[Paper Review] Time Series Forecasting With Deep Learning: A Survey(Philos Trans R Soc A 2020)
목차
`one-step-ahead`와 `multi-horizon time series` 모두에 사용하는 흔한 encoder와 decoder의 설계를 살펴보고, 각 모델에서 시간 정보가 예측에 통합되는 방식을 확인
잘 학습된 통계 모델과 neural network 구성 요소를 결합하여 두 분야 모두에서 기존 방법을 개선하는 `hybrid deep learning` 모델을 확인
딥러닝이 시계열 데이터의 의사 결정을 지원하는 방법을 촉진할 수 있는 몇 가지 방법도 간략히 소개
1. Introduction
시계열 모델링은 역사적으로 climate modeling, biological sciences, medicine, 유통 및 금융에서의 commercial decision making 등의 영역에서 주요한 연구 분야
전통적인 방법들은 `autoregressive(AR)`, `exponential smoothing`, `structural time series models` 등 도메인 전문 지식에 기반한 parametric 모델에 집중
최근 머신러닝 기반의 방법들은 순수하게 데이터 기반 방식으로 시간 역학을 학습하는 방식
deep neural network은 기본 데이터셋의 미묘한 차이를 반영하는 bespoke architectural assumptions 혹은 inductive biases를 통합하여 복잡한 데이터의 representations을 학습할 수 있기 때문에 수동적인 feature engineering과 model design의 필요성을 줄일 수 있음
본 논문에선 심층 신경망을 사용하여 시계열 데이터의 예측을 수행하는 모델들을 요약
`multi-horizon forecasting`, `uncertainty estimation`과 같은 일반적인 예측 문제에 사용할 수 있는 SOTA 모델
예측 성능을 개선하기 위해 domain-specific quantitative model과 depp learning 구성 요소를 결합한 하이브리드 모델의 최신 트렌드를 분석
이후 신경망을 사용하여 의사 결정 지원을 촉진할 수 있는 두 가지 주요 접근 방식(`interpretability`, `counterfactual prediction`)을 간략하게 설명
시계열 예측을 위한 유망한 연구 방향, 특히 continuous-time 및 계층적 모델에 대한 연구 방향을 제시
2. Deep Learning Architectures for Time Series Forecasting
시계열 예측 모델은 t 시점에 주어진 entity i 타겟 y_i,t에 대한 미래 값을 예측
각 entity는 시간적 정보의 논리적 그룹화를 나타낸 것으로 동시에 관찰이 가능
기후학에서 개별 기상 관측소의 측정값이나, 의학에서 여러 환자의 vital sign 등
`one-step-ahead` 예측 모델은 다음과 같은 수식을 따름
^y_i, t+1 : model forecast
y_i,t-k:t 와 x_i,t-k:t : `look-back window` k에 대한 각각 타겟과 input의 관측치
s_i : entity와 관련된 통계적 metadata(sensor location 등)
f() : 모델에 의해 학습된 예측 함수
이 서베이에선 단변량 예측에 집중했지만, 일반성을 잃지 않고 동일한 구성 요소에 대해 다변량 예측에 확장이 가능
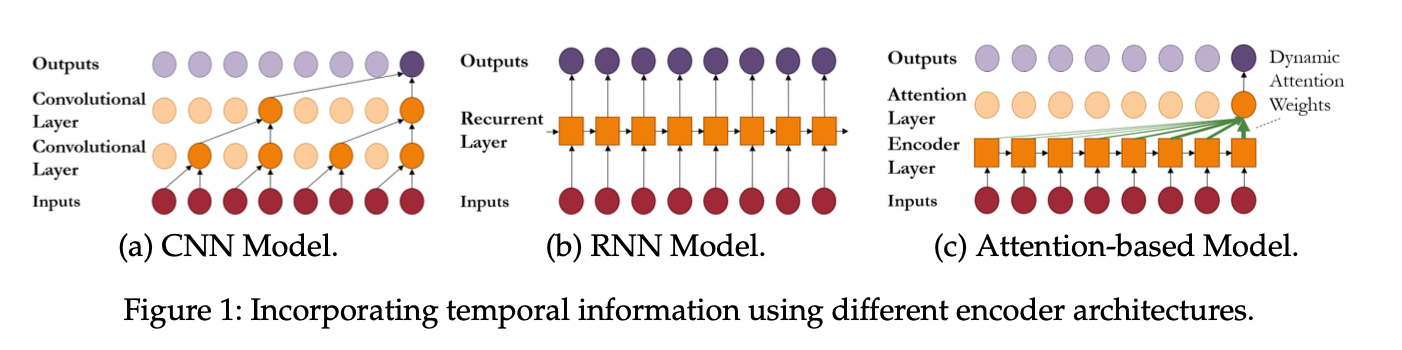
(a) Basic Building Blocks
