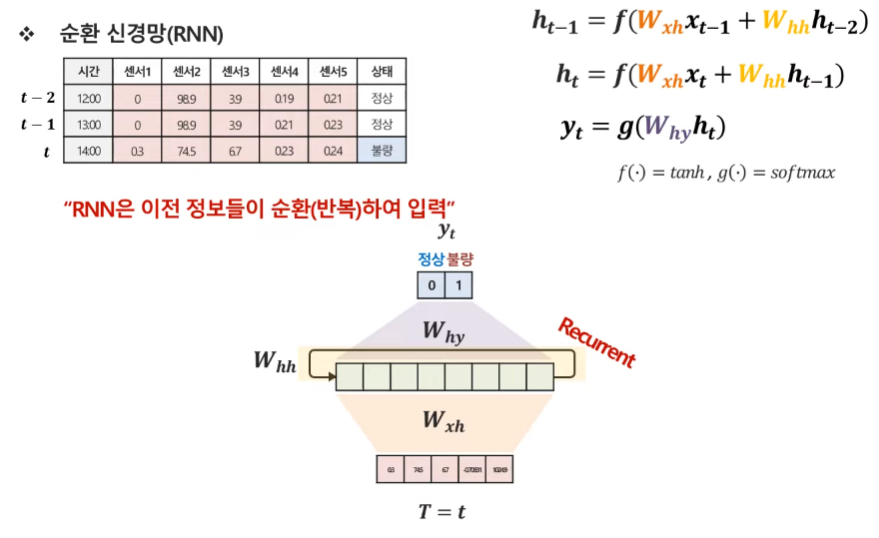
RNN에서 이전 시점들의 정보를 반영하는 방법은 다음과 같다. t 시점에는 t-1 시점의 hidden state를 더해서 활용하고, 여기서 t-1 시점의 hidden state는 t-2 시점의 hidden state를 반영하므로 결과적으로 t 시점의 예측을 수행하는데 t-1 시점과 t-2 시점을 모두 반영하게 되었다. 그러나 시점이 총 3개만 있는 것이 아니라 계속 이어지기 때문에, 이는 계속해서 반복하게 되고 결국 이른 Recurrent(순환, 반복)라고 명칭하게 된 것이다. 여기서 중요한 점은, 해당 모델의 파라미터(가중치, W_xh와 W_hh)들은 시점마다 모두 동일하다.
RNN의 구조의 종류
순환 신경망의 구조의 종류는 다음과 같다. 순환 신경망은 순차적으로 입력하고, 순차적으로 예측하는 것이 가능하며 순차적인 입력의 길이와 순차적인 예측의 길이에 따라 구분된다.
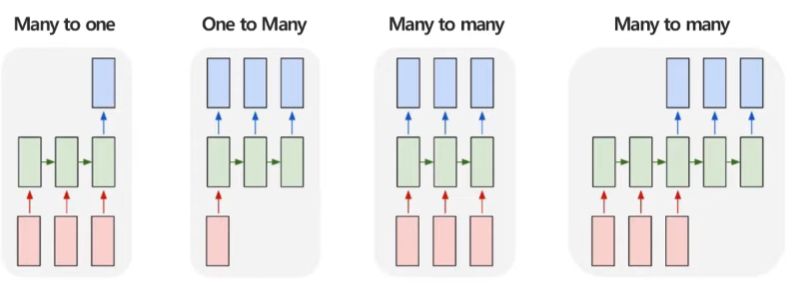
- `Many to one` 구조 : 여러 시점의 X로 하나의 Y를 에측하는 문제
- ex) 여러 시점에 다변량 센서 데이터가 주어졌을 때 특정 시점의 제품 상태를 예측
- `One to many` 구조 : 단일 시점 X로 순차적인 Y를 에측하는 문제
- ex) 이미지 데이터가 주어졌을 때, 이미지에 대한 정보를 글로 생성하는 이미지 캡셔닝
- `Many to many` 구조 : 순차적인 X로 순차적인 Y를 예측하는 문제
- ex) 문장이 주어졌을 때, 각 단어의 품사를 예측하는 `Part of sppech(POS) Tagging`
- `Encoder-Decoder` 구조(4번째 figure) → `Seq2Seq`
- ex) 영어 문장이 주어졌을 때, 한글문장으로 번역
Attention Mechanism(Seq2seq 구조의 한계점)
'I Love You'라는 영어 문장을 '나는 너를 사랑해'라는 한글 문장으로 번역하는 Encoder-Decoder 구조를 생각해보자. 여기서 Seq2seq의 한계점이 드러나는데, 각 단어('나는', '너를', '사랑해')를 예측할 시 더 중요하게 집중해야하는 Encoder 부분 단어가 다른데 Decoder가 단어를 예측할 때 Encoder의 마지막 시점 은닉층 정보를 나타내는 `context vector`만을 활용하기 때문에 이를 반영할 수 없다.
