변수 사이의 관계
X변수(원인)과 Y변수(결과) 사이의 관계는 두가지가 있으며, 머신러닝 및 데이터 마이닝에서는 확률적 관계를 다룬다.
- 확정적 관계 : X변수만으로 Y를 100% 표현(오차항 없음) ex> 힘 = f(질량, 가속도), 주행거리 = f(속도, 시간)
- 확률적 관계 : X변수와 오차항이 Y를 표현(오차항 있음) ex> 반도체 수율 = f(설비 파라미터들의 상태, 온도, 습도) + 오차항
선형 회귀 모델
선형 회귀 모델이란 출력변수 Y를 입력변수 X들의 선형 결합으로 표현한 모델을 말한다. 여기서 선형 결합은 변수들을 (상수배와) 더하기 빼기를 통해 결합한 것을 의미한다. 만약 X 변수 1개가 Y를 표현하는 경우는 다음과 같다.
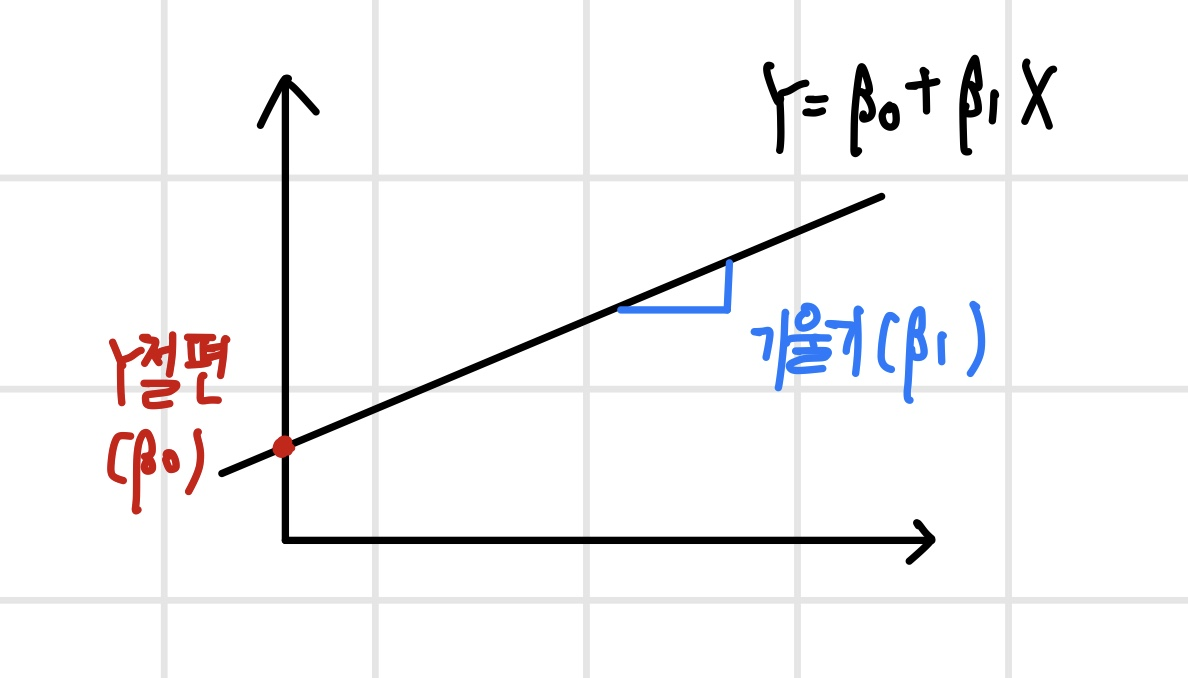
선형 회귀 모델링의 목적은 두 가지가 있다.
- X 변수와 Y 변수 사이의 관계를 수치로 설명
- 미래의 반응변수 (Y) 값을 예측
선형 회귀 모델의 분류는 다음과 같다.
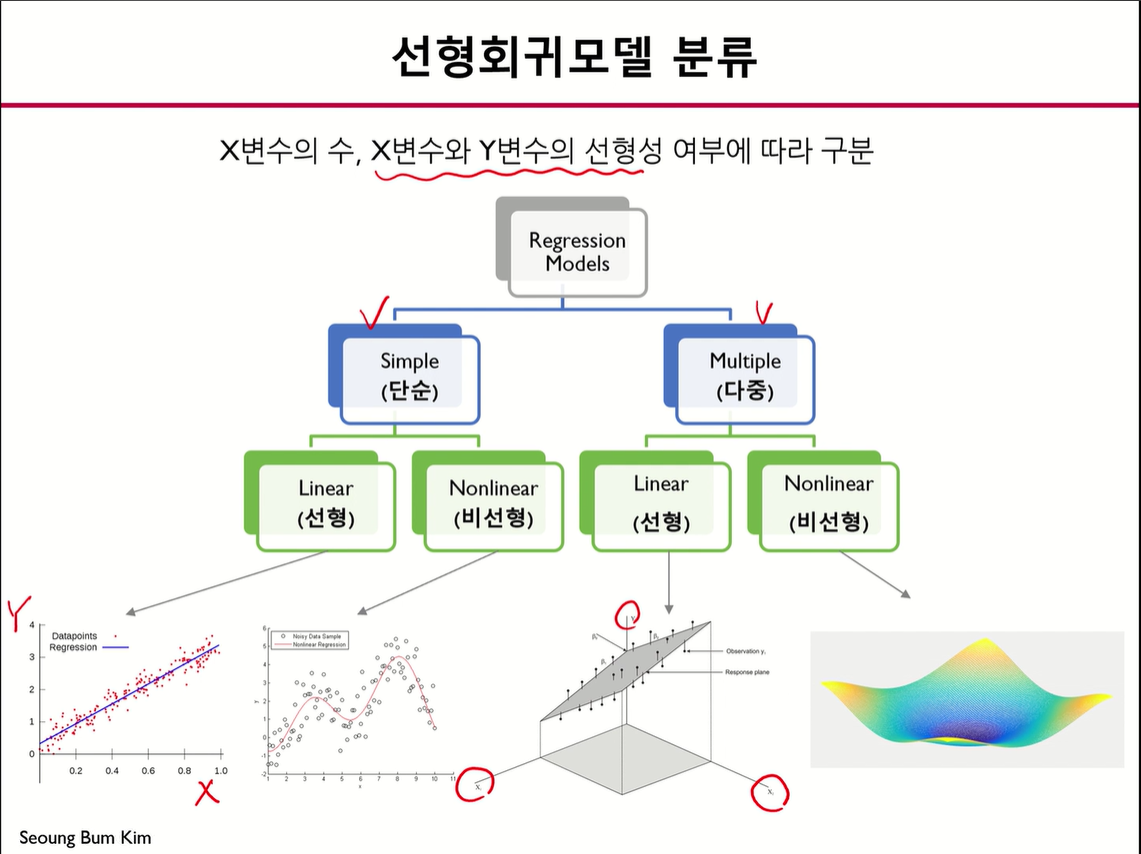
선형 회귀 모델 가정
선형 회귀 모델에서 Y는 X로부터 설명되는 부분과 그렇지 않은 부분으로 구성된다.