Deep neural networks는 일련의 비선형 계층을 사용하여 중간 feature representation을 형성함으로써 예측 관계를 학습
시계열에서는 관련된 이전 정보를 잠재 변수 z_t로 인코딩하고, 최종 예측은 z_t만을 이용해 생성
g_enc(), g_dec()는 각각 인코더와 디코더 함수
이러한 인코더와 디코더는 딥러닝 아키텍처의 기본 구성 요소를 형성하며, 네트워크 선택에 따라 모델에서 학습할 수 있는 관계의 유형을 결정
(1) Convolutional Neural Networks
전통적으로 이미지 데이터셋을 위해 설계된 `Convolutional Neural Networks(CNNs)`는 공간 차원에 걸쳐 불변하는 `local relationship`을 추출
CNNs을 시계열 데이터셋에 적용시키기 위해, 여러 계층의 `causal convolutions`, 즉 과거 정보만 예측에 사용하도록 convolutional filter를 설계
💡 causal convolutional filter `causal`이라는 단어는 `causality`에서 비롯된 것으로 신호 처리, 특히 필터의 특성화에서 유래하였다. 신호는 시간 및/또는 공간의 함수이며, 필터는 신호의 특정 측면을 제거하여 관심 있는 특징만 남기는 기능이다. `Linear filter`는 각 시간 및/또는 공간의 각 지점에서 입력의 `weighted sum(가중합)` / `integral of the input(적분)` , 즉 `convolution`에 의해 출력이 결정되는 필터이다. 여기서 필터의 output이 미래의 input에 의존하지 않는 경우 `causal filter`라고 한다. 즉, 데이터를 읽는 표준 방향이 정해져 있으면 현재 위치보다 앞선 데이터는 계산에 반영할 수 없다. 이러한 causal filter가 주로 사용된 모델은 `WaveNet`이 있으며, 2D 이미지와 같은 다른 형태의 데이터에도 적용이 가능하다.(`PixelCNN` 등) 딥러닝 프레임워크에서 causal filter를 구현하는 방법은 두 가지이다. 첫 번째는 filter kernel에서 미래 input과 관련된 부분을 SGD update마다 0으로 설정하여 마스킹하는 것이지만, 이는 곱셉과 덧셈의 약 절반이 낭비되므로 비용이 상당히 많이 든다. 더 효율적인 방법은 커널 크기에 따라 신호를 `shifting` 및 `padding`한 후 shifting을 취소하는 것이다.
hidden layer l 의 중간 feature의 경우 각 causal convolutional filter는 다음과 같은 형태를 취함
1-D 경우를 고려하면, 식 (2.5)가 디지털 신호 처리의 `Finite Impulse Response(FIR)` 필터와 매우 유사함을 알 수 있는데, 이는 CNN이 학습한 시간적 관계에 대한 두 가지 중요한 시사점을 제공
표준 CNN의 공간 불변성 가정에 따라 temporal CNNs은 각 time step과 모든 time에 걸쳐 동일한 `filter weight`를 사용하여 관계가 시간 불변적이라고 가정
CNN은 정의된 `lookback window`내의 input만 사용하여 예측을 수행
모델이 모든 관련 과거 정보를 사용할 수 있게끔 receptive filed size k를 신중하게 조정해야 함
💡 1-D CNN 1-D CNN이란, convolution filter를 통한 convolution 연산 과정에서 한 방향(가로)으로만 연산이 수행되는 것을 말한다. 이를 통해 나오는 결과 또한 1차원 배열이다. 1D-CNN은 주로 sequence 데이터들과 NLP에서 사용된다.