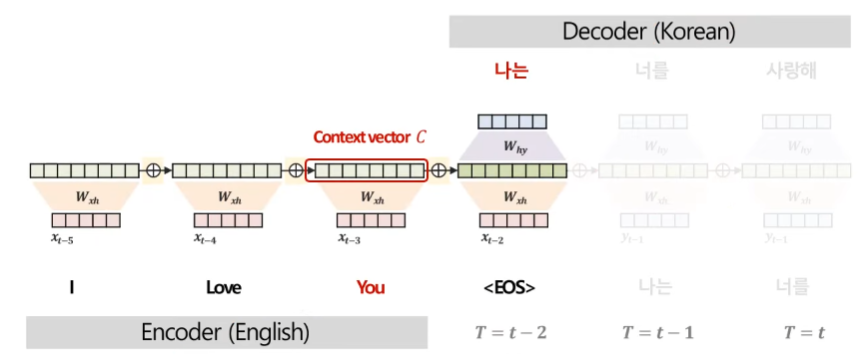
따라서 이를 해결하기 위해 Decoder에서 단어 예측 시 Encoder의 매 시점 정보를 참고하기 위해 Decoder의 매 시점마다 Context Vector를 다르게 만들고, 중요한 단어는 더 집중해서 봐야한다. 여기서 중요도는 곧 유사도를 의미하기 때문에, 이를 측정하기 위해서 다양한 방법이 있지만 대표적으로 내적을 활용한다. 먼저 Encoder와 Decoder의 각 시점 별 hidden state들의 내적 값을 계산한 후 softmax 함수를 활용해서 이를 확률 값으로 표현한다. 이를 통해 확률 값이 높은 시점의 데이터의 중요도가 더 높다고 판단한다. 해당 예시에서는 당연히 '나는'을 번역할 때 'I'가 가장 유사도가 높으면서 중요도가 높기 때문에 가장 높은 가중치 0.9가 생성되었다.
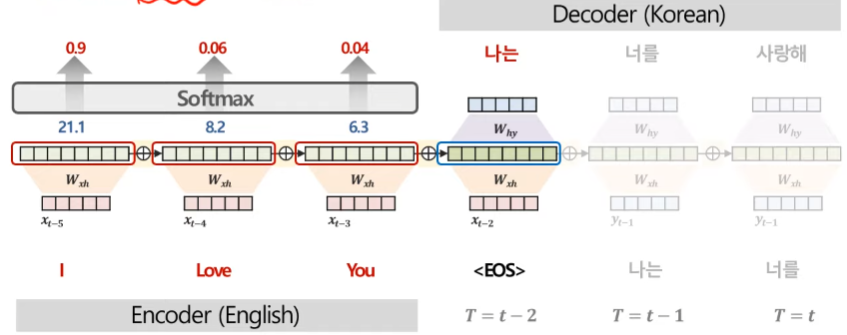
이후 Decoder의 '나는'이라는 문장을 번역하기 위해 Encoder의 'I', 'Love', 'You' 각 시점에 각각의 확률 값을 가중치로 활용하여 Decoder의 매 시점마다 새로운 Context Vector를 생성한다. 이는 가중치 없이 'I', 'Love', 'You'를 모두 활용해서 Context Vector를 생성하는 Seq2seq와 차이가 있다. 여기서 가중치가 바로 `Attention score`이다. 이 Attention score를 통해 각 시점마다 Attention mechanism 과정에서 어디가 중요한지를 도출해낼 수 있다. 이를 통해 모델이 예측에 주요하게 집중한 부분을 정량적으로 해석할 수 있다. 특히 Attention mechanism은 각 관측치별 중요도를 도출 가능하므로 원인이자 규명을 명확히 할 수 있다.
이 포스팅은 고려대학교 산업경영공학부 김성범 교수님 유튜의 핵심 머신러닝 강의를 듣고 작성한 글입니다.
(이미지 출처 : 핵심 머신러닝)