-
Transformer
-
Encoder-Decoder
-
Input Embeddings
-
Positional Encoding
-
Encoding procedure
-
Self-Attention in Detail
-
Multi-Head Attention / Residual connection & Normalization
-
Multi-Head Attention
-
Residual connection & Normalization
-
Position-wise Feed Forward Networks
-
Masked Multi-Head Attention
-
Multi-Head Attention with Encoder Outputs
-
The Final Linear and Softmax Layer
Transformer
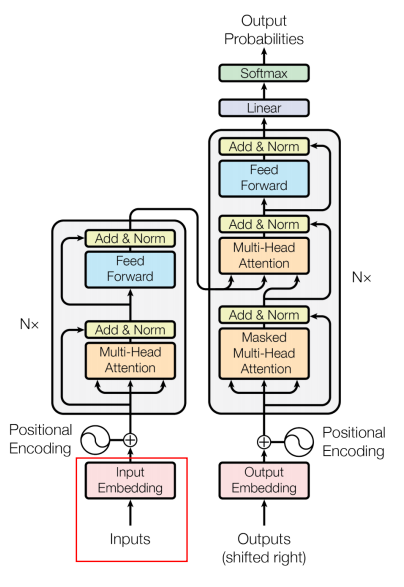
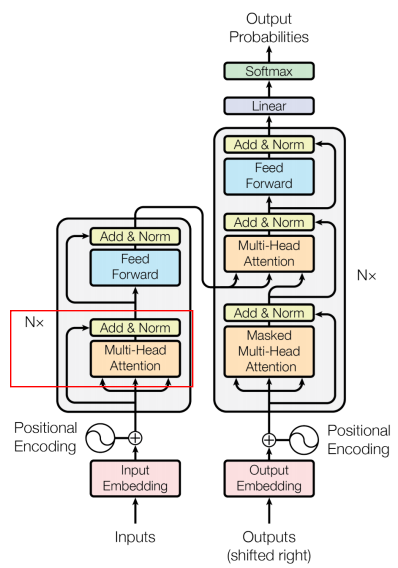
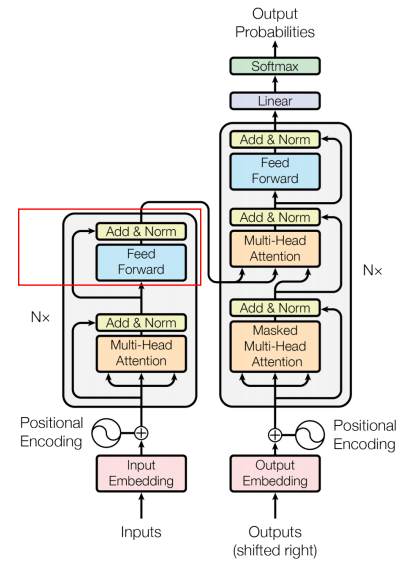
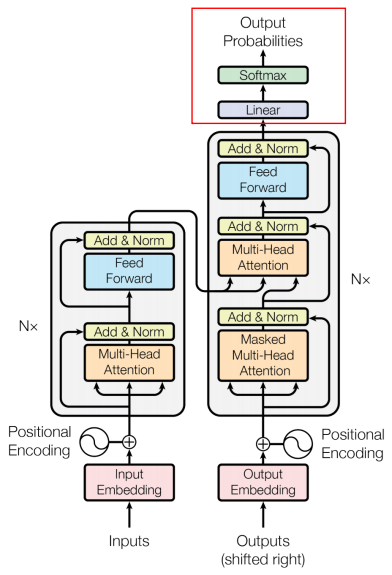
Transformer는 Attention을 사용하면서 학습과 병렬화를 쉽게 하여 속도를 높인 모델이다. Transformer는 Seq2Seq 모델과 같이 순차적으로 input 토큰을 처리하는 것이 아니라 이를 한꺼번에 처리한다.Transformer 모델의 기본적인 구조는 다음과 같다.
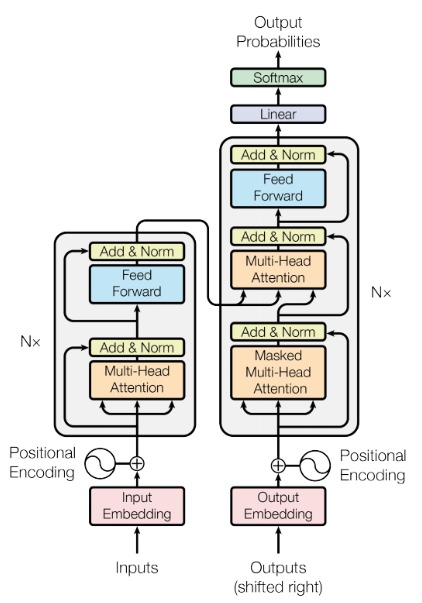
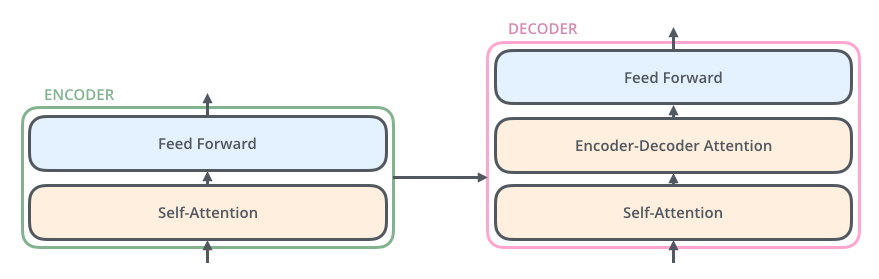
Transformer 모델을 signle black box와 같이 표현하면 다음과 같다. 이는 RNN 기반의 Encoder-Decoder 구조와 Input과 Output은 동일하다. 또한 Transformer를 자세히 들여다 보면 Encoding component와 Decoding Component가 따로 존재하며, 이를 어떻게 연결하는지가 결국 RNN 구조와의 차이점이다.

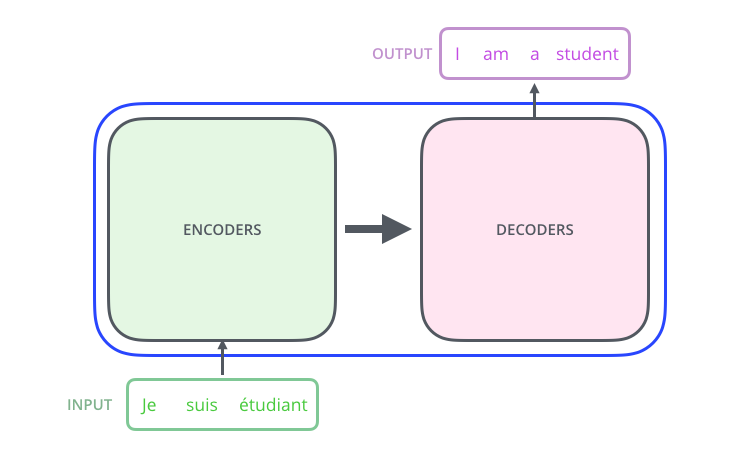
Encoder-Decoder
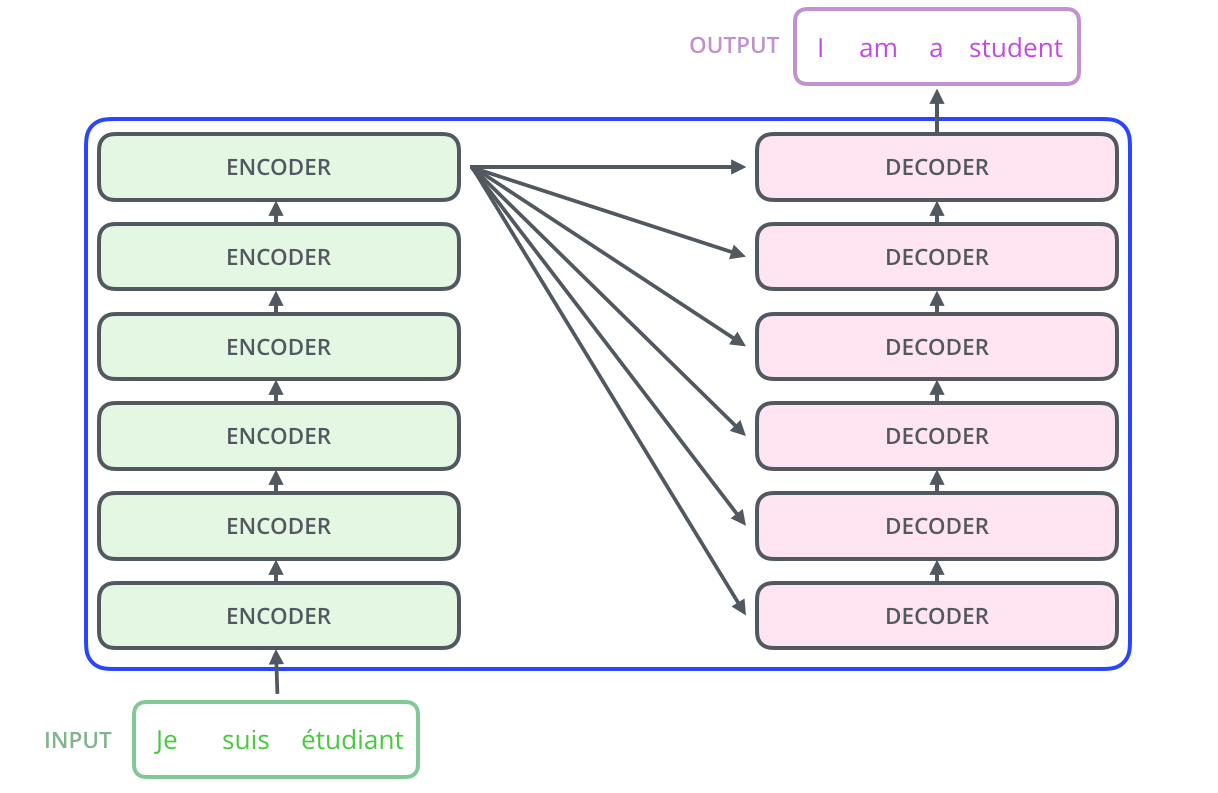
여기서 Encoding Component는 Encoder를 여러 개 쌓은 것이며, 논문에선 6개의 Encoder를 쌓았다. 6개를 쌓은 데에는 다른 이유는 없는 것으로 나타난다. Decoding Component 또한 Decoder를 Encoder와 같은 개수로 쌓은 것이다.
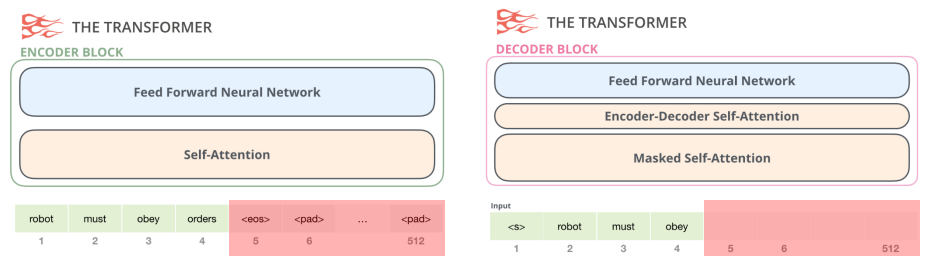
Encoder block과 Decoder block의 차이점은 Encoding의 경우 순차적일 필요가 없기 때문에 한꺼번에 모든 시퀀스를 다 사용하는 Unmasked에 해당하며, Decoding은 시퀀스를 생성하는 경우 순서가 중요하기 때문에 순서에 따라 masking되어 있는 Masked에 해당한다는 점이다. 아래의 예시에서 Encoder block의 경우 모든 시퀀스에 해당하는 토큰을 사용하지만, Decoder block에서는 4번째 단어를 생성할 시 orders 이후의 토큰들은 masking된다.