선형 활성화 함수가 있는 단일 causal CNN layer는 `Auto-Regressive(AR) model`과 동일
Dilated Convolutions
표준 Convolutional layer를 사용하면 receptive filed의 크기에 따라 파라미터의 수가 직접적으로 확장되기 때문에 `long-term dependency`가 중요한 경우 계산적으로 어려울 수 있음
이를 완화하기 위해 최신 아키텍처에는 `dilated convolutional layer`를 자주 사용
이는 식 (2.5)를 아래와 같이 확장
d_l : layer-specific dilation rate
dilated convolution은 하위 layer feature의 다운샘플링된 버전의 convolution으로 해석이 가능하며, 먼 과거의 정보를 통합하기 위해 해상도를 감소시킴
각 layer마다 확장 속도를 증가시킴으로써 서로 다른 time block의 정보를 점진적으로 통합할 수 있어 더 많은 과거를 효율적으로 사용
💡 Dilated Convolution 먼저 `receptive field`란, filter가 한번에 보는 영역을 말한다. receptive field가 늘어난다는 것은 output을 계산할 때 사용하는 정보의 양이 많아진 다는 것을 의미한다. 이 경우 성능이 좋아질 확률도 높아지지만, 학습해야하는 양이 많아지기 때문에 연산량이 증가하는 단점도 있다. 이러한 receptive filed를 높이기 위해서 filter의 크기를 키우거나, layer를 늘리거나, pooling을 사용하는 방법이 있다. pooling의 경우 앞선 두 가지 방법과는 다르게 연산량까지 감소시킬 수 있지만, 정보의 손실을 가져올 수 있다는 단점이 있다. Dilated convolution`Dilated Convolution`이란 receptive filed를 크게 만드는 것과 동시에 연산량의 증가도 막는 효과적인 방법이다. Dilated Convolution은 filter matrix 사이에 0을 삽입하여 filter가 추출해내는 input의 간격은 멀어지게 된다. 이를 통해 receptive field는 늘어나지만 연산량은 증가하지 않는다. 이렇게 filter가 희소하게 feature를 추출함으로써 정보 손실도 있을 수 있지만, receptive field의 크기가 중요한 경우 잘 작동한다고 알려져 있다.
(2) Recurrent Neural Networks
`Recurrent Neural Networks(RNN)`은 역사적으로 sequence modeling에 사용되었으며, 다양한 자연어 처리 작업에서 강력한 결과를 보임
시계열 데이터를 input과 target의 sequence로 해석할 수 있어 temporal forecasting을 위해 RNN 기반 아키텍처가 개발
RNN cell의 핵심은 과거 정보를 간결하게 요약하는 역할을 하는 내부의 `memory state`
memory state은 각 time step의 새로운 관측치에 의해 다음과 같이 재귀적으로 업데이트
z_t : RNN의 hidden internal state
v() : learnt memory update function
RNN의 가장 간단한 변환 중 하나인 `Elman RNN`의 예로 다음과 같은 형태를 취함
W와 b는 각각 네트워크의 선형 가중치와 편향
r_y와 r_z는 network activation function
RNN은 CNN처럼 lookback window를 지정할 필요가 없음
Long Short-term Memory
RNN은 lookback window를 따로 지정하지 않아 무한 lookback window가 발생하는데, 이로 인해 구형 RNN은 데이터의 `long-range dependency`가 발생
`gradient exploding` 및 `gradient vanishing` 발생
네트워크의 내의 gradient flow를 개선하여 이러한 문제점을 해결하기 위해 `Long Short-Term Memory(LSTM)` 개발
LSTM은 아래와 같이 long-term information을 저장하는 `cell state` c_t를 사용해 개선
z_t-1은 LSTM의 hidden state이며 `sigmoid function` 사용
gate는 다음과 같이 LSTM의 hidden state와 cell state를 수정
`element-wise product` 및 `tanh` 활성화 함수 사용
Relationship to Bayesian Filtering
`Bayesian filter`와 `RNN`은 시간이 지남에 따라 재귀적으로 업데이트되는 hidden state를 유지한다는 점에서 유사
`Kalman filter`와 같은 베이지안 필터의 경우 추론은 `state transition`과 `error correction step`을 사용한 latent state의 sufficient statistics을 업데이트하여 수행
Bayesian filtering step은 `deterministic equation`을 통해 sufficient statistics를 변경하며, RNN은 예측에 필요한 모든 관련 정보를 포함하는 memory vector를 사용하기 때문에 두 단계의 동시 근사치로 볼 수 있음
💡 Bayes Filter `Bayes Filter`는 확률 기반의 `recursive`한 filter이다. 여기서 recurvise하다는 것은 지금 구한 `posterior`가 다음 스텝에서 `prior`로 사용된다는 것을 뜻한다. Bayes Filter는 `Bayes Theorem`을 recursive하게 따른다. Bayes Filter의 식은 다음과 같다.