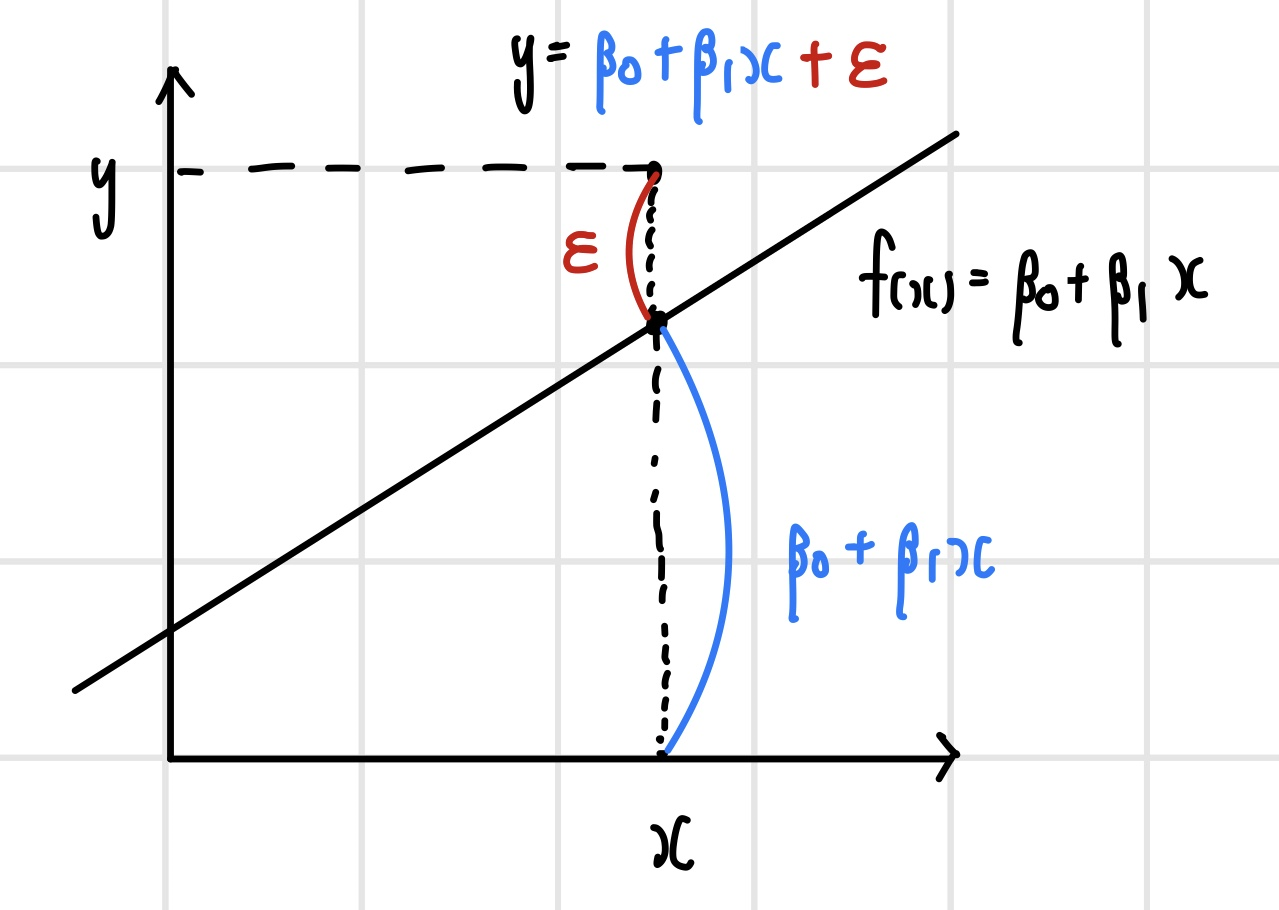
선형 회귀 모델을 구축하는 데에는 오차항의 가정이 필요하다. 해당 가정을 만족하지 못할 경우, 모델은 구축될 수 있지만 해당 모델은 신뢰할 수 없는 모델이 된다.
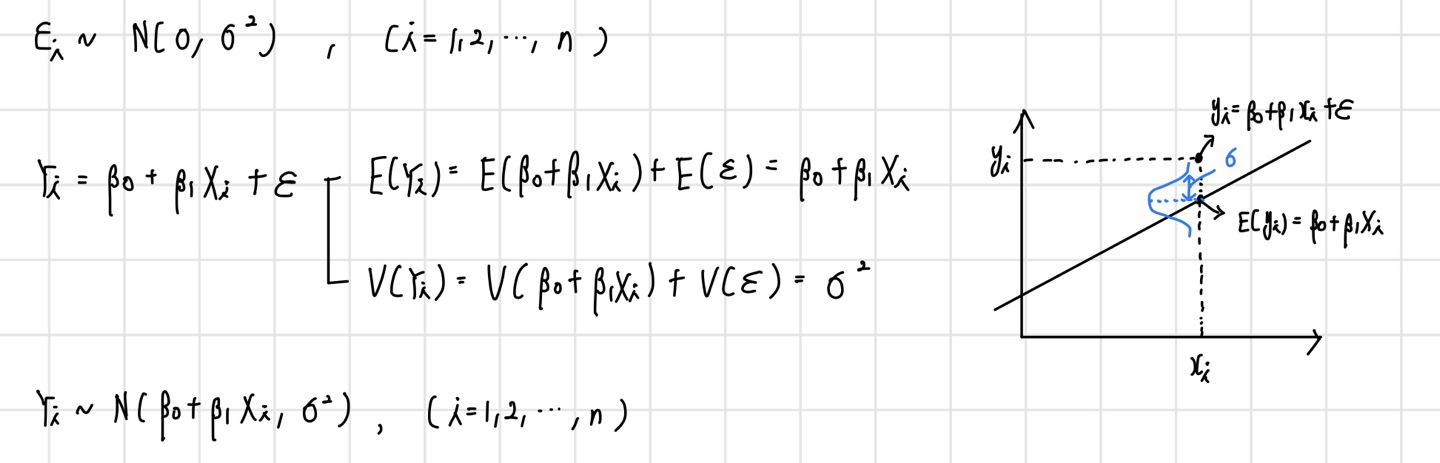
오차항이 정규분포를 따르는 확률변수이기 때문에 이를 포함하는 Y 또한 확률변수가 되며 정규분포를 따르게 된다. 결론적으로 선형 회귀 모델이란 입력변수(X)와 출력변수(Y)의 평균과의 관계를 설명하는 선형식을 찾는 것이다.