Encoder에 경우 2개의 sub-layers로 구성된다. 먼저 Self-Attention layer에서는 하나의 토큰에 대한 정보를 처리하기 위해서 함께 주어진 다른 토큰들을 얼마만큼 중요하게 볼지 결정한다. 이후 Feed Forward Neural Network layer에선 Self-Attention의 output에 해당하는 토큰들을 Feed Forward Neural Network에 전달하여 최종 Output을 산출한다.
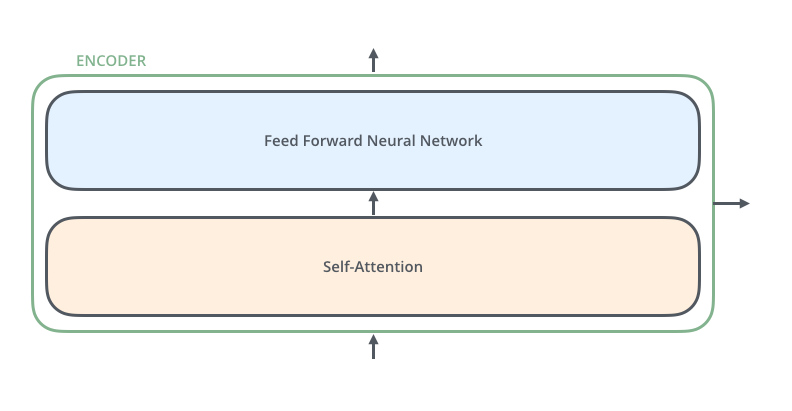
Decoder은 3가지의 sub-layers로 구성된다. 먼저 Self-Attention layer를 통해 자기 자신들끼리 Self-Attetion을 수행하고, Encoder-Decoder Attention layer를 통해 Self-Attention의 Output과 Encoder에서 가지고 온 정보들과의 Attention을 수행한다. 이는 Encoder에서 주어지는 정보들을 어떻게 반영할 것인지를 결정한다. 마지막으로 Feed Forward Neural Network layer를 통해 최종적인 Decoder의 Output을 산출한다.
Input Embeddings
Input Embedding이란 Transformer 모델에 처음 들어가는 벡터 형태의 정보이다. 여러 가지 embedding 알고리즘들(GloVe, FastText, word2vec 등)을 통해 input word를 각각 512차원의 벡터의 형태로 바꿔준다. 여기서 embedding은 bottom-most encoder, 제일 첫번째 Encoder의 입력으로만 사용된다. 나머지 Encoder의 경우 이전 Encoder의 Output을 입력으로 사용한다. 여기서 사이즈는 모두 유지된다. 여기서 한 시퀀스의 길이를 최대 몇 개까지 사용할지에 대한 부분은 지정해주어야 할 하이퍼 파라미터이다.

Positional Encoding
앞서 보았듯이 Transformer는 한번에 전체 시퀀스를 통으로 입력한다. 이 경우 어떤 단어가 몇 번째 위치에 있는지에 대한 정보가 손실될 수 있다. 따라서 Positional Encoding과정을 통해 Encoding vector를 Input Embedding에 더하여 각 단어가 가지고 있는 위치 정보를 완벽하진 않지만 어느 정도 보전한다.
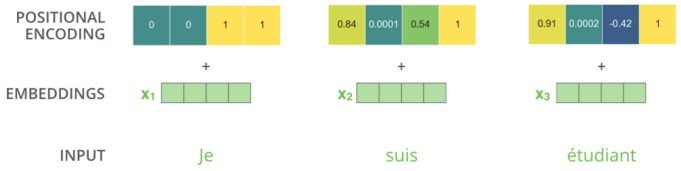
Encoding procedure
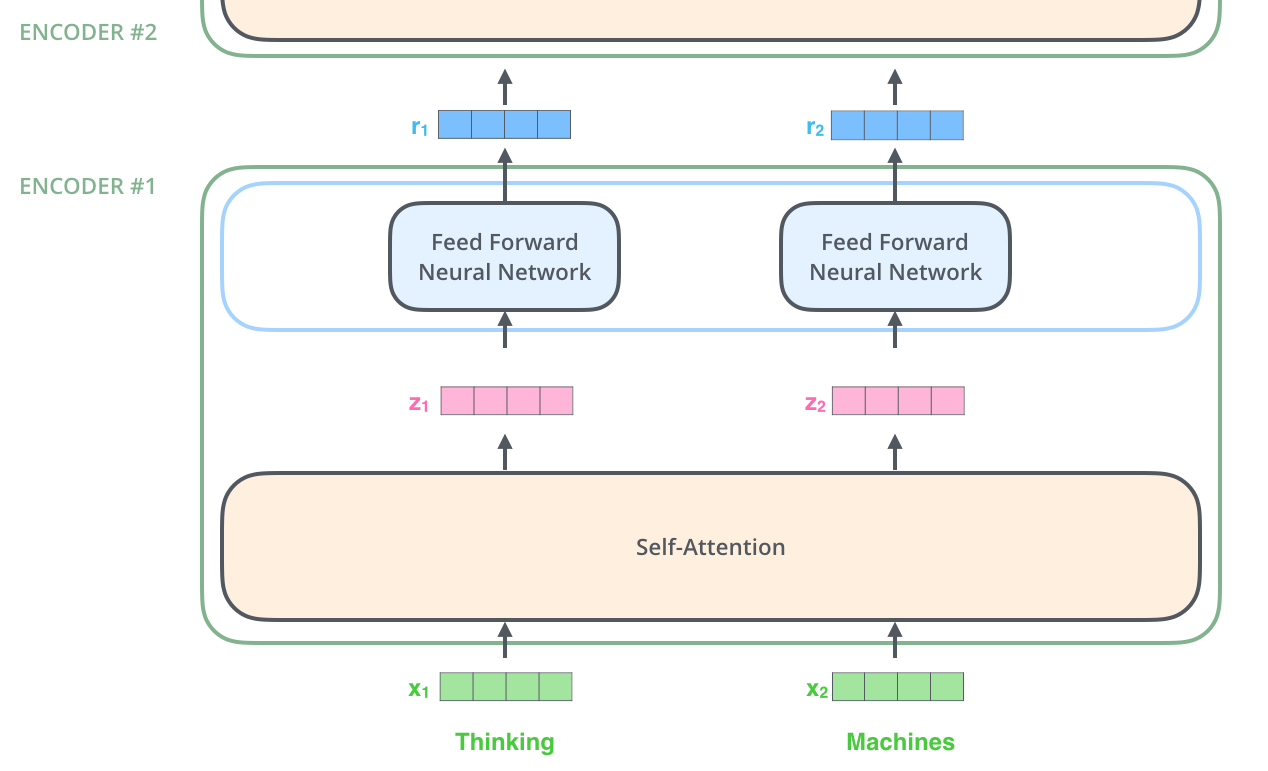
단어들에 대한 Embedding 과정이 끝난 후 각 포지션에 있는 단어들은 각자의 path를 따라 각각 Encoder의 2 layers로 입력된다. 여기서 Self-Attention layer의 경우 현재 processing 중인 단어의 의미를 파악하고 동일한 input sequence에 주어진 다른 단어들을 살펴보는 역할을 하기 때문에 각 토큰들은 종속 관계에 있으며 서로 영향을 끼친다. 각 path별로 각 토큰들의 Self-Attention이 끝나고 생성된 Output은 Feed Forward Neural Network에 입력된다. 여기서 같은 Encoder 내의 각 Feed Forward Neural Network들의 structure(hidden layer의 개수, hidden layer 내 뉴런의 개수 등) 및 weight는 동일하며, 다른 Encoder에서의 structure와 weight는 다르다. Feed Forward Neural Network에서 각 토큰들은 독립 관계에 있으며 이를 통해 parallelization이 가능하게 된다. Feed Forward Neural Network를 거친 Output은 첫 번째 Encoder의 Output이 되며, 곧 두 번째 Encoder의 Input으로 활용된다.
Self-Attention in Detail
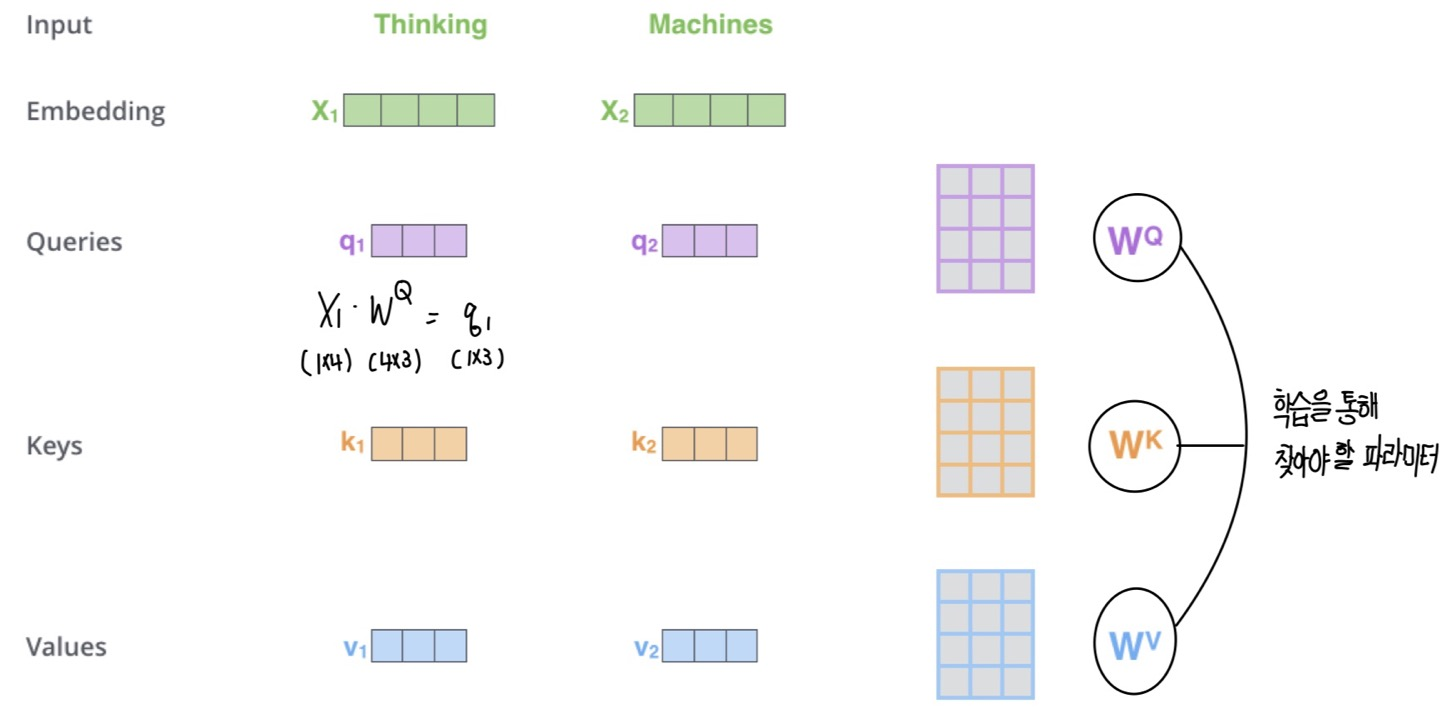
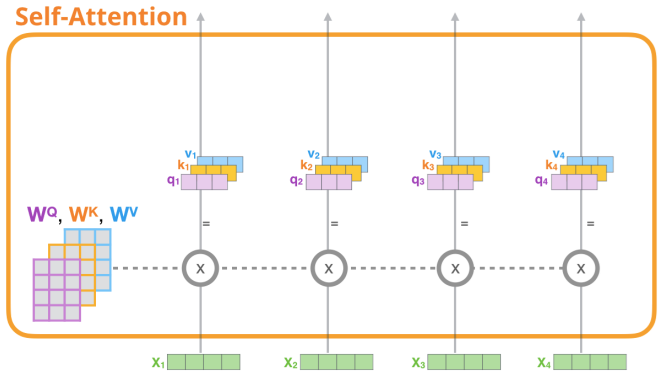
Self-Attention 과정을 디테일하게 살펴보겠다. 먼저, 각각의 input vector에 대하여 3종류의 벡터 Query, Key, Value를 생성한다. Query는 현재 보고 있는 단어를 대표하는 벡터로 다른 단어들의 key와의 scoring을 위한 기준이다. 이는 현재 processing하고 있는 단어의 Query만 다루게 된다. Key는 현재 단어와 관련 있는 단어를 찾을 때 각 단어들의 label과 같은 벡터이다. Value는 실제 각 단어별 값을 포함하는 벡터이다. 이러한 Query와 Key를 통해서 가장 적절한 value를 찾아서 연산을 수행한다.