이러한 Bayes Filter의 목적을 수식으로 표현하면 다음과 같다. 본 논문에서는 RNN과 Bayesian Filtering의 이러한 recursive한 구조를 통해 각각 memory vector와 sufficient statistics를 변경한다는 공통점을 이야기하는 것 같다.
(3) Attention Mechanisms
`Attention mechanism`의 개발은 long-term dependency를 학습을 개선시켰으며, `Transformer` 아키텍처는 여러 NLP 분야에서 SOTA를 달성
Attention layer는 동적으로 생성된 가중치를 사용하여 시간적 특징을 집계하기 때문에 네트워크가 lookback window에서 아주 먼 과거에 있더라도 과거의 중요한 time step에 직접적으로 집중할 수 있음
Attnetion은 주어진 query를 기반으로 `key-value` 조화를 위한 메커니즘
k는 key, q는 query, v는 value이며 이들은 이전 level의 다른 time step에서 생성된 중간 특징
alpha는 time t에서 생성된 t-tau에 대한 `attention weight`
h_t는 attention layer의 `context vector` output
CNN의 경우처럼 여러 attention layer를 사용할 수 있으며, 최종 layer의 output은 인코딩된 latent variable z_t를 형성
최근 연구들은 시계열 예측에 attention mechanism을 사용할 때 Recurrent networks의 성능을 개선하는 이점을 보임
이 논문의 예시에서는 attention을 활용하여 RNN encoder가 추출한 특징을 집계하며, 다음과 같이 attention weight를 생성
k_t-1과 q_t는 특징 추출을 위해 사용한 LSTM encoder의 output
최근에는 lookback window 내에서 추출된 특징에 `scalar-dot product self-attention`을 적용하는 Transformer 아키텍처를 고려
시계열 모델링에서 attention은 두 가지 주요한 이점을 제공
attention을 활용한 network은 발생하는 모든 주요한 이벤트에 직접적으로 대응이 가능
attention-based network는 각 regime에 대해 고유한 attention weight를 사용하여 regime-specific한 시간적 역학을 학습 가능
(4) Outputs and Loss Functions
neural network의 유연성을 고려했을 때, deep neural network은 원하는 target 유형에 맞게 신경망의 디코더와 neural network의 output layer를 커스터마이징하여 연속 및 불연속 target 모두에 사용
`one-step-ahead prediction` 문제에선 인코더의 output의 선형 변환(식 2.2)을 target에 대한 적절한 output activation과 결합
target의 형태와 상관없이 prediction은 `point estimates`와 `probabilistic forecasts`라는 두 가지 범주로 나뉨
Point Estimates
예측에 대한 일반적인 접근 방식은 미래 target에 대한 예상값을 결정하는 것
이는 기본적으로 인코더를 사용하여 불연속적인 output은 classification task로, 연속적인 output은 regression task로 문제를 재구성하는 것이 포함
`binary classification`의 경우 디코더의 최종 layer에는 `sigmoid` 활성화 함수가 있는 linear layer가 포함되어 네트워크가 주어진 time step에서 사건의 발생 가능성을 예측
이진 및 연속 target의 one-step-ahead 예측을 위해 네트워크는 각각 `binary cross-entropy`와 `mean square error loss function`을 사용하여 훈련
Probabilistic Outputs
`point estimates`는 target의 미래 값을 예측하는 데 매우 중요하지만, 모델 예측의 불확실성을 이해하는 것은 다양한 도메인의 의사 결정에 유용
예측 불확실성이 큰 경우, 모델 사용자는 예측을 의사 결정에 통합할 때 더 신중을 가하거나 다른 소스 정보에 의존할 수 있음
불확실성을 모델링하는 가장 일반적인 방법은 deep neural networks을 사용하여 알려진 분포의 매개변수를 생성하는 것
`Gaussian distribution`은 일반적으로 연속적인 target의 예측 문제에 사용되며, 네트워크는 다음과 같이 각 단계에서 예측 분포의 평균과 분산 파라미터를 출력