파라미터 추정
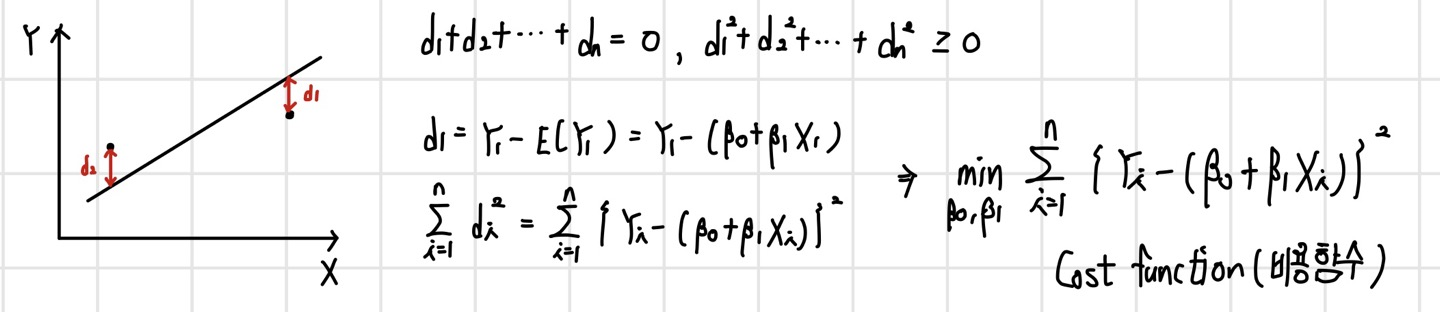
파라미터를 추정하는 것은 결국 Cost function을 최소화하는 B0와 B1을 찾는 과정이다. 비용 함수를 최소화하기 위한 최적의 파라미터를 알고리즘을 통해 찾고, 이를 통해 식을 도출해내는 과정이 모델링(Modeling) 과정이다.

파라미터 추정 알고리즘
선형 회귀 모델의 비용 함수는 convex 함수이기 때문에 전역 최적해가 존재하여 비교적 파라미터 추정이 쉽다. 각 점마다 편미분을 통해 기울기가 0이 되는 지점을 찾는다.
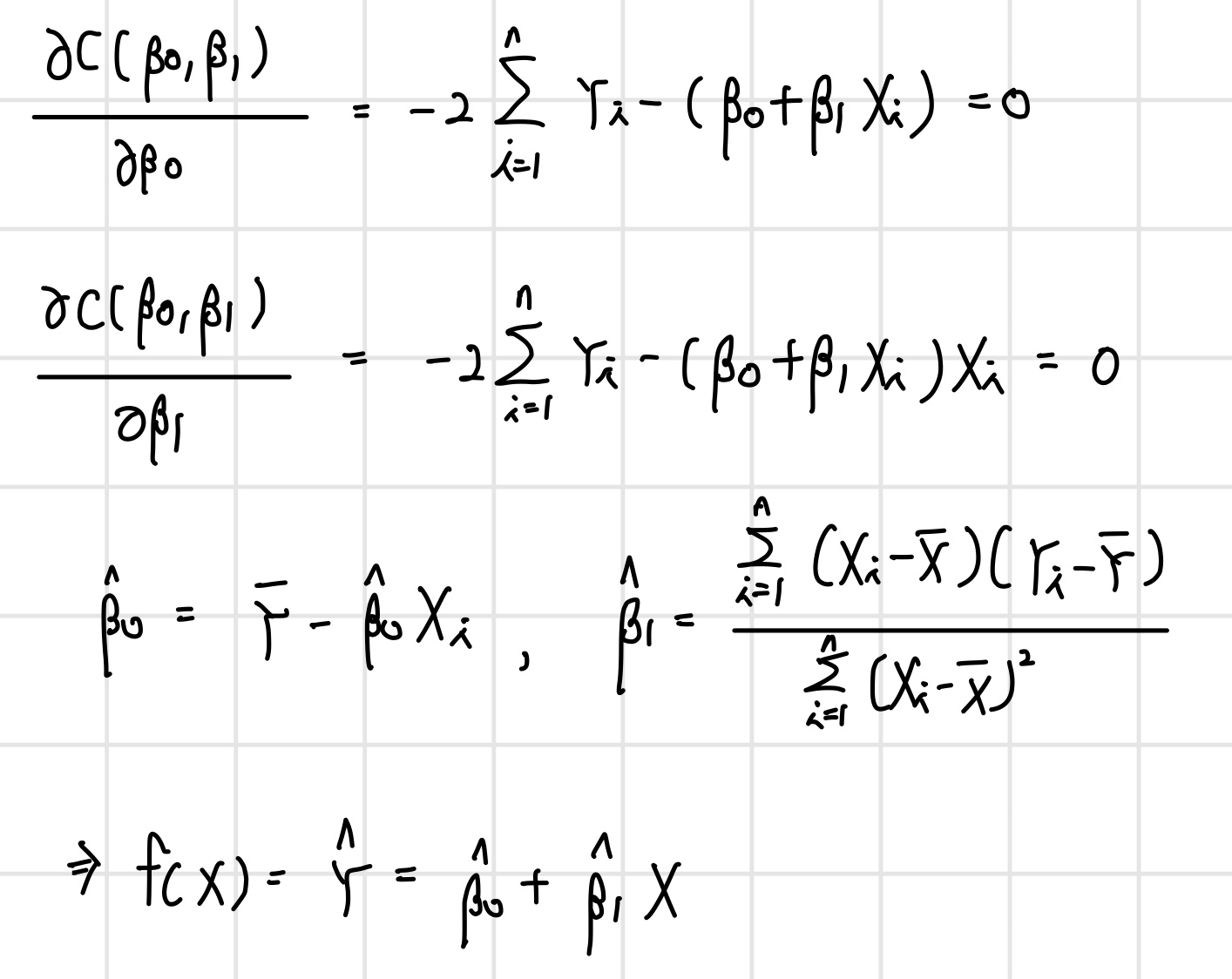
선형 회귀 모델의 파라미터 추정 알고리즘
앞서 살펴본 선형 회귀 모델의 파라미터를 추정하는 알고리즘을 최소제곱법(Least Squares Estimation)이라고 한다. 이 과정을 요약하면 다음과 같다.