또한 이러한 벡터들은 우리가 학습을 통해 찾아야할 파라미터인 Wq, Wk, Wv와 Input Embedding 간의 곱을 통해 생성된다. 이렇게 생성된 새로운 벡터 Q, K, V는 embedding vector보다 차원이 작다. 이는 향후 Multi-Head Attention을 수행하기 위함으로 만약embedding vector의 차원이 512라면, Q, K, V 벡터는 64차원이며 이후 Multi-Head Attention에 해당하는 8을 곱해 차원을 맞춘다.
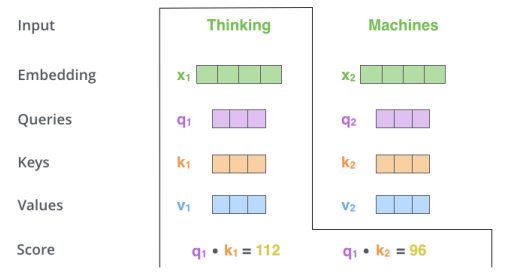
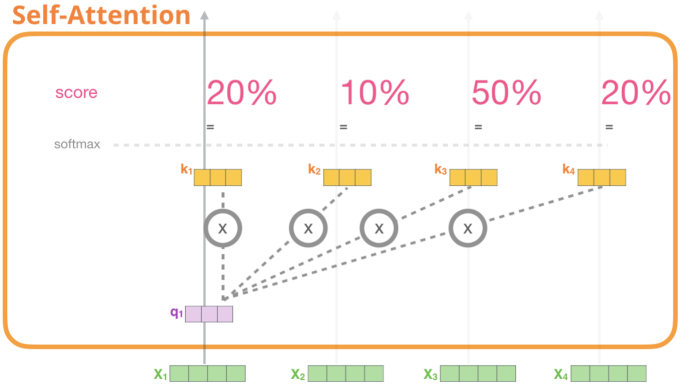
두 번째는 특정 포지션의 단어를 encoding 하기 위해 input sentence의 어떤 다른 파트를 집중할지에 대한 score를 계산하는 것이다. 이는 Query 벡터와 각 Key벡터에 대한 dot product(내적)으로 생성한다.
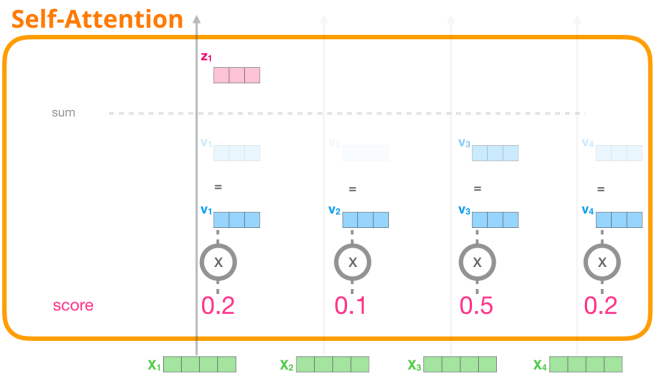
세 번째 단계로 이를 key vector의 차원의 제곱근으로 나누어준다. 이는 gradients를 더 안정적으로 만들어준다. 네 번째론 이 값에 softmax 함수를 실행하여 현재 position에 해당하는 이 단어가 현재 보고 있는 토큰에 얼마나 중요한 역할을 하는가를 softmax score를 통해 표현한다.
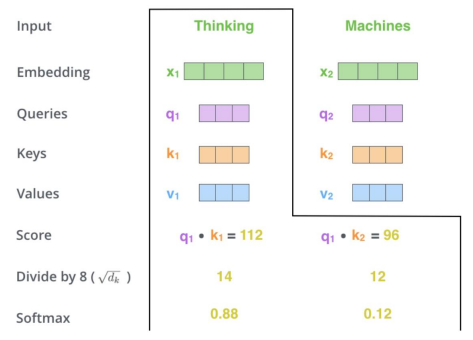
다섯 번째 단계로 이 softmax score와 value vector를 곱해주고, 마지막으로 각 단어별로 계산한 weighted value 값을 더해 해당 position에서의 최종 Output을 생성한다.
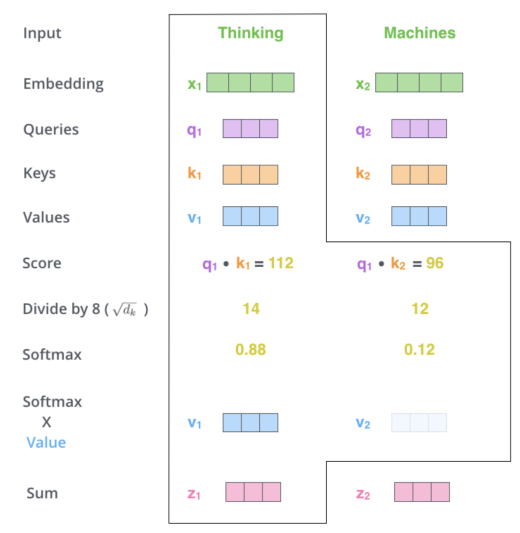
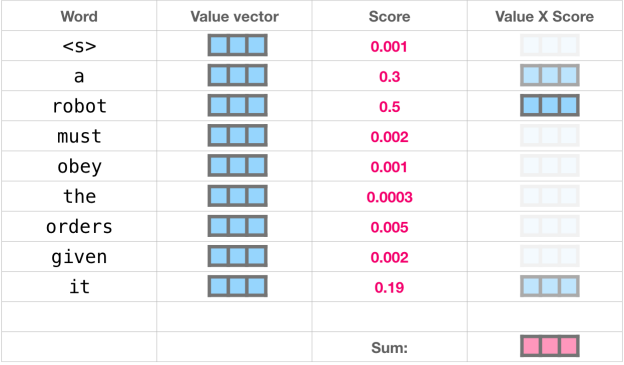
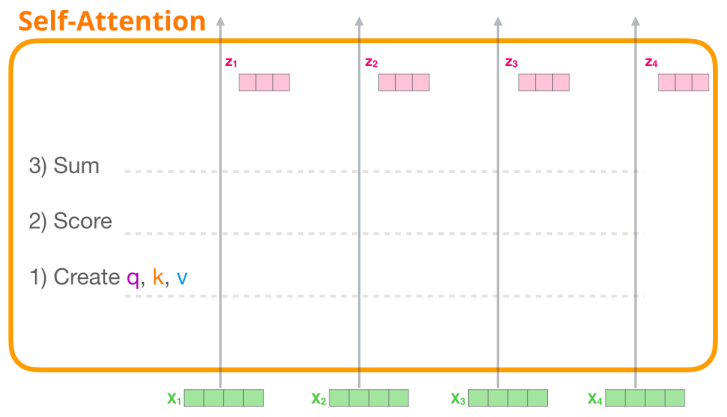
이러한 총 Self-Attention의 6단계 과정을 구체적인 예시로 보면 다음과 같다.
Self-Attention에는 여러 Matrix calculation이 나타나는데, 이는 다음과 같다.
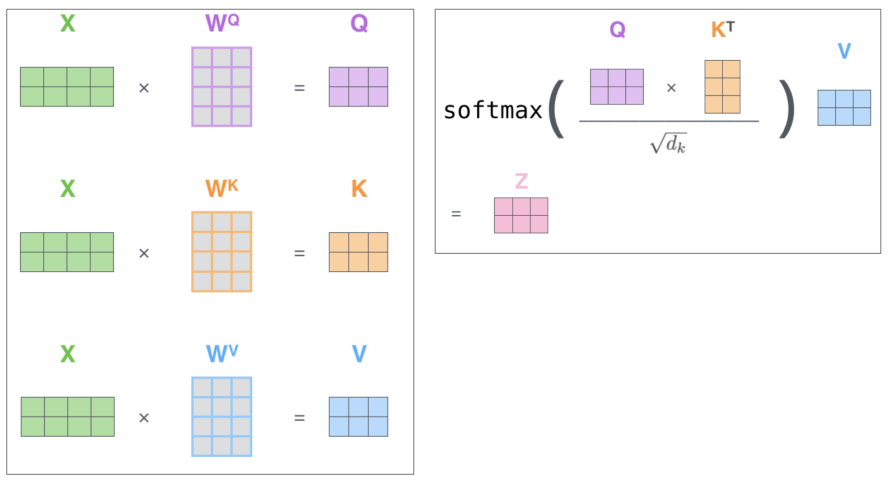
추가적으로 Self-Attention를 또다른 형태로 표현하면 다음과 같다.