h_t^L : 네트워크의 최종 layer
`softplus` 활성화 함수는 표준 편차가 오직 양수만 취하게 함
(b) Multi-horizon Forecasting Models
다음 time step의 값만 예측하는 것이 아닌 여러 개의 time step의 값을 예측하는 모델
많은 경우 의사 결정자가 미래의 multiple points에 대한 예측 추정치에 접근하여 미래 trend를 시각화하고 전체 경로에 걸쳐 행동을 최적화할 수 있도록 하는 것이 유용할 때가 많음
통계적으로 `multi-horizon forecasting`은 다음과 같이 `one-step-ahead prediction` 문제를 약간 수정한 것으로 볼 수 있음
tau : discrete forecast horizon
u_t : known future inputs across the entire horizon
x_t : inputs that can only be observed historically
💡 one-step ahead prediction vs multi-horizon forecasting : one-step ahead prediction의 수식(식 2.2)과 비교해보면, 새롭게 u_t-k:t+tau와 tau 값이 추가 된 것을 확인할 수 있다. 설명을 확인해보면 u_t는 전체 horizon에 걸쳐 알고 있는 future inputs을 의미하며, tau 값은 discrete forecast horizon이다.
multi-horizon forecasting을 위한 deep learning 아키텍처는 `Iterative method`와 `Direct method` 두 가지 방식으로 나뉨
(1) Iterative Methods
`Iterative Methods`는 일반적으로 `autoregressive deep learning` 아키텍처를 사용하여 target의 샘플을 future time step에 recursive하게 공급하여 multi-horizon forecast를 생성
이 과정을 반복하여 여러 여러 `trajectory`를 생성한 후 각 step에서 target 값의 샘플링 분포를 사용하여 예측을 생성
예를 들어 `Monte Carlo estimate`를 예측 수단으로 사용 가능
Autoregressive 모델은 one-step-ahead 예측 모델과 동일한 방식(시간을 통한 역전파)으로 학습되기 때문에 Iterative 접근 방식을 사용하면 standard 모델을 multi-step 예측으로 쉽게 일반화 가능
하나씩 예측하며, 해당 예측값을 통해 다시 다음 예측값을 생성
그러나 각 time step마다 작은 양의 오차가 발생하기 때문에, Iterative methods의 recursive structure는 잠재적으로 더 긴 예측 기간에 걸쳐 큰 오차가 누적될 수 있음
Iterative Methods는 target의 샘플만을 future time step의 예측에 사용하기 때문에, 많은 관측된 input들이 존재하는 실제 상황에서는 한계점이 되며 더 유연한 방법이 필요
(2) Direct Methods
`Direct Methods`는 모든 이용가능한 input을 사용하여 예측을 생성하여 Iterative Methods의 한계를 완화
일반적으로 `sequence-to-sequence` 모델을 사용하며 encoder를 통해 과거 정보(targets, observed inputs, priori known inputs)를 인코딩하고, 디코더를 통해 이를 알려진 미래 future inputs과 결합
`maximum forecast horizon(tau_max)`, 즉 몇 개를 예측 할지에 대해 미리 하이퍼파라미터로 지정해줘야 함
3. Incorporating Domain Knowledge with Hybrid Models
이러한 인기에도 불구하고 시계열 예측을 위한 머신러닝의 효율성은 역사적으로 의문이 제기되어 옴
머신러닝 방법의 유연성은 양날의 검이 될 수 있으며, 과적합이 발생하기 쉬움
데이터의 개수가 적은 경우에는 단순한 모델이 잠재적으로 더 좋은 성능을 보일 수 있음
통계 모델의 `stationarity`의 요구와 비슷하게 머신러닝 모델은 input의 전처리 방식에 민감할 수 있으며, 이는 training 및 test에서의 데이터 분포가 유사함을 보장해야함
딥러닝의 최근 트렌드는 이러한 한계를 해결하는 `Hybrid Model`을 개발하여 다양한 경우에서 순수 통계 또는 머신러닝 모델보다 향상된 성능을 입증하는 것
`Hybrid Methods`는 잘 연구된 `quantitative time series model`과 더불어 심층 신경망을 사용하여 각 time step에서 모델 파라미터를 생성하는 딥러닝을 결합