잔차(Residual)
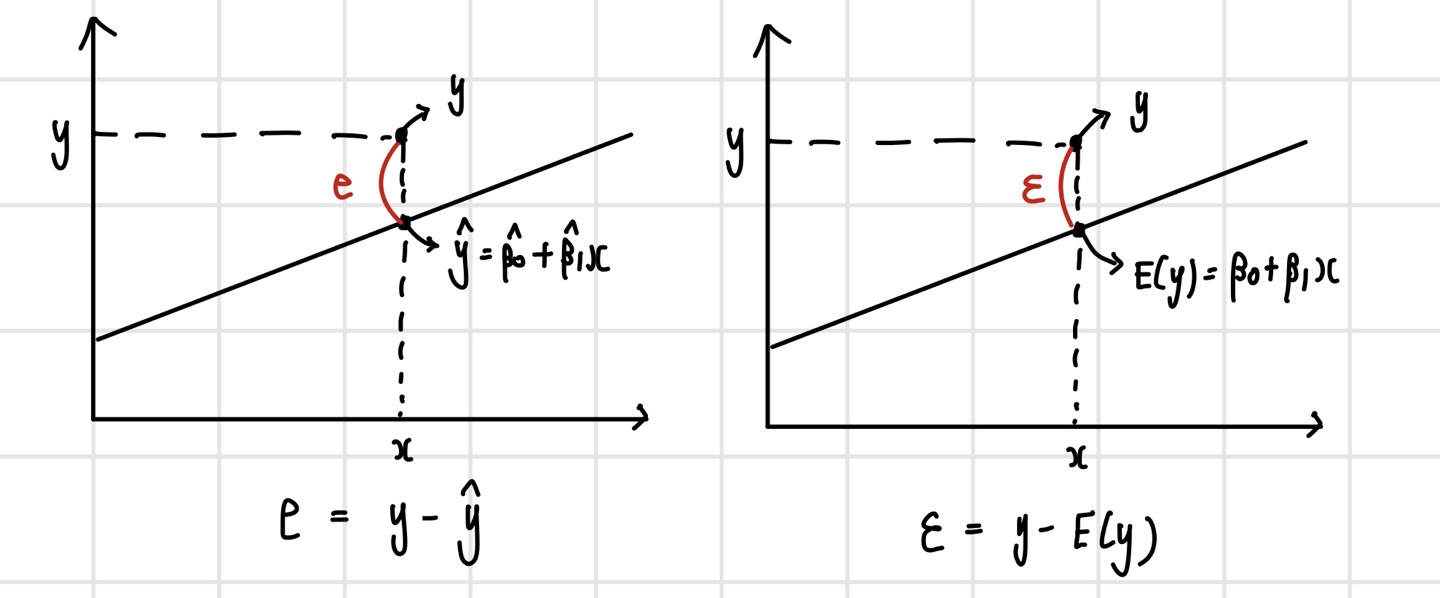
잔차(Residual)란, 최소제곱법을 통해 구해진 직선 위의 점과 실제 y값과의 차이를 의미한다. 이는 이전에 본 확률 오차, 즉 X로 설명할 수 없는 부분을 뜻하는 오차항과는 다른 개념이다. 확률 오차의 경우 아직 확정되지 않은 직선에서의 오차를 의미하기 때문에 확률 분포를 따르게 되며, B0와 B1은 파라미터의 상태이다. 여기에 잔차는 확률 오차가 실제로 구현된 값이라고 할 수 있다. 향후 확률 오차의 패턴에 관해 분석하는 경우가 있는데, 이 때 확률 오차를 활용할 수 없기 때문에 잔차를 활용한다.
파라미터에 대한 점추정(Point Estimator)
이렇게 구한 B0와 B1은 추정량(Estimator)이라고 부른다. 추정량이란, 데이터의 함수로 알려지지 않은 파라미터를 추정하는데 사용된다. 이러한 추정량의 종류로는 점추정(point estimator)과 구간추정(interval estimator)이 있다. 먼저, 점추정은 알려지지 않은 파라미터를 하나의 값으로 추정하는 것을 말하며, 이 앞서 선형 회귀 모델에서 살펴보았다.

최소제곱법 추정량 성질
Gauss-Markov Theorem : Least square estimator is the best linear unbiased estimator(BLUE)
- unbiased estimator
- has the smallest average squared error(variance) compared to any unbiased estimators

파라미터에 대한 구간추정(interval estimator)
구간추정이란, 알려지지 않은 파라미터를 하나의 값이 아닌 구간으로 추정하는 것으로, 점추정보다 유연한 정보를 제공한다. 파라미터에 대한 구간추정의 기본 형태는 다음과 같다.

즉, 구간추정이란 점추정으로 구한 값에 상수값과 표준편차를 곱한 값을 더하고 뺀 값을 upper bound 및 lower bound로 정의한 것이다.