Multi-Head Attention / Residual connection & Normalization
Multi-Head Attention
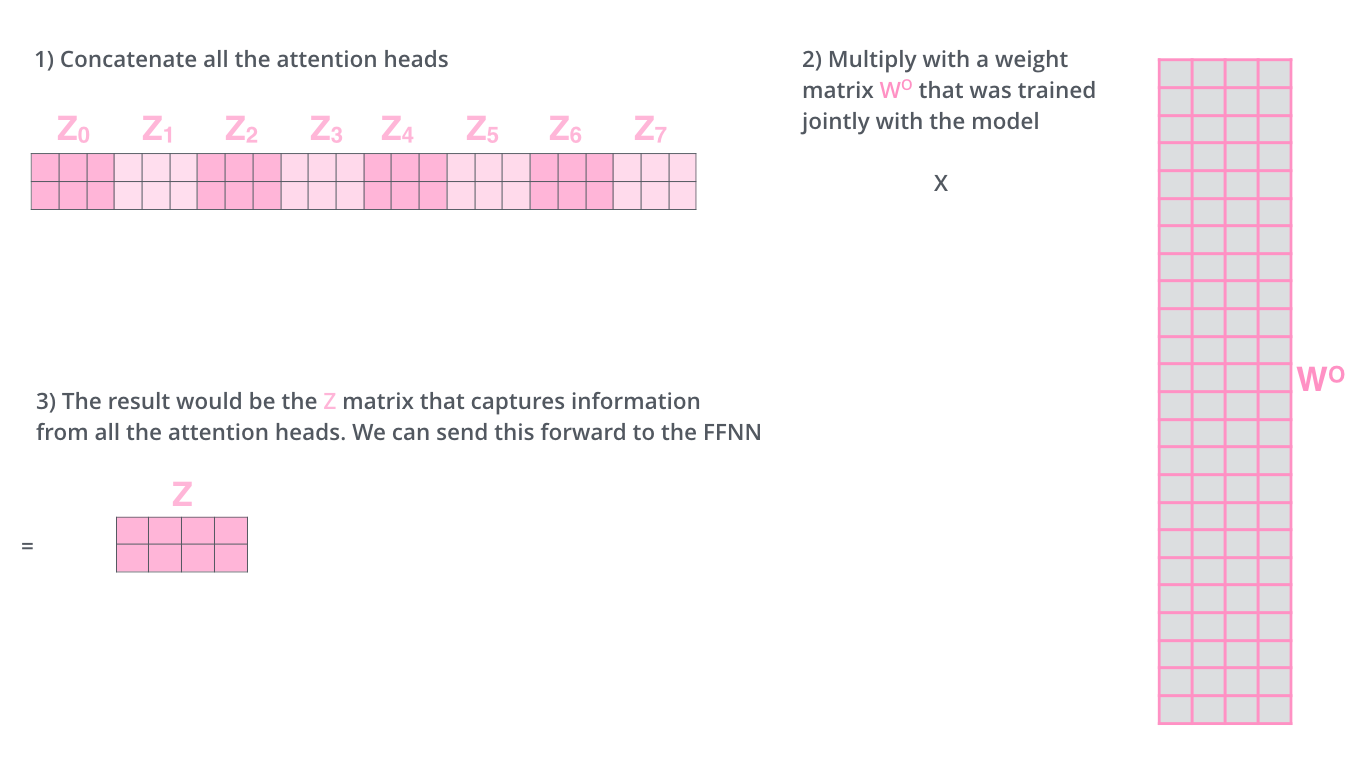
Multi-Head Attention은 Single Attention을 전부 다르게 8개를 만들어 생성된 각 Z 값을 활용하는 방법이다. 이를 위하여 각 Single Attention에서 생성된 Z 값들을 concatenated한 후, 모델 학습 과정에서 찾는 새로운 파라미터인 Wo와의 multiplied를 통해 향후 Feed Forward Neural Network에 활용될 Input을 생성한다. 이렇게 생성된 Z는 처음 Input Embedding과 동일한 차원의 Self-Attention Output이다.
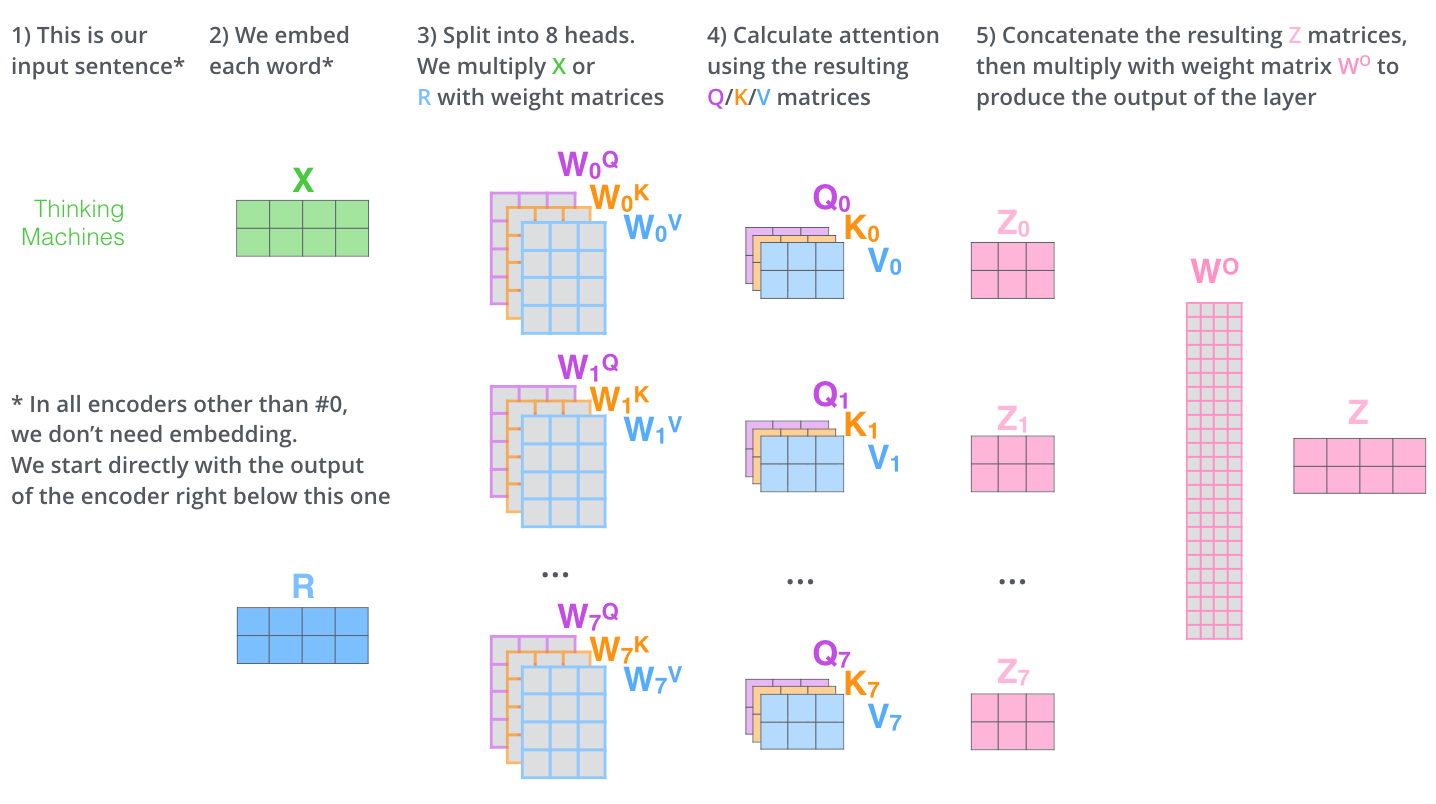
Multi-Head Attention의 전체적인 과정은 다음과 같이 표현할 수 있다. 해당 그림에서 R은 이전 Encoder의 Output으로 Original Input Embedding과 차원이 동일하다.
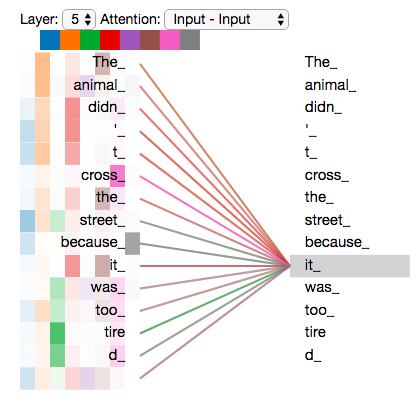
다음은 실제 Multi-Head Attention의 예시로 각 Single Attention마다 Output이 다르게 나타나는 것을 색으로 확인할 수 있다.
Residual connection & Normalization
Residual이란 원래 식에 자기 자신을 더해줌으로써 미분 이후 gradient가 매우 작아도 최소 1이 더해지는 형태로 만들어 학습에 유리하게 한다. 이러한 Redisual connection과 Layer-Normalization은 각 Encoder 내 Self-Attention과 Feed Forward Neural Network 이후에 존재한다.
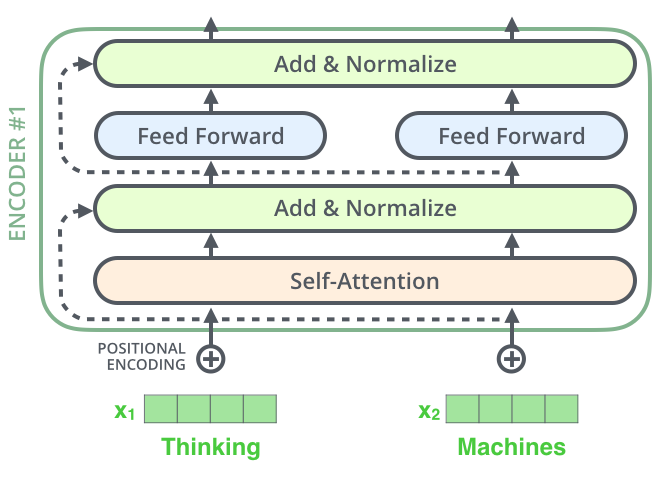
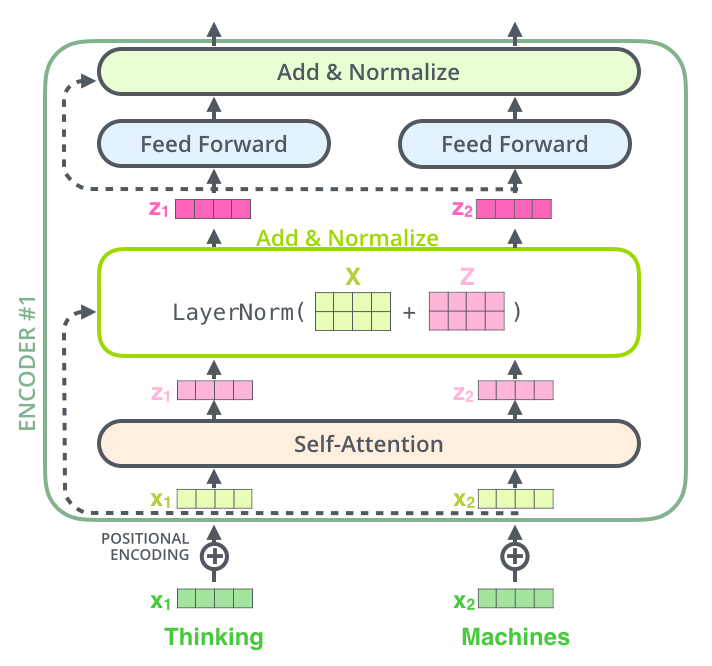
또한 이는 Decoder에도 적용된다.