Hybrid 모델을 사용하면 도메인 전문가가 사전 정보를 사용하여 신경망에 정보를 제공함으로써 네트워크의 가설 공간을 줄이고, 일반화를 개선
이는 딥러닝 모델의 과적합 위험이 큰 소규모 데이터셋에 유용
Hybrid 모델은 또한 stationary 요소와 non-stationary 요소를 분리할 수 있어 custom input pre-processing가 필요 x
M4 competition에서 우승한 `Exponential Smoothing RNN(ES-RNN)`이 그 예로, `Exponential Smoothing`을 사용해 non-stationary trend를 포착하고, `RNN`을 통해 추가적인 효과를 학습
일반적으로 Hybrid 모델은 두 가지 방법을 통해 심층 신경망을 활용
non-probabilistic parametric 모델의 time-varying 파라미터를 인코딩
probabilistic 모델에서 사용되는 distribution의 파라미터를 생성
(a) Non-probabilistic Hybrid models
parametric 시계열 모델의 경우 예측 방정식이 일반적으로 분석적으로 정의되며 미래 target에 대한 `point forecast`를 제공
따라서 Non-probabilistic Hybrid 모델은 이러한 예측 방정식을 수정하여 통계 및 딥러닝 요소를 결합
`ES-RNN`의 경우 `Holt-Winters exponential smoothing model`의 update 방정식을 활용하여 다음과 같이 multiplicative level과 seasonality의 구성 요소를 딥러닝의 output과 결합
`Probabilistic hybrid model`은 Gaussian processes 및 linear state space model과 같은 temporal dynamic에 사용되는 확률적 생성 모델을 활용하는 등 분포 모델링이 중요한 경우에 사용될 수 있음
예측 방정식을 수정하는 대신, Probabilistic hybrid model은 신경망을 사용하여 각 단계에서 예측 분포에 대한 매개변수를 생성
`Deep State Space Model`은 아래와 같이 linear state space model에 대해 시간에 따라 변하는 파라미터를 인코딩하여 `Kalman filtering` 방정식을 통해 추론을 수행
l_t : hidden latent state
a(.), F(.), q(.) : linear transformations of h^L_i,t+tau
phi(.), ∑(.) : linear transformations with softmax activations
4. Facilitating Decision Support Using Deep Neural networks
모델을 만드는 사람은 예측의 정확도에 집중하지만, 해당 모델을 사용하는 사람은 일반적으로 예측값을 향후 행동에 사용
시계열 예측이 중요한 사전 단계이지만, 시간적 역학과 동기를 잘 이해하는 것은 사용자가 그들의 행동을 더욱 최적화하는데 도움을 줌
이번 섹션에서는 시계열 데이터로 의사 결정을 돕기 위해 신경망이 확장된 두 가지 방향, 즉 `해석 가능성(interpretability)`와 인과 추론(causal inference)`에 대해 확인
(a) Interpretability With Time Series Data
mission-critial의 경우에 신경망이 도입되면서 모델 의 특정 예측에 대한 `how` 그리고 `why` 두 가지를 모두 이해할 필요성이 늘어남
최근 데이터셋의 크기와 복잡성이 증가함에 따라 최종 사용자는 데이터에 존재하는 관계에 대해 사전 지식이 거의 없을 수 있음
표준 신경망 아키텍처의 `black-box` 특성을 고려할 때, 딥러닝 모델을 해석하는 방법에 대한 연구가 많이 등장
Techniques for Post-hoc Interpretability
`Post-hoc interpretable model`은 학습된 네트워크를 해석하기 위해 개발되며, 원래 가중치를 수정하지 않고도 중요한 feature와 example을 확인하는데 도움이 됨
첫 번째 방법은 input과 output 사이에 더 간단한 해석 가능한 surrogate 모델을 적용하고, 설명을 제공하기 위해 approximate 모델에 의존하는 것
`Local Interpretable Model-Agnostic Explanations(LIME)`은 input의 변동에 대해 instance-specific 선형 모델을 fitting함으로써 관련 features을 식별하고, `선형 계수(linear coefficient)`를 중요도의 척도로 제공