기울기에 대한 신뢰구간
선형 회귀 모델에서 기울기에 대한 신뢰 구간은 다음과 같다. 참고로, 선형 회귀 모델에서 y절편에 대한 신뢰구간은 중요한 의미를 갖지는 않는다.

기울기에 대한 가설검정
파라미터에 대한 추론은 총 두 가지가 있다. 첫 번째는 위에서 본 추정이며, 두 번째는 알려지지 않은 파라미터에 대한 가설을 세우고 이를 검정하는 가설검정이다. 선형 회귀 모델에서 기울기에 대한 가설검정은 다음과 같다.

선형회귀 모델 예제
회귀 방정식이 y(집 가격) = -29.6 + 0.0779*Area(집 크기)일 때의 선형 회귀 모델의 분석 결과가 다음과 같을 때, 이를 해석해보면 다음과 같다.
| Predictor | Coef | SE Coef | T | P | |
| Constant | -29.59 | 10.66 | -2.78 | 0.016 | S = 16.9065 |
| Area | 0.077939 | 0.004370 | 17.83 | 0.000 |
- parameter : B0(Constant)와 B1(Area)
- 점 추정값(point estimates) : -29.59, 0.077939
- estimator는 function을 의미하며, estimate는 해당 function을 통해 나온 값을 의미
- standard deviation(standard error) : 10.66, 0.004370
- T : 검정통계량으로 17.83
- P : P-value
- T 값의 절댓값이 17.83보다 클 확률이 자유도가 13(15-2)인 t 분포에서 0
- 기울기(B1)가 0이라는 귀무가설을 기각하므로, 집 크기(X)는 집 가격(Y)에 유의미한 영향
- S : 오차항에 대한 표준편차 값의 추정 값으로 16.9065
결정계수(Coefficient of Determination : R2)
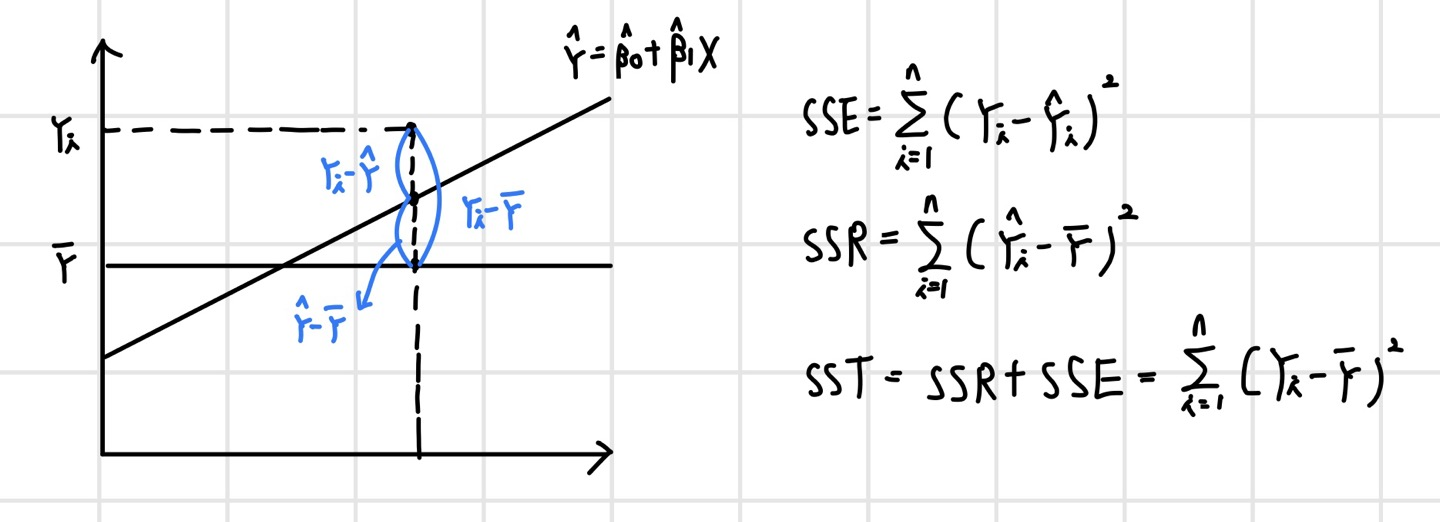
Y의 평균값을 기준으로 보면, SSR은 우리가 가지고 있는 X를 통해 얼마만큼 설명할 수 있는지, SSE는 X로는 설명할 수 없는 부분을 나타낸다. SSR과 SST를 통해 결정계수(Coefficient of Determination)를 정의할 수 있다.
