Definition of Active Learning
Active Learning의 핵심 개념은 모델이 배우고 싶은, 호기심이 가는 데이터를 선택하여 적은 학습으로도 좋은 성과를 내게 한다는 것이다.- Active Learning은 annotation effort를 줄일 수 있는 지도학습 방법이다.
- Concepts of Active Learning
- 현실에서는 레이블이 되어있는 데이터가 부족하며, 별도로 이를 구하기 위해선 시간과 비용이 발생한다.
- Unlabeled Pool에서 사전 학습된 모델이
Inference를 통해 annotation 작업을 수행한다.- 하지만 사전 학습된 모델은 적은 데이터로 학습했기 때문에 성능이 낮으며, annotation의 품질을 보장할 수 없다.
- 모델이
uncertain한 데이터의 경우, 인간(annotator)에게query를 통해 labeling을 요청한다. - annotator가 다시 labeling한 데이터를 모델이 재학습한다.
- 불확실한 데이터는 다시 query를 날려 labeling한 후 재학습을 반복한다.

- Active Learning의 핵심은 바로 "어떻게
uncertainty를 측정할 것인가"이다.- 이러한 방법으로는
Uncertainty Sampling,Query-By-Committee,Expected Model Change,Core-Set,Learning Loss등의 방법이 있다.
- 이러한 방법으로는
Query Strategies for Active Learning
Uncertainty Sampling
- 초기에 학습된 모델의 확신도가 가장 낮은 데이터부터 Query를 날려 라벨링을 하는 방법이다.
- Decision Boundary 근처에 있는 애매한 데이터들에 대해서 가장 먼저 labeling을 요청한다.
Least Confident: 모델이 예측한 각 클래스에 속할 확률 중 가장 높은 확률이 가장 낮은 데이터부터 labeling을 요청Margin Sampling: 모델이 예측한 각 클래스에 속할 확률 중 첫번째, 두번째 가장 높은 확률의 차이가 가장 적은 데이터부터 labeling을 요청Entropy Sampling: 모델이 예측한 각 클래스에 속할 확률 중Entropy가 가장 큰 데이터부터 labeling을 요청- 엔트로피 지수란, 확률 변수의 불확실성을 수치로 나타낸 것으로 무질서도에 대한 측정 지표이다.

엔트로피 지수 수식
- 엔트로피 지수란, 확률 변수의 불확실성을 수치로 나타낸 것으로 무질서도에 대한 측정 지표이다.
- 3가지의 Sampling 방법에 따라 Labeling을 요청하는 Query의 우선 순위가 변화할 수 있다.
- Uncertatinty Sampling이 가장 단순하며 성능도 나쁘지 않아 보편적으로 많이 사용된다.
Query-By-Committee(QBC)
- C개의 Committee(=Model)의 Disagreement 정도가 높은 데이터부터 라벨링을 하는 방법이다.
- Disagreement를 측정하는 방법에는 두가지가 있다.
Vote Entropy: 엔트로피 기반의 uncertainly sampling을 QBC로 일반화한 것으로 생각할 수 있다.
Kullback-Leibler divergence: 가장 정보량이 높은 쿼리는 라벨 분포 간의 평균적인 차이가 가장 큰 쿼리이다.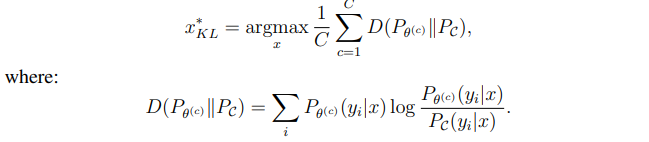
Expected Model Change
- 새로운 데이터 포인트에 대해 labeling을 했을 때 현재 모델을 가장 크게 변경시키는 데이터부터 labeling을 요청하는 방법이다.
Expected Gradient Length를 이용하며, 이론적으로 Gradient 기반의 학습을 진행하는 모든 모델에 적용이 가능하다.
- X 데이터가 주어졌을 때 y 클래스에 속할 확률과 새로운 데이터 x에 대한 Loss값과 기존 Loss 값의 합집합을 곱하는 형태이다.
- 학습을 통해 기존 Loss 값은 0에 가까워지기 때문에 objective function의 gradient 값은 새로운 데이터 x에 대한 Loss 값에 근사가 가능하다.
Core-Set
- 데이터를 뽑고, 반지름이 델타인 원을 그렸을 때 전체 데이터를 커버할 수 있으며 동시에 델타 값을 최소화시킬 수 있는 데이터 포인트들을 core-set으로 선정하여 우선적으로 labeling을 요청한다.
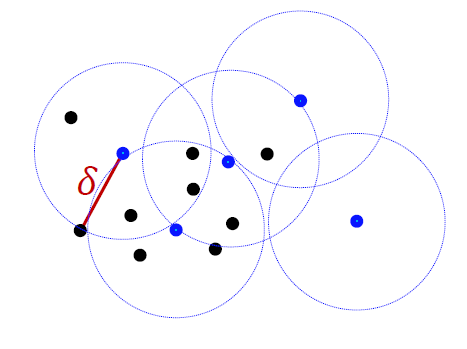
Learning Loss
- Loss prediction module을 추가하여 Loss에 대한 예측을 수행하고, Loss가 가장 클 것으로 에측되는 데이터에 대해서 우선적으로 labeling을 신청하는 방법이다.

- Target task loss 값은 학습 과정에서 지속적으로 감소하여 scale이 변하는 문제가 발생 -> MSE Loss 대신 Margin Ranking Loss를 사용한다.
- Learning Loss에 대해선 추가적으로 논문 리뷰를 진행해볼 예정이다.