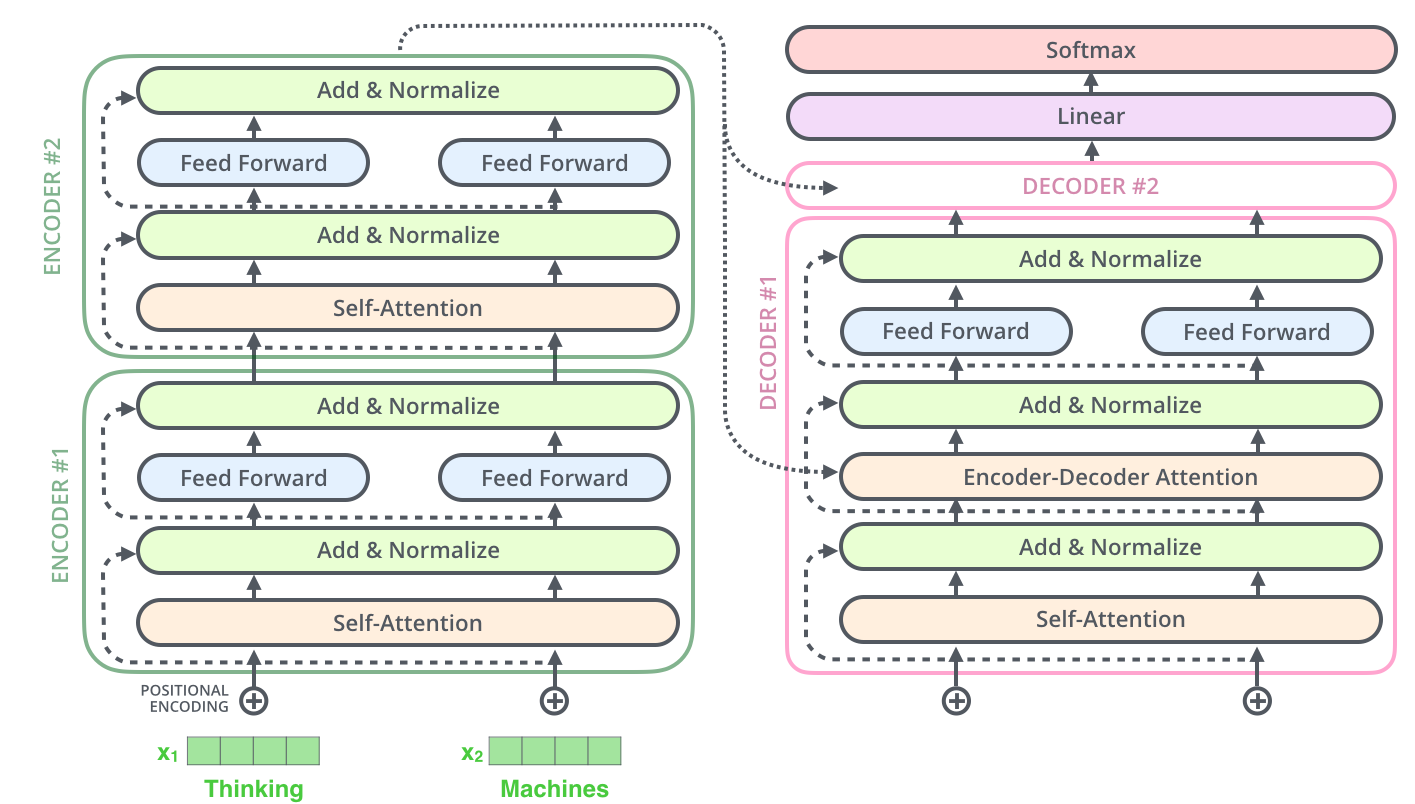
Position-wise Feed Forward Networks
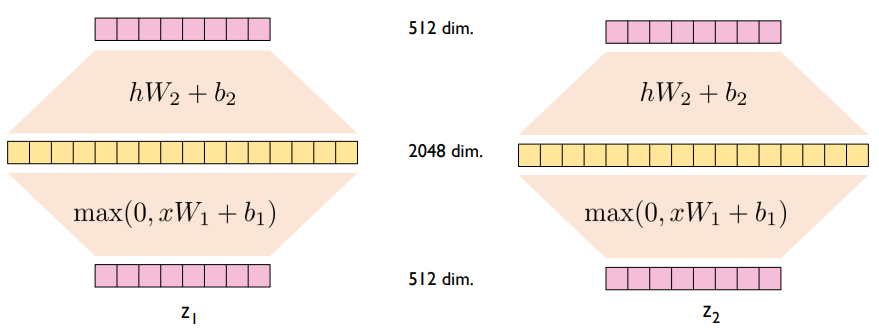
Position-wise Feed Forward Neural Networks는 각각의 position에 대해 개별적으로 수행하는 Fully Connected Feed Forward Network이다. Feed Forward Neural Networks의 linear transformation은 다음 그림에서 확인할 수 있듯이 같은 Encoder Blcok 내에서는 같은 W1, b1, W2, b2가 각 토큰마다 동일하여 같은 구조를 가지고 있다. 그러나 첫 번째 Encoder Block과 두 번째 Encoder Block의 파라미터는 다를 수 있다. 여기서 활성화 함수로 ReLU 함수가 사용되는 것을 확인할 수 있다.
Masked Multi-Head Attention
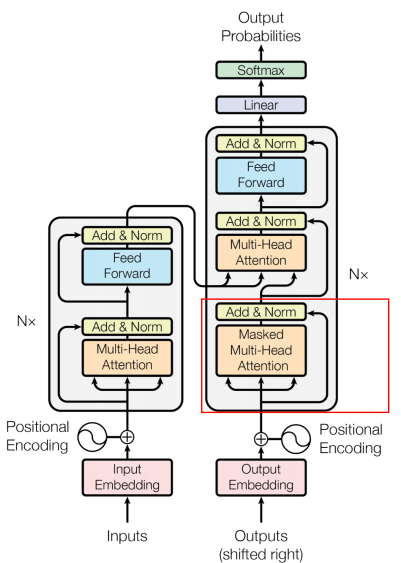
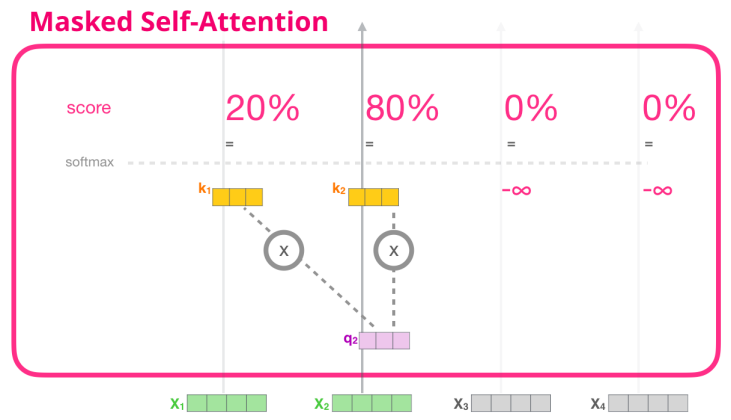
Decoder에선 Self-Attention은 반드시 output sequence보다 앞쪽(earlier)에 해당하는 토큰들에만 Attention Score를 볼 수 있으며, 이에 해당하지 않는 position들은 Masking을 적용한다. 즉, Attention Score을 계산한 뒤 softmax를 적용하기 이전에 이 값을 -무한대(-inf)로 변경한다.