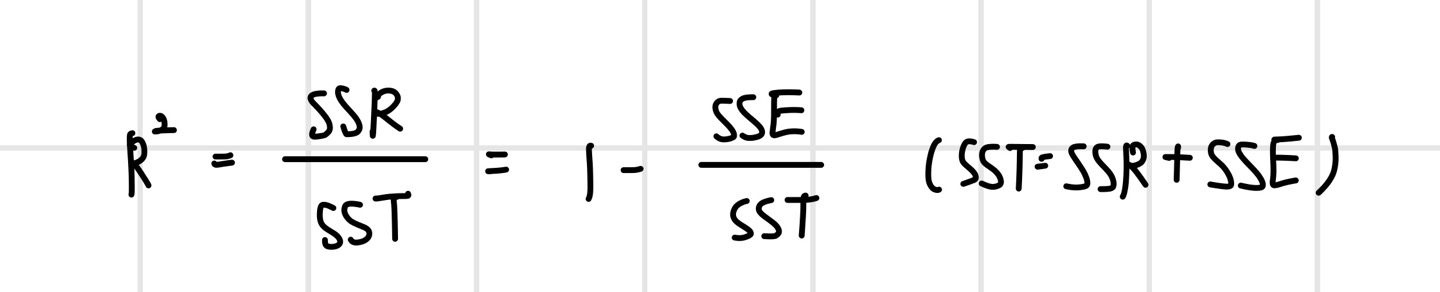
- 결정계수는 0과 1 사이에 존재
- R^2=1 : 현재 가지고 있는 X변수로 Y를 100% 설명한다는 의미로, 모든 관측치가 회귀 직선 위에 있음
- R^2=0 : 현재 가지고 있는 X변수는 Y를 설명(예측)하는 데 전혀 도움이 되지 않음
- 사용하고 있는 X변수가 Y변수의 분산을 얼마나 줄였는지의 정도
- 단순히 Y의 평균 값을 사용했을 때 대비 X 정보를 사용함으로써 얻는 성능향상 정도
- 사용하고 있는 X변수의 품질
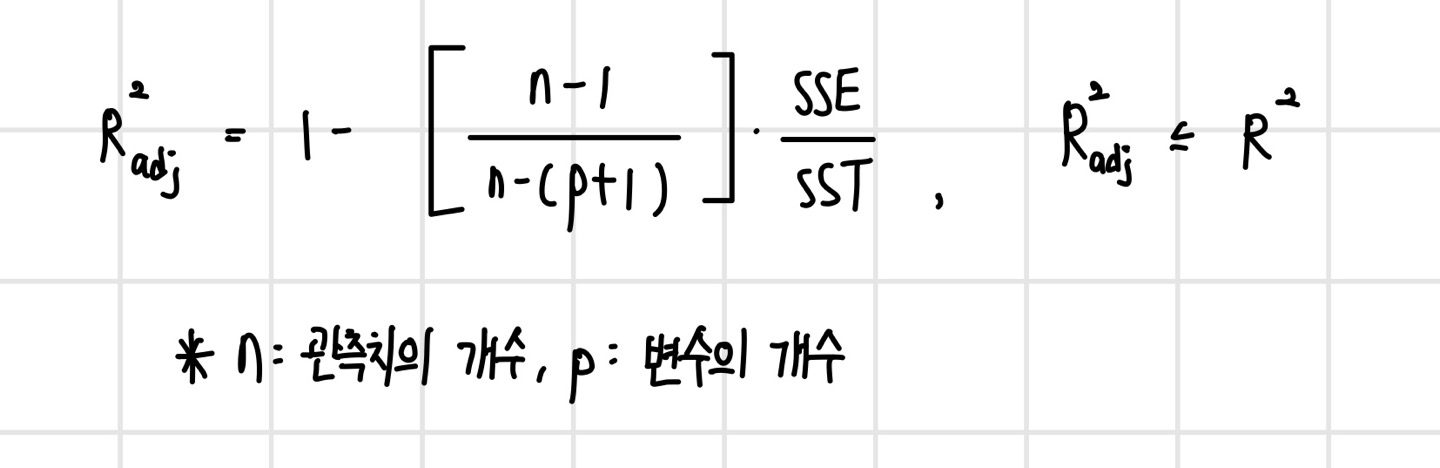
그러나 이러한 결정계수는 한 가지 문제점이 있다. 이는 유의하지 않은 변수가 추가되어도 결정계수 값은 항상 증가한다는 것이다. 이를 보정하기 위해 수정 결정계수(Adusted R^2)가 존재한다. 이는 결정계수에 특정 계수를 곱해 줌으로써(보정) 유의하지 않은 변수가 추가될 경우 증가하지 않도록 한다. 이러한 수정 결정계수는 설명변수가 서로 다른 회귀 모형의 설명력을 비교할 때 사용한다.
선형 회귀 모델에서의 분산분석
분산분석(Analysis of Variance, ANOVA)은 분산 정보를 이용하여 분석하는 것을 말한다. 분산분석은 궁극적으로 가설검정을 행하는 용도로 사용된다. 앞서 정의한 SST는 Y의 총 변동량, SSR은 X변수에 의해 설명된 양, SSE는 에러에 의해 설명된 양이라고 정의할 수 있는데, 이는 모두 분산과 연관되어 있다.
분산분석을 위해 새로운 분수 형태의 값(SSR/SSE)을 정의한다. 이 값이 1보다 큰 경우와 0부터 1 사이의 값일 경우 각각의 의미는 다음과 같다.

그렇다면 이 값이 1보다 클 때 X변수가 Y변수를 설명(예측)하는 데 유의미한 영향을 끼치다고 하는데, 과연 이 값이 얼마나 커야 큰 값인지를 알기 위해선 해당 변수의 분포를 통해 확인할 수 있다. 그러나 현재까지 해당 값의 분포를 직접적으로 정의할 수는 없다. 하지만 SSR과 SSE가 각각 카이제곱 분포를 따른다는 점을 통해 SSR과 SSE의 비율이 어떤 분포를 따르는지 간접적으로 확인할 수 있다.

이에 대한 ANOVA 테이블은 다음과 같다.
| Source | DF | SS | MS | F | P |
| Model | 1 | SSR | MSR | F* | P-value |
| Error | n-2 | SSE | MSE | ||
| Total | n-1 | SST |
앞서 분산분석은 가설 검정에 이용한다 하였다. 이러한 가설 검정은 다음과 같이 이루어진다.
