분류 및 예측을 위한 모델
분류 및 예측을 위한 모델은 크게 2가지가 있다. 첫 번째는 `Model-based Learning`이다. 이는 데이터로부터 모델을 생성하여 분류 및 예측을 진행하는 것으로 선형/비선형모델(linear regression, logistic regression 등), Neural Network, 의사 결정 나무, Support Vector Machine 등을 예로 들 수 있다. 두 번째는 `Instance-based Learning`이다. 이는 별도의 모델 생성 없이 인접 데이터를 분류 및 예측에 사용하는 것을 말한다. 대표적인 예로는 K-nearest neighbor, Locally weighted regression 등이 있다.
Nearest neighbors


KNN 알고리즘의 구분 및 특징
- Instance-based Learning : 각각의 관측치(instance)만을 이용하여 새로운 데이터에 대한 예측을 진행
- Memory-based Learning : 모든 학습 데이터를 메모리에 저장한 후, 이를 바탕으로 예측 시도
- Lazy Learning : 모델을 별도로 학습하지 않고 test data가 들어와야 비로서 작동하는 게으른(lazy) 알고리즘
- KNN 알고리즘은 k 값에 따라 경계선의 형태가 조금 다르지만, 선형 모델과 다르게 비선형 상태로 결정 경계선이 나타남
- k : 가장 가까운 근접 이웃의 개수
- Y 값이 연속형, 범주형 상관없이 분류 및 예측에 모두 사용 가능
KNN 분류 알고리즘


KNN 분류 알고리즘은 새로운 데이터에 인접한 k개의 데이터로부터 `majority voting`을 시행한다. 위 그림에서 k=1일 경우 가장 인접한 데이터가 Orange 1개이기 때문에 새로운 데이터는 Orange로 분류하고, k=3일 경우 가장 인접한 3개의 데이터가 Orange 1개, Green 2개이므로 새로운 데이터를 Green으로 분류한다. KNN 분류 알고리즘을 정리하면 다음과 같다.
- 분류할 관측치 x를 선택
- x로부터 인접한 k개의 학습 데이터를 탐색
- 탐색된 k개 학습 데이터의 majority clas c를 정의
- c를 x의 분류결과로 반환
KNN 예측 알고리즘


KNN 예측 알고리즘은 가장 인접한 k개의 데이터를 확인한 후, 대표값을 취해 새로운 데이터의 값을 예측한다. 여기서 대표값으로는 평균이 가장 정확하다고 알려져있다. KNN 예측 알고리즘을 정리하면 다음과 같다.
- 예측할 관측치 x를 선택
- x로부터 인접한 k개의 학습 데이터를탐색
- 탐색된 k개 학습 데이터의 평균을 x의 예측 값으로 반환
KNN 하이퍼파라미터
KNN 알고리즘에는 설정해주어야하는 2가지의 하이퍼파라미터가 존재한다.
- k : 인접한 학습 데이터를 몇 개까지 탐색할 것인가?
- Distance Measures : 데이터 간 거리를 어떻게 측정할 것인가?
k에 따른 결과
KNN 알고리즘에서 k는 최소 1에서 전체 데이터의 개수까지 설정이 가능하다. 여기서 k가 매우 작을 경우에는 데이터의 지역적 특성을 지나치게 반영하여 `overfitting`의 위험이 있다. 반대로 k가 매우 클 경우에는 다른 범주의 개체를 너무 많이 포함하기 때문에 오분류하는 `underfitting`의 위험이 있다.

k 선택 방법
KNN 알고리즘에서 정해진 k를 선택하는 방법은 없다. 따라서 일정 범위 내로 k를 조정하여 가장 좋은 예측 결과를 보이는 k 값을 선정해야 한다. 분류 알고리즘과 예측 알고리즘에서의 에러 측정 방법은 다음과 같다. 이를 통하여 에러가 가장 작은 k 값을 선택하면 된다.

거리 측도(Distance measure)
현재 다양한 `거리 측도(Distance measure)` 방법이 존재하며, 이는 (1-유사도)라고도 표현이 가능하다. 데이터 내 변수들이 각기 다른 데이터 범위, 분산 등을 가질 수 있기 때문에 데이터 정규화 혹은 표준화를 통해 이를 맞추는 것이 중요하다.
Euclidean Distance
`Euclidean Distance`는 가장 흔히 사용하는 거리측도 방법으로, 대응되는 X,Y 값 간 차이 제곱합의 제곱근으로써 두 관측치 사이의 최단 직선 거리를 의미한다.

Manhattan Distance(Taxi cab Distance)
`Manhattan Distance`는 X에서 Y로 이동 시 각 좌표축 방향으로만 이동할 경우에 계산되는 거리를 말한다. 이를 수식으로 나타내면 다음과 같다. Manhattan Distance 의 값은 항상 Euclidean Distance의 값보다 크거나 같다.