Multi-Head Attention with Encoder Outputs
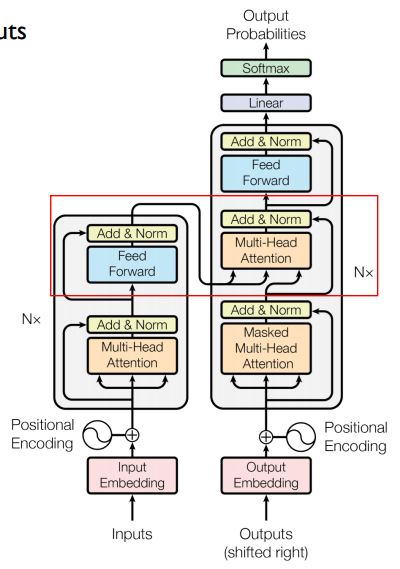
Multi-Head Attention with Encoder Outputs는 Encoder의 Outputs과 Decoder의 Masked Multi-Head Attention을 한 번 통과한 값 사이의 Multi-Head Attention이다. 이는 t 시점의 예측에 도움이 되는 Encoder의 Outputs들만 이용하고자 하는 목적이다. 여기서 Encoder를 거쳐 나온 Outputs의 Key와 Value와 Decoder의 Masked Self-Attention을 거친 값이 Query가 되어 Attention Score를 계산하며 Multi-Head Attention을 수행한다.
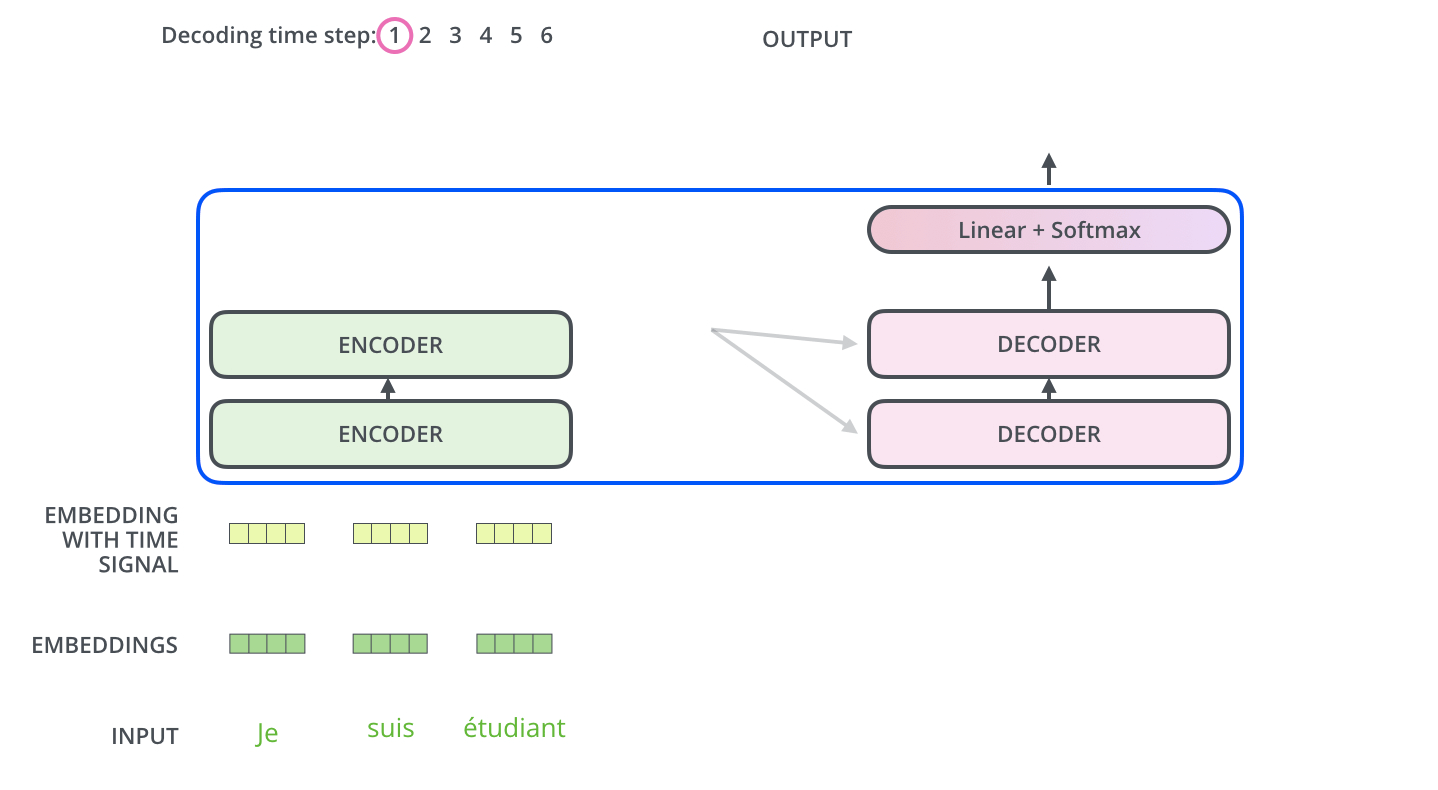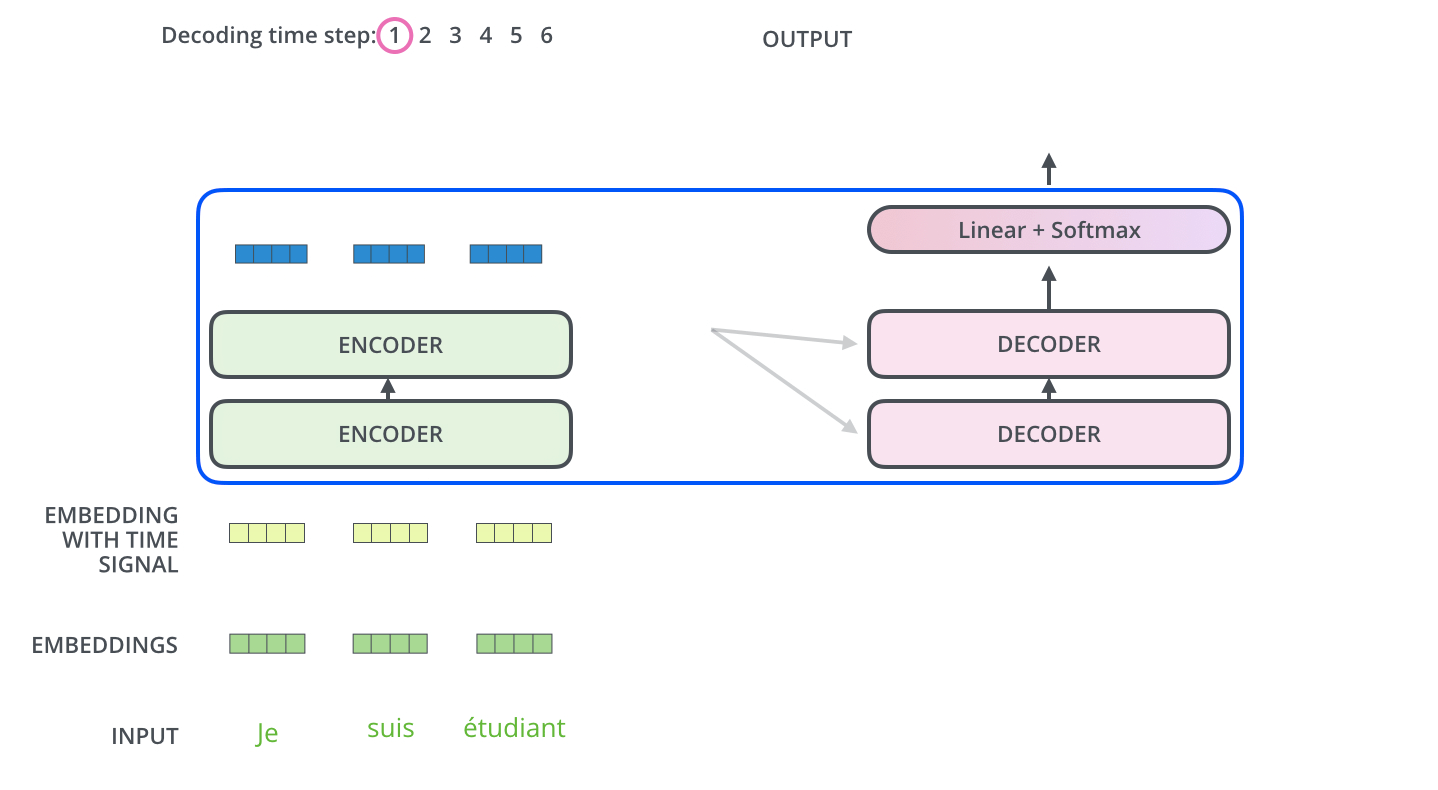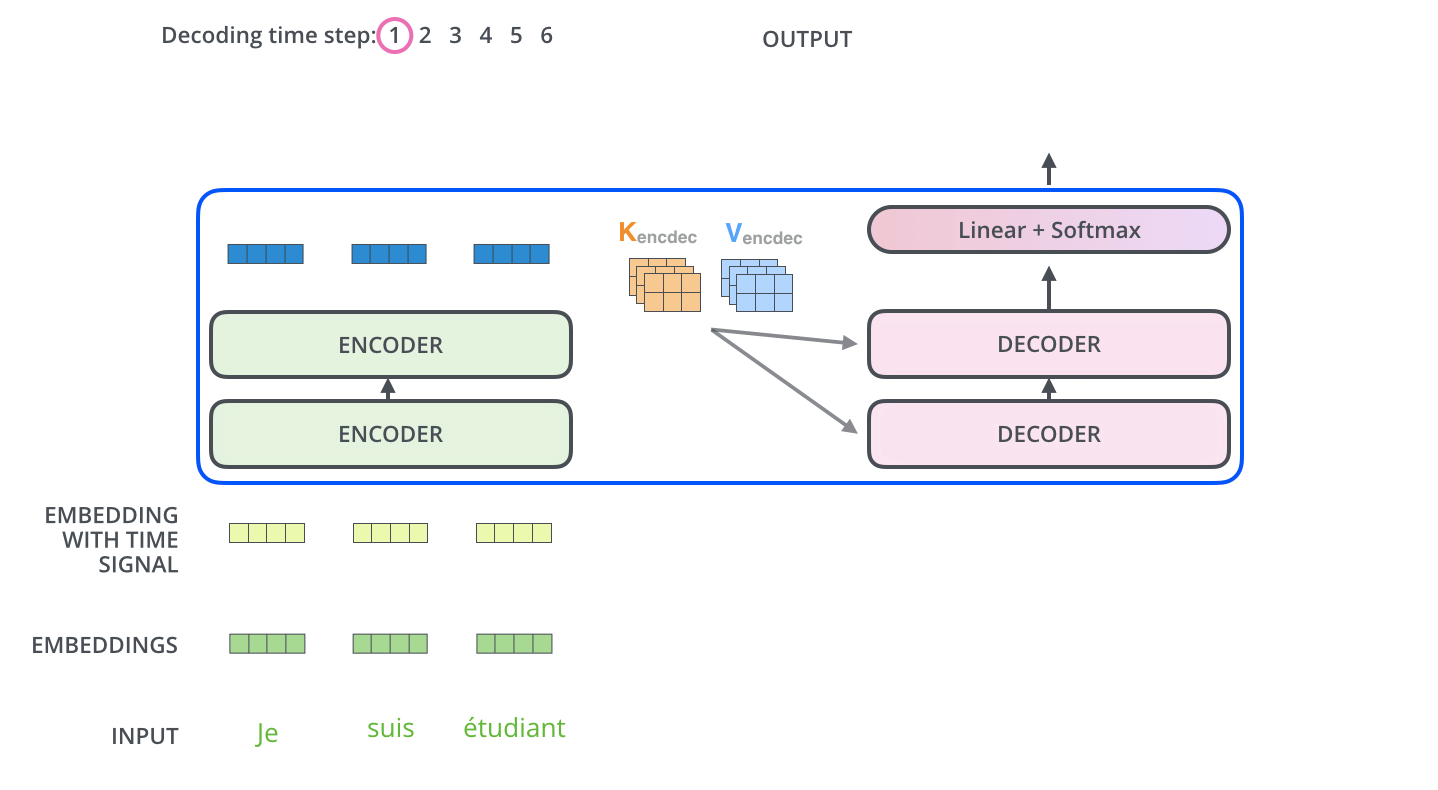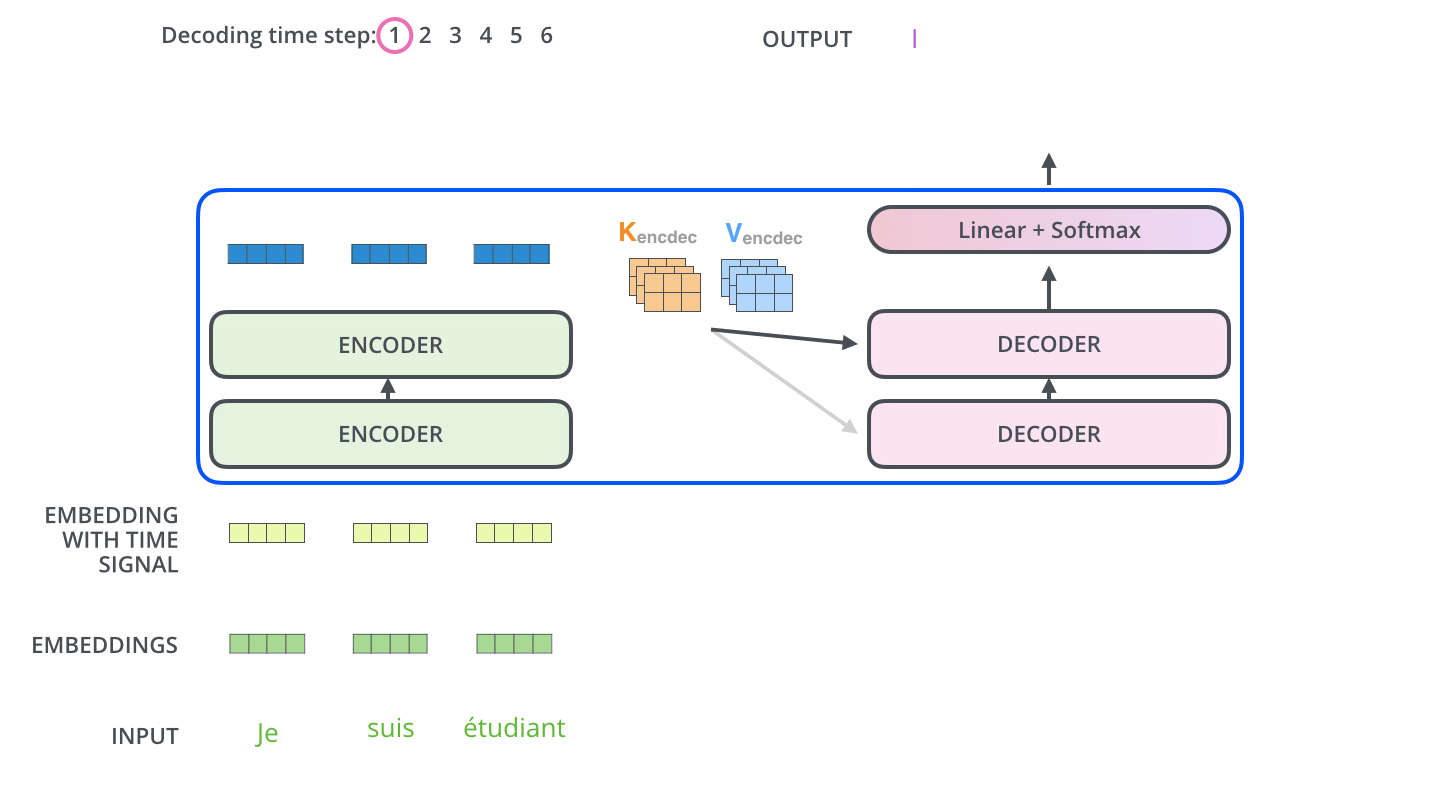
다음 Time step에선 전 step에서의 Outputs을 입력 값으로 Decoder에서 Masked Multi-Head Attention을 수행하고 또다시 Encoder의 Key, Value를 활용해 동일하게 Outputs을 생성해낸다. 여기서 Masking의 특성을 가지는 Decoder이기 때문에 Sequential하게 데이터가 입력되는 것을 확인할 수 있다.