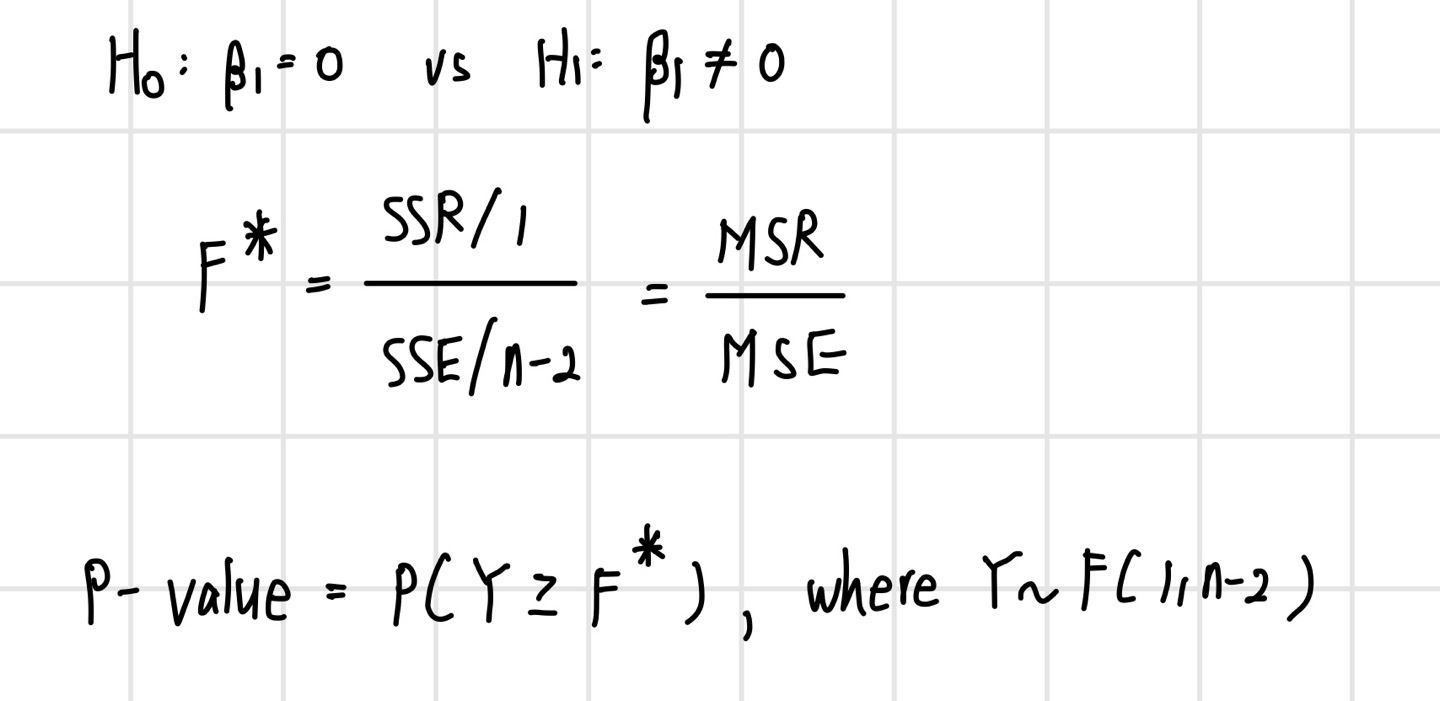
여기서 F* 값이 클 경우 SSR 값이 SSE 값보다 훨씬 크다는 것을 의미하며, 이 경우 B1=0이라는 귀무가설을 기각하게 된다. P-value의 관점에서도 F* 값이 클 경우 P-value 값은 0에 가까워지기 때문에 이 또한 귀무가설을 기각한다.
이 포스팅은 고려대학교 산업경영공학부 김성범 교수님 유튜브의 핵심 머신러닝 강의를 듣고 작성한 글입니다.
(이미지 출처 : 핵심 머신러닝)
변수 사이의 관계
X변수(원인)과 Y변수(결과) 사이의 관계는 두가지가 있으며, 머신러닝 및 데이터 마이닝에서는 확률적 관계를 다룬다.
- 확정적 관계 : X변수만으로 Y를 100% 표현(오차항 없음) ex> 힘 = f(질량, 가속도), 주행거리 = f(속도, 시간)
- 확률적 관계 : X변수와 오차항이 Y를 표현(오차항 있음) ex> 반도체 수율 = f(설비 파라미터들의 상태, 온도, 습도) + 오차항
선형 회귀 모델
선형 회귀 모델이란 출력변수 Y를 입력변수 X들의 선형 결합으로 표현한 모델을 말한다. 여기서 선형 결합은 변수들을 (상수배와) 더하기 빼기를 통해 결합한 것을 의미한다. 만약 X 변수 1개가 Y를 표현하는 경우는 다음과 같다.
선형 회귀 모델링의 목적은 두 가지가 있다.
- X 변수와 Y 변수 사이의 관계를 수치로 설명
- 미래의 반응변수 (Y) 값을 예측
선형 회귀 모델의 분류는 다음과 같다.
선형 회귀 모델 가정
선형 회귀 모델에서 Y는 X로부터 설명되는 부분과 그렇지 않은 부분으로 구성된다.
선형 회귀 모델을 구축하는 데에는 오차항의 가정이 필요하다. 해당 가정을 만족하지 못할 경우, 모델은 구축될 수 있지만 해당 모델은 신뢰할 수 없는 모델이 된다.
오차항이 정규분포를 따르는 확률변수이기 때문에 이를 포함하는 Y 또한 확률변수가 되며 정규분포를 따르게 된다. 결론적으로 선형 회귀 모델이란 입력변수(X)와 출력변수(Y)의 평균과의 관계를 설명하는 선형식을 찾는 것이다.
파라미터 추정
파라미터를 추정하는 것은 결국 Cost function을 최소화하는 B0와 B1을 찾는 과정이다. 비용 함수를 최소화하기 위한 최적의 파라미터를 알고리즘을 통해 찾고, 이를 통해 식을 도출해내는 과정이 모델링(Modeling) 과정이다.
파라미터 추정 알고리즘
선형 회귀 모델의 비용 함수는 convex 함수이기 때문에 전역 최적해가 존재하여 비교적 파라미터 추정이 쉽다. 각 점마다 편미분을 통해 기울기가 0이 되는 지점을 찾는다.
선형 회귀 모델의 파라미터 추정 알고리즘
앞서 살펴본 선형 회귀 모델의 파라미터를 추정하는 알고리즘을 최소제곱법(Least Squares Estimation)이라고 한다. 이 과정을 요약하면 다음과 같다.
잔차(Residual)
잔차(Residual)란, 최소제곱법을 통해 구해진 직선 위의 점과 실제 y값과의 차이를 의미한다. 이는 이전에 본 확률 오차, 즉 X로 설명할 수 없는 부분을 뜻하는 오차항과는 다른 개념이다. 확률 오차의 경우 아직 확정되지 않은 직선에서의 오차를 의미하기 때문에 확률 분포를 따르게 되며, B0와 B1은 파라미터의 상태이다. 여기에 잔차는 확률 오차가 실제로 구현된 값이라고 할 수 있다. 향후 확률 오차의 패턴에 관해 분석하는 경우가 있는데, 이 때 확률 오차를 활용할 수 없기 때문에 잔차를 활용한다.
파라미터에 대한 점추정(Point Estimator)
이렇게 구한 B0와 B1은 추정량(Estimator)이라고 부른다. 추정량이란, 데이터의 함수로 알려지지 않은 파라미터를 추정하는데 사용된다. 이러한 추정량의 종류로는 점추정(point estimator)과 구간추정(interval estimator)이 있다. 먼저, 점추정은 알려지지 않은 파라미터를 하나의 값으로 추정하는 것을 말하며, 이 앞서 선형 회귀 모델에서 살펴보았다.