`Shapley additive explanations(SHAP)`는 데이터셋의 중요한 features를 확인하기 위한 `cooperative game theory`를 통한 `Shapley value`를 사용하는 또다른 surrogate 접근 방법을 제공
두 번째 방법은 네트워크의 gradient를 분석하여 손실 함수에 가장 큰 영향을 끼치는 input features를 결정하는 `saliency map`과 `influence functions` 같은 gradient-based method
post-hoc interpretability methods는 feature 속성에는 도움이 될 수 있지만, 일반적으로 input 간의 `순차적 의존성(sequential dependencies)`를 무시하기 때문에 복잡헌 시계열 데이터셋에 적용하기는 힘듬
Inherent Interpretability with Attention Weights
다른 접근 방식은 전략적으로 배치된 attention layers의 형태로 설명 가능한 구성 요소로 아키텍처를 직접 설계하는 것
`attention wieghts`는 `softmax` layer의 output으로 생성되므로 가중치는 총합이 1이 되도록 구성
시계열 모델의 경우 수식 (2.15)의 output은 각 단계에서 attention layers가 제공한 가중치를 사용한 시간적 특징에 대한 가중 합으로 해석할 수 있음
attention weights을 분석하여 각 time step의 features의 상대적 중요성을 이해할 수 있음
(b) Counterfactual Predictions & Causal Inference Over Time
딥러닝은 네트워크가 학습한 관계를 이해하는 것에 더해 observational dataset의 예측, 즉 사실에 반대되는 예측을 생성하여 의사 결정을 지원하는 데 도움을 줄 수 있음
counterfactual predictions은 시나리오 분석의 경우에 특히 유용하며, 이를 통해 사용자는 다양한 행동들이 target trajectories에 어떤 영향을 미치는지 분석할 수 있음
이는 다른 상황이 발생하였으면 어떤 일이 일어났을지에 대한 역사적 관점과 미래 결과를 최적화하기 위해 어떤 조치를 취해야할지 결정하는 예측적 관점 모두에 유용
시계열 데이터셋의 핵심 과제는 `time-dependent confounding effects`의 존재
이를 조절하지 않으면 간단한 추정 기법은 편향된 결과를 초래
최근에는 통계적 기법의 확장과 새로운 손실 함수의 설계를 기반으로 time-dependent confounding effects를 조정하면서 심층 신경망을 훈련하는 여러 가지 기법이 등장
5. Conclusions and Future Directions
시계열 예측에 사용되는 주요 아키텍처를 살펴보고, 신경망 설계에 사용되는 주요 구성 요소를 확인
one-step-ahead 예측을 위해 시간 정보를 통합하는 방법을 살펴보고, Multi-horizon 예측에 사용하기 위해 확장할 수 있는 방법을 확인
통계적 요소와 딥러닝 요소를 결합하여 두 범주(Iterative Methods, Direct Methods) 모두에서 기존 방식보다 뛰어난 성능을 보이는 하이브리드 딥러닝 모델의 최근 트렌드에 대해 간략하게 설명
마지막으로 interpretability와 counterfactual prediction에 초점을 맞춰 시간이 지남에 따 른 의사 결정을 지원을 개선하기 위해 딥러닝을 확장할 수 있는 두 가지 방법을 요약
시계열 예측을 위해 수많은 딥러닝 모델이 개발되었지만 여전히 몇 가지 한계점이 존재
심층 신경망은 일반적으로 시계열을 일정한 간격으로 이산화해야하므로, 관측이 누락되거나 임의의 간격으로 발생하는 데이터 집합에 대한 예측이 어려움
`Neural Ordinary Differential` 방정식을 통해 continuous-time 모델에 대한 일부 연구가 수행되었지만, 복잡한 입력(ex> static variables)이 있는 데이터셋에 대해 이를 확장하고 기존 모델과 벤치마크하기 위해선 추가적인 작업이 필요
시계열은 종종 `경로(trajectories)`간에 논리적으로 그룹화되는 계층 구조를 갖음
ex> 소매업 예측에서 동일한 지역의 제품 판매가 일반적인 추세의 영향을 받을 수 있음
이러한 계층적 구조를 명시적으로 설명하는 아키텍처를 개발하는 것은 흥미로운 연구 방향이 될 수 있으며, 잠재적으로 univariate 혹은 multivariate 모델보다 예측 성능을 개선시킬 수 있음