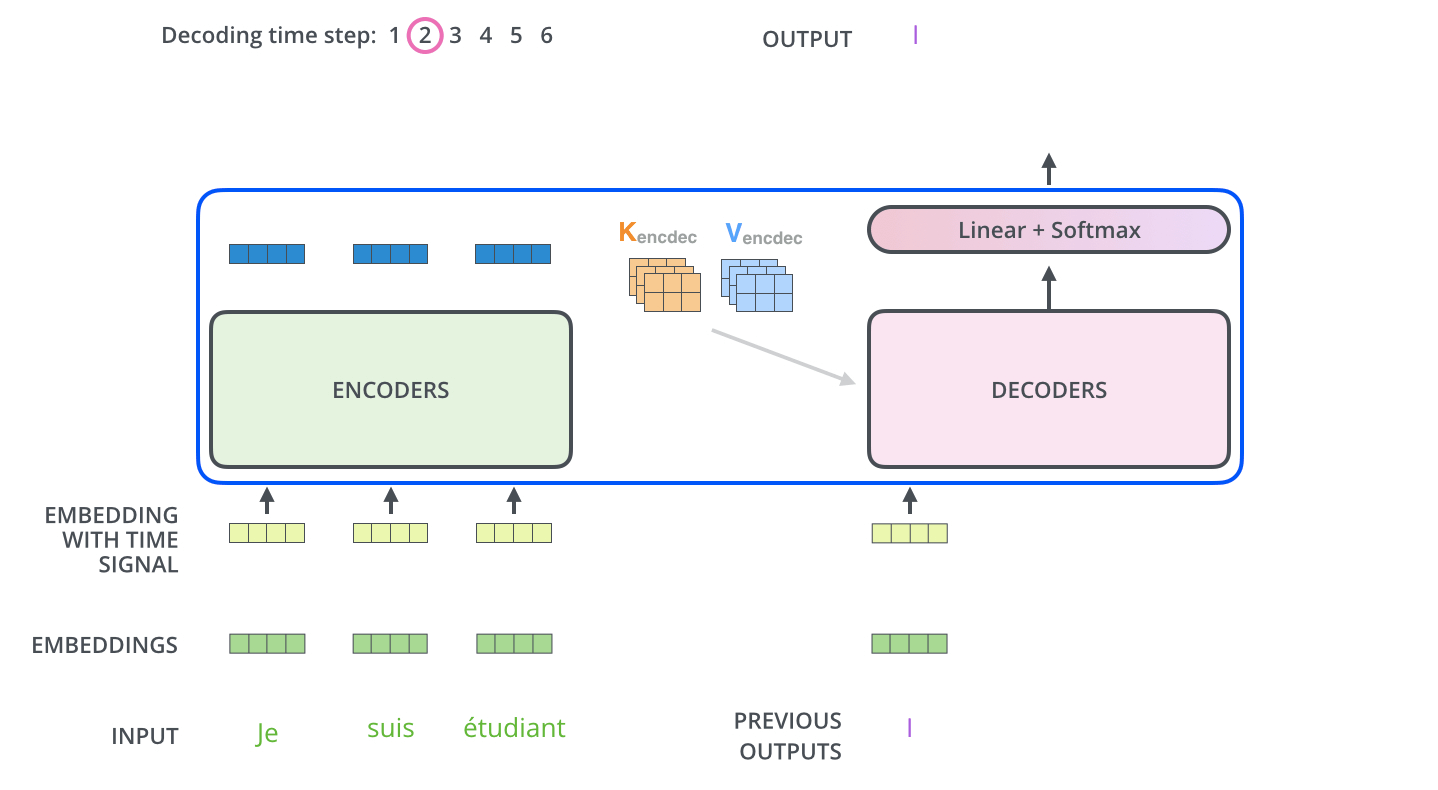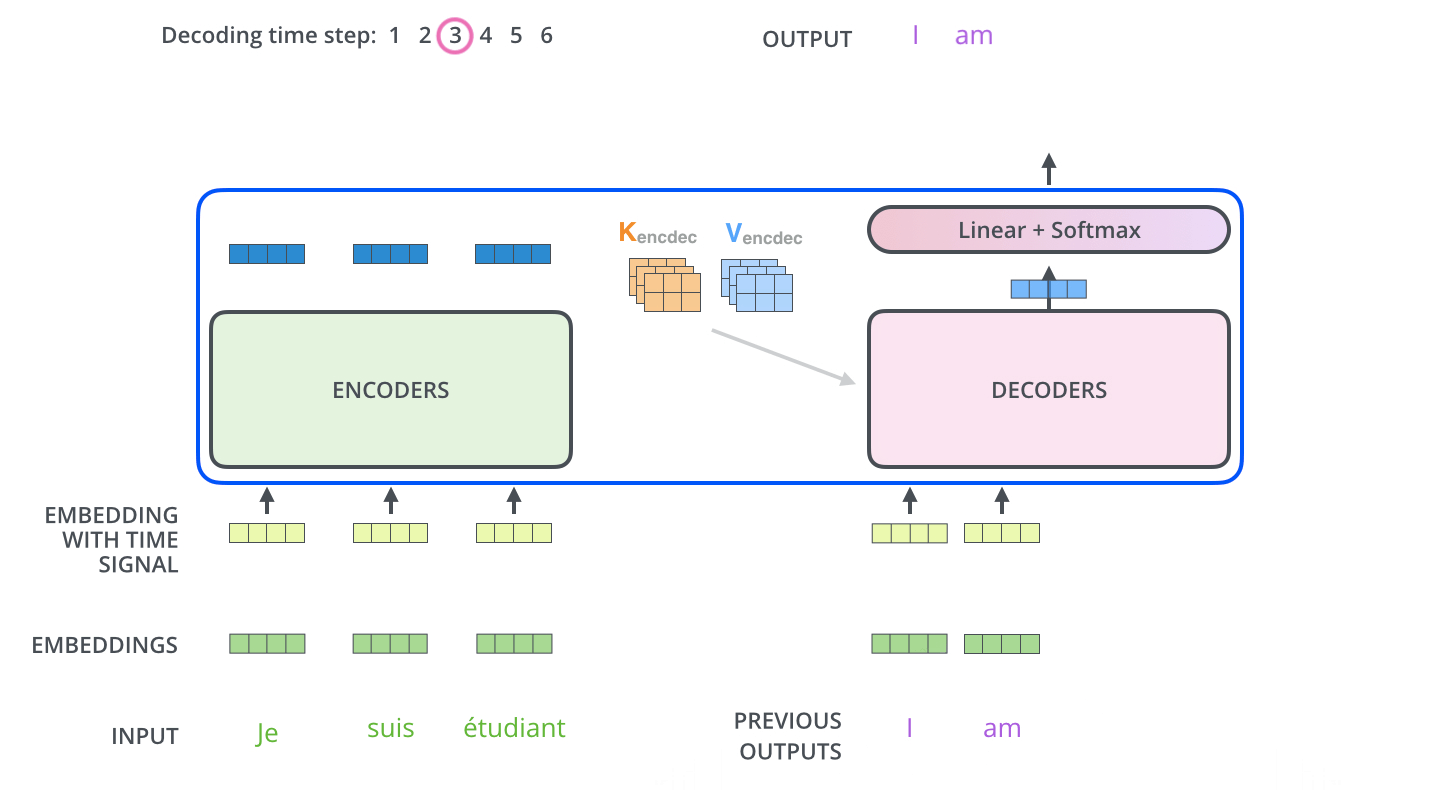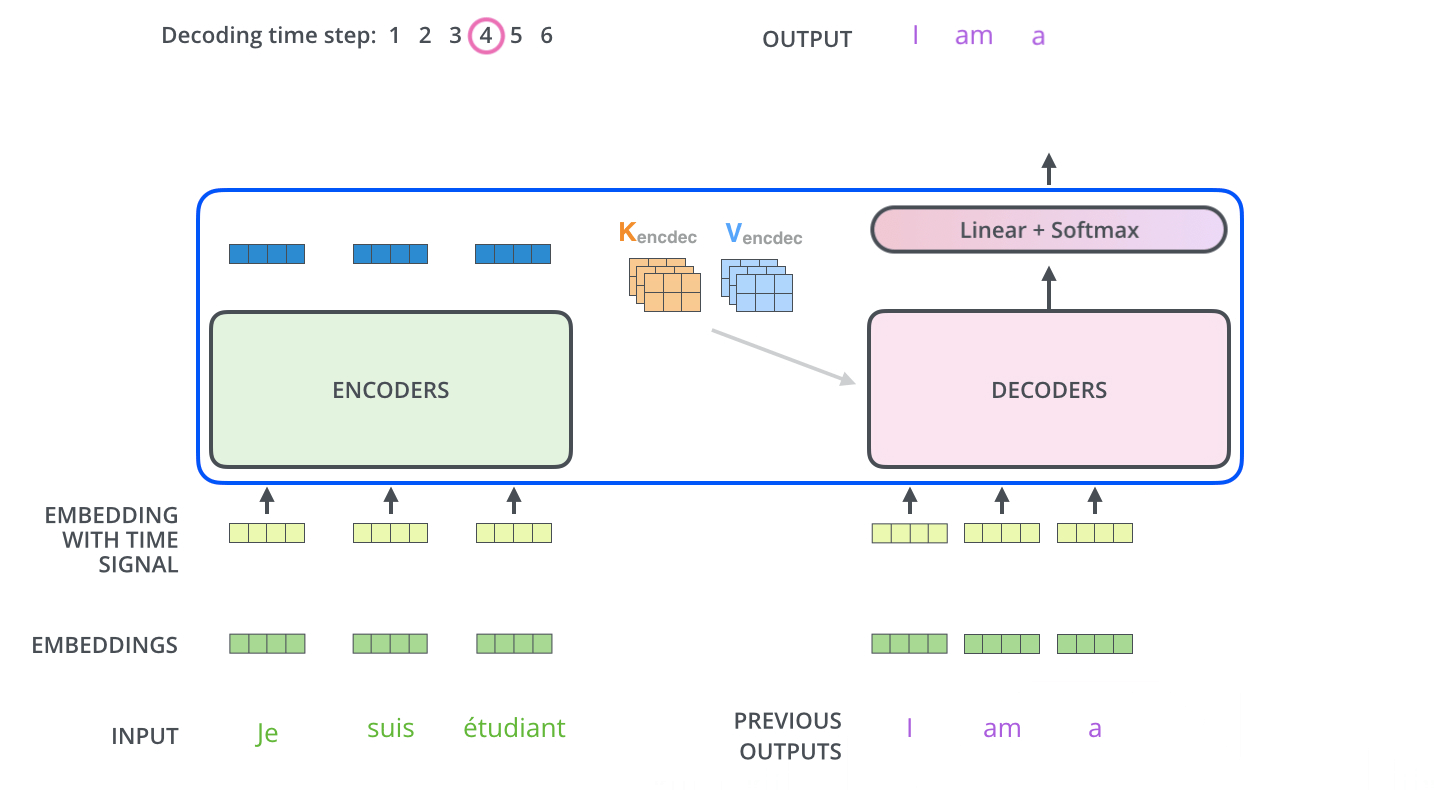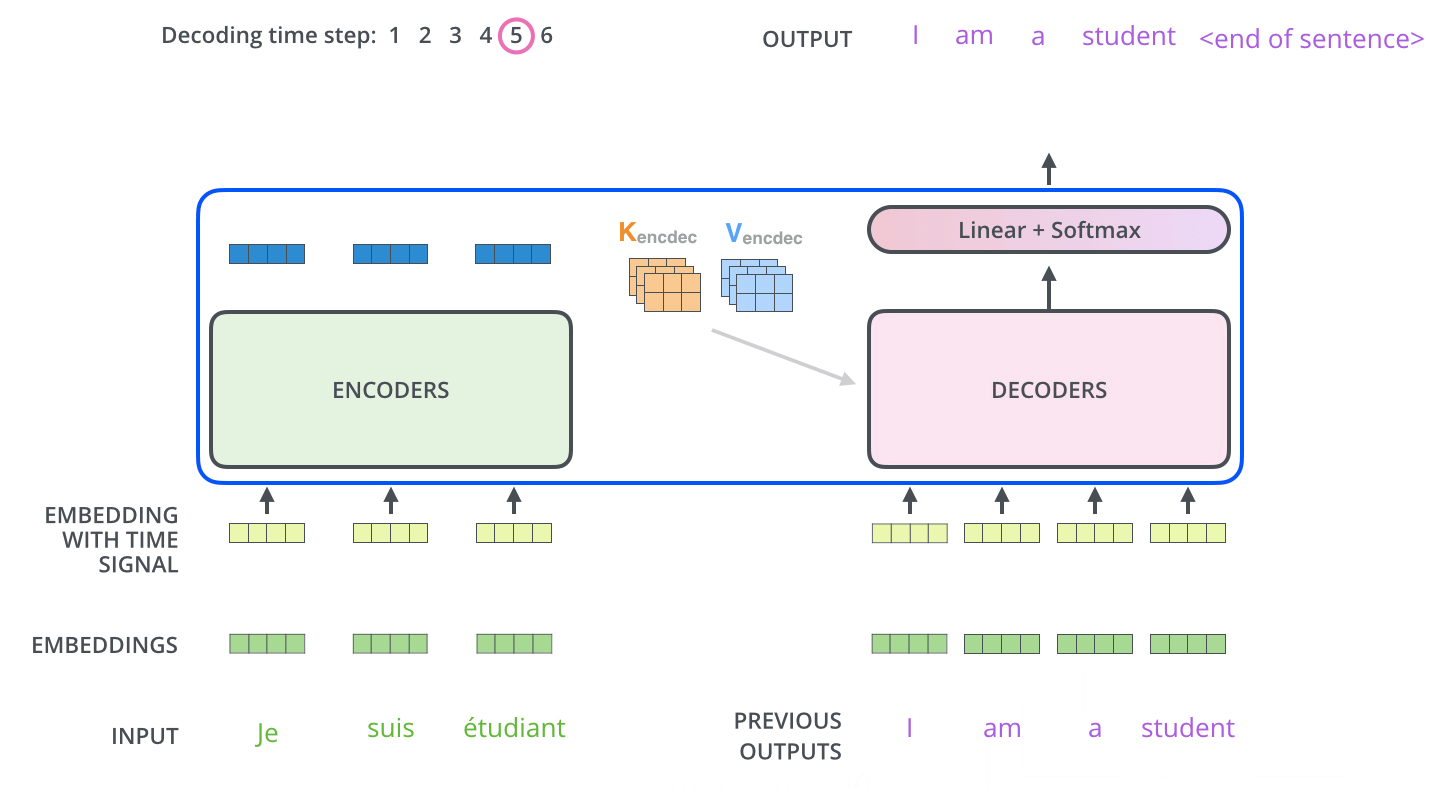
따라서 Tranformer에선 3가지의 Attention이 수행된다.