최소제곱법 추정량 성질
Gauss-Markov Theorem : Least square estimator is the best linear unbiased estimator(BLUE)
- unbiased estimator
- has the smallest average squared error(variance) compared to any unbiased estimators
파라미터에 대한 구간추정(interval estimator)
구간추정이란, 알려지지 않은 파라미터를 하나의 값이 아닌 구간으로 추정하는 것으로, 점추정보다 유연한 정보를 제공한다. 파라미터에 대한 구간추정의 기본 형태는 다음과 같다.
즉, 구간추정이란 점추정으로 구한 값에 상수값과 표준편차를 곱한 값을 더하고 뺀 값을 upper bound 및 lower bound로 정의한 것이다.
기울기에 대한 신뢰구간
선형 회귀 모델에서 기울기에 대한 신뢰 구간은 다음과 같다. 참고로, 선형 회귀 모델에서 y절편에 대한 신뢰구간은 중요한 의미를 갖지는 않는다.
기울기에 대한 가설검정
파라미터에 대한 추론은 총 두 가지가 있다. 첫 번째는 위에서 본 추정이며, 두 번째는 알려지지 않은 파라미터에 대한 가설을 세우고 이를 검정하는 가설검정이다. 선형 회귀 모델에서 기울기에 대한 가설검정은 다음과 같다.
선형회귀 모델 예제
회귀 방정식이 y(집 가격) = -29.6 + 0.0779*Area(집 크기)일 때의 선형 회귀 모델의 분석 결과가 다음과 같을 때, 이를 해석해보면 다음과 같다.
| Predictor | Coef | SE Coef | T | P | |
| Constant | -29.59 | 10.66 | -2.78 | 0.016 | S = 16.9065 |
| Area | 0.077939 | 0.004370 | 17.83 | 0.000 |
- parameter : B0(Constant)와 B1(Area)
- 점 추정값(point estimates) : -29.59, 0.077939
- estimator는 function을 의미하며, estimate는 해당 function을 통해 나온 값을 의미
- standard deviation(standard error) : 10.66, 0.004370
- T : 검정통계량으로 17.83
- P : P-value
- T 값의 절댓값이 17.83보다 클 확률이 자유도가 13(15-2)인 t 분포에서 0
- 기울기(B1)가 0이라는 귀무가설을 기각하므로, 집 크기(X)는 집 가격(Y)에 유의미한 영향
- S : 오차항에 대한 표준편차 값의 추정 값으로 16.9065
결정계수(Coefficient of Determination : R2)
Y의 평균값을 기준으로 보면, SSR은 우리가 가지고 있는 X를 통해 얼마만큼 설명할 수 있는지, SSE는 X로는 설명할 수 없는 부분을 나타낸다. SSR과 SST를 통해 결정계수(Coefficient of Determination)를 정의할 수 있다.
- 결정계수는 0과 1 사이에 존재
- R^2=1 : 현재 가지고 있는 X변수로 Y를 100% 설명한다는 의미로, 모든 관측치가 회귀 직선 위에 있음
- R^2=0 : 현재 가지고 있는 X변수는 Y를 설명(예측)하는 데 전혀 도움이 되지 않음
- 사용하고 있는 X변수가 Y변수의 분산을 얼마나 줄였는지의 정도
- 단순히 Y의 평균 값을 사용했을 때 대비 X 정보를 사용함으로써 얻는 성능향상 정도
- 사용하고 있는 X변수의 품질
그러나 이러한 결정계수는 한 가지 문제점이 있다. 이는 유의하지 않은 변수가 추가되어도 결정계수 값은 항상 증가한다는 것이다. 이를 보정하기 위해 수정 결정계수(Adusted R^2)가 존재한다. 이는 결정계수에 특정 계수를 곱해 줌으로써(보정) 유의하지 않은 변수가 추가될 경우 증가하지 않도록 한다. 이러한 수정 결정계수는 설명변수가 서로 다른 회귀 모형의 설명력을 비교할 때 사용한다.
선형 회귀 모델에서의 분산분석
분산분석(Analysis of Variance, ANOVA)은 분산 정보를 이용하여 분석하는 것을 말한다. 분산분석은 궁극적으로 가설검정을 행하는 용도로 사용된다. 앞서 정의한 SST는 Y의 총 변동량, SSR은 X변수에 의해 설명된 양, SSE는 에러에 의해 설명된 양이라고 정의할 수 있는데, 이는 모두 분산과 연관되어 있다.
분산분석을 위해 새로운 분수 형태의 값(SSR/SSE)을 정의한다. 이 값이 1보다 큰 경우와 0부터 1 사이의 값일 경우 각각의 의미는 다음과 같다.
그렇다면 이 값이 1보다 클 때 X변수가 Y변수를 설명(예측)하는 데 유의미한 영향을 끼치다고 하는데, 과연 이 값이 얼마나 커야 큰 값인지를 알기 위해선 해당 변수의 분포를 통해 확인할 수 있다. 그러나 현재까지 해당 값의 분포를 직접적으로 정의할 수는 없다. 하지만 SSR과 SSE가 각각 카이제곱 분포를 따른다는 점을 통해 SSR과 SSE의 비율이 어떤 분포를 따르는지 간접적으로 확인할 수 있다.
이에 대한 ANOVA 테이블은 다음과 같다.
| Source | DF | SS | MS | F | P |
| Model | 1 | SSR | MSR | F* | P-value |
| Error | n-2 | SSE | MSE | ||
| Total | n-1 | SST |
앞서 분산분석은 가설 검정에 이용한다 하였다. 이러한 가설 검정은 다음과 같이 이루어진다.
여기서 F* 값이 클 경우 SSR 값이 SSE 값보다 훨씬 크다는 것을 의미하며, 이 경우 B1=0이라는 귀무가설을 기각하게 된다. P-value의 관점에서도 F* 값이 클 경우 P-value 값은 0에 가까워지기 때문에 이 또한 귀무가설을 기각한다.
이 포스팅은 고려대학교 산업경영공학부 김성범 교수님 유튜브의 핵심 머신러닝 강의를 듣고 작성한 글입니다.
(이미지 출처 : 핵심 머신러닝)