Manhattan Distance와 Euclidean Distance를 비교하면 다음과 같다.

Mahalanobis Distance
`Mahalanobis Distance`는 변수 낸 분산, 변수 간 공분산을 모두 반영하여 X, Y 간 거리를 계산하는 방식이다. 이는 Euclidean Distance 값에 covariance matrix의 역행렬을 곱해준 형태인데, 여기서 covariance matrix가 identity matrix인 경우에는 Euclidean Distance와 동일해진다.

여기서 Mahalanobis Distance의 제곱 값은 타원이 된다. Mahalanobis Distance 값을 c라고 하면, 다음과 같이 c의 값에 따라 타원의 크기가 커지는데 타원 위에 있는 점들은 모두 같은 Mahalanobis Distance 값을 가진다.

Mahalanobis Distance는 Euclidean Distance와 다른 개념을 가지는 것을 다음 그림을 통해 확인할 수 있다. Euclidean Distance 값을 기준으로 보면 A가 원점에서부터 B보다 먼 것을 확인할 수 있는데, X1과 X2는 서로 높은 상관관계를 보이고 있기 때문에 이를 고려한 Mahalanobis Distance를 기준으로는 X1과 X2의 상관관계를 반하는 B의 거리가 더 멀게 된다.


Correlation Distance
`Correlation Distance`는 데이터 각 Pearson correlation을 거리측도로 사용하는 방식으로 데이터 패턴의 유사도를 반영할 수 있다. 이러한 Correlation Distance는 전반적인 패턴을 봐야하는 signal, spectral, profile의 형태의 데이터에 많이 사용된다.

Spearman Rank Correlation Distance
`Spearman Rank Correlation Distance`는 데이터의 순위(rank)를 이용하여 correlation distance를 계산하는 방식이다.

수식으로 보면 어렵지만, 이를 예시로 확인하면 쉽다.

KNN의 장점과 한계점
장점
- 데이터 내 노이즈에 영향을 크게 받지 않으며, 특히 Mahalanobis Distance와 같이 데이터의 분산을 고려할 경우 강건함
- 학습 데이터의 수가 많을 경우 효과적임
한계점
- 파라미터 k의 값을 설정해야 함
- 어떤 거리 척도가 분석에 적합한 지 불분명하며, 따라서 데이터의 특성에 맞는 거리측도를 임의로 선정해야 함
- 새로운 관측치와 각각의 학습 데이터 간 거리를 전부 측정해야 하므로 계산시간이 오래 걸림
- 고차원의 데이터에선 성능이 좋지 못함
Weighted KNN
`Weighted KNN`은 새로운 데이터와 기존 학습 관측치 간의 거리에 따라 가중치를 다루게 주어 예측 혹은 분류를 수행하는 알고리즘을 말한다. 이를 통해 기존에 KNN 알고리즘보다 좀 더 공평한 예측 및 분류가 가능하다.
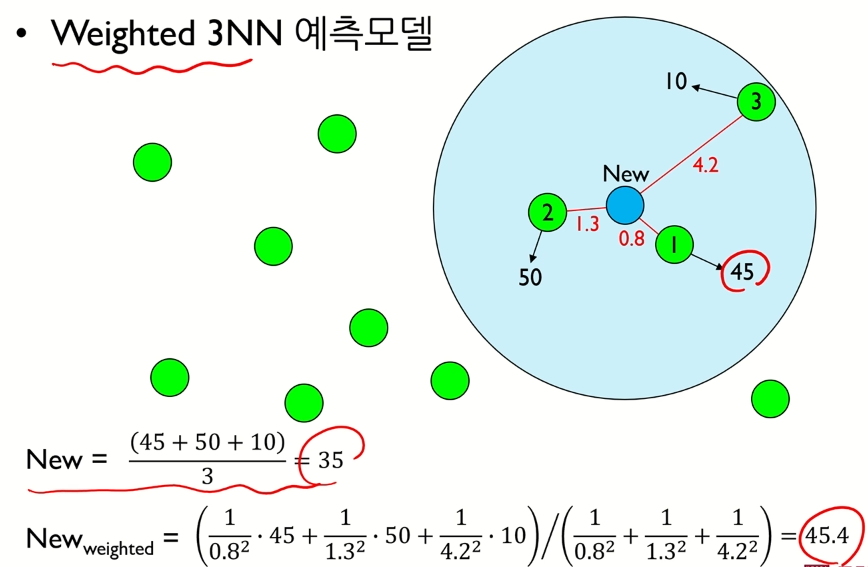

예측 알고리즘과 분류 알고리즘의 결과 도출 식은 다음과 같다.


이 글은 고려대학교 산업경영공학부 김성범 교수님 유튜브의 '핵심 머신러닝' 강의를 듣고 작성한 글입니다.
(이미지 출처 - 핵심 머신러닝 강의자료)