- Encoder 내에서의 Self-Attention
- Decoder 내에서의 Masked Self-Attention
- Encoder의 Outputs과 Decoder 사이의 Attention
The Final Linear and Softmax Layer
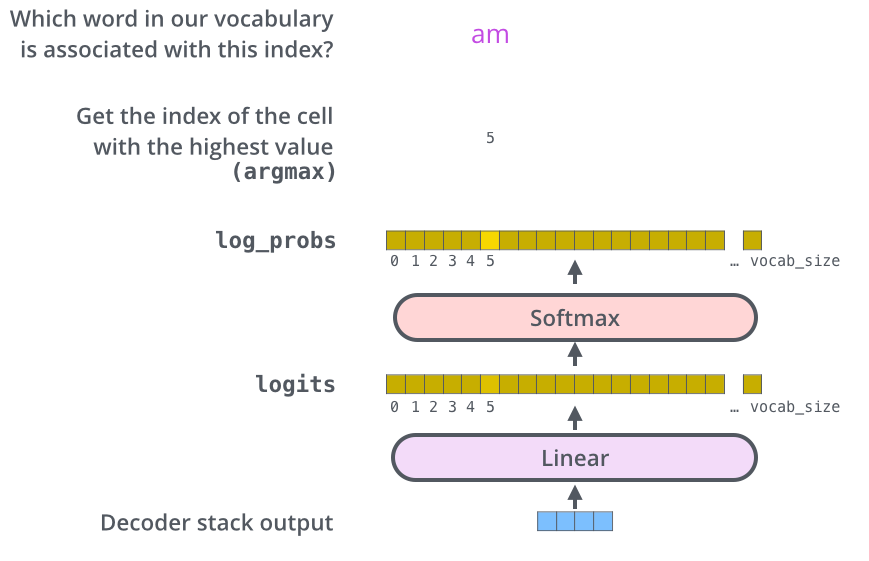
Linear layer: 단순한 Fully-Connected Layer로,logits vector라고 불리는 거대한 벡터로 Linear 연산 수행Softmax layer: logits vector를 확률값으로 변환하여 Outputs 생성
이 포스팅은 다음을 공부하며 작성한 글입니다.
Transformer
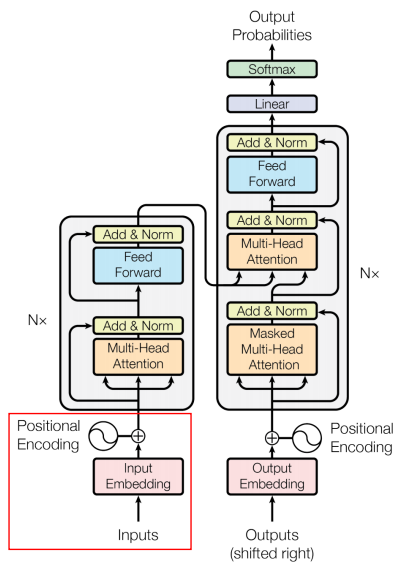
Transformer는 Attention을 사용하면서 학습과 병렬화를 쉽게 하여 속도를 높인 모델이다. Transformer는 Seq2Seq 모델과 같이 순차적으로 input 토큰을 처리하는 것이 아니라 이를 한꺼번에 처리한다.Transformer 모델의 기본적인 구조는 다음과 같다.
Transformer 모델을 signle black box와 같이 표현하면 다음과 같다. 이는 RNN 기반의 Encoder-Decoder 구조와 Input과 Output은 동일하다. 또한 Transformer를 자세히 들여다 보면 Encoding component와 Decoding Component가 따로 존재하며, 이를 어떻게 연결하는지가 결국 RNN 구조와의 차이점이다.
Encoder-Decoder
여기서 Encoding Component는 Encoder를 여러 개 쌓은 것이며, 논문에선 6개의 Encoder를 쌓았다. 6개를 쌓은 데에는 다른 이유는 없는 것으로 나타난다. Decoding Component 또한 Decoder를 Encoder와 같은 개수로 쌓은 것이다.
Encoder block과 Decoder block의 차이점은 Encoding의 경우 순차적일 필요가 없기 때문에 한꺼번에 모든 시퀀스를 다 사용하는 Unmasked에 해당하며, Decoding은 시퀀스를 생성하는 경우 순서가 중요하기 때문에 순서에 따라 masking되어 있는 Masked에 해당한다는 점이다. 아래의 예시에서 Encoder block의 경우 모든 시퀀스에 해당하는 토큰을 사용하지만, Decoder block에서는 4번째 단어를 생성할 시 orders 이후의 토큰들은 masking된다.
Encoder에 경우 2개의 sub-layers로 구성된다. 먼저 Self-Attention layer에서는 하나의 토큰에 대한 정보를 처리하기 위해서 함께 주어진 다른 토큰들을 얼마만큼 중요하게 볼지 결정한다. 이후 Feed Forward Neural Network layer에선 Self-Attention의 output에 해당하는 토큰들을 Feed Forward Neural Network에 전달하여 최종 Output을 산출한다.
Decoder은 3가지의 sub-layers로 구성된다. 먼저 Self-Attention layer를 통해 자기 자신들끼리 Self-Attetion을 수행하고, Encoder-Decoder Attention layer를 통해 Self-Attention의 Output과 Encoder에서 가지고 온 정보들과의 Attention을 수행한다. 이는 Encoder에서 주어지는 정보들을 어떻게 반영할 것인지를 결정한다. 마지막으로 Feed Forward Neural Network layer를 통해 최종적인 Decoder의 Output을 산출한다.
Input Embeddings
Input Embedding이란 Transformer 모델에 처음 들어가는 벡터 형태의 정보이다. 여러 가지 embedding 알고리즘들(GloVe, FastText, word2vec 등)을 통해 input word를 각각 512차원의 벡터의 형태로 바꿔준다. 여기서 embedding은 bottom-most encoder, 제일 첫번째 Encoder의 입력으로만 사용된다. 나머지 Encoder의 경우 이전 Encoder의 Output을 입력으로 사용한다. 여기서 사이즈는 모두 유지된다. 여기서 한 시퀀스의 길이를 최대 몇 개까지 사용할지에 대한 부분은 지정해주어야 할 하이퍼 파라미터이다.
Positional Encoding
앞서 보았듯이 Transformer는 한번에 전체 시퀀스를 통으로 입력한다. 이 경우 어떤 단어가 몇 번째 위치에 있는지에 대한 정보가 손실될 수 있다. 따라서 Positional Encoding과정을 통해 Encoding vector를 Input Embedding에 더하여 각 단어가 가지고 있는 위치 정보를 완벽하진 않지만 어느 정도 보전한다.
Encoding procedure
단어들에 대한 Embedding 과정이 끝난 후 각 포지션에 있는 단어들은 각자의 path를 따라 각각 Encoder의 2 layers로 입력된다. 여기서 Self-Attention layer의 경우 현재 processing 중인 단어의 의미를 파악하고 동일한 input sequence에 주어진 다른 단어들을 살펴보는 역할을 하기 때문에 각 토큰들은 종속 관계에 있으며 서로 영향을 끼친다. 각 path별로 각 토큰들의 Self-Attention이 끝나고 생성된 Output은 Feed Forward Neural Network에 입력된다. 여기서 같은 Encoder 내의 각 Feed Forward Neural Network들의 structure(hidden layer의 개수, hidden layer 내 뉴런의 개수 등) 및 weight는 동일하며, 다른 Encoder에서의 structure와 weight는 다르다. Feed Forward Neural Network에서 각 토큰들은 독립 관계에 있으며 이를 통해 parallelization이 가능하게 된다. Feed Forward Neural Network를 거친 Output은 첫 번째 Encoder의 Output이 되며, 곧 두 번째 Encoder의 Input으로 활용된다.
Self-Attention in Detail
Self-Attention 과정을 디테일하게 살펴보겠다. 먼저, 각각의 input vector에 대하여 3종류의 벡터 Query, Key, Value를 생성한다. Query는 현재 보고 있는 단어를 대표하는 벡터로 다른 단어들의 key와의 scoring을 위한 기준이다. 이는 현재 processing하고 있는 단어의 Query만 다루게 된다. Key는 현재 단어와 관련 있는 단어를 찾을 때 각 단어들의 label과 같은 벡터이다. Value는 실제 각 단어별 값을 포함하는 벡터이다. 이러한 Query와 Key를 통해서 가장 적절한 value를 찾아서 연산을 수행한다.
또한 이러한 벡터들은 우리가 학습을 통해 찾아야할 파라미터인 Wq, Wk, Wv와 Input Embedding 간의 곱을 통해 생성된다. 이렇게 생성된 새로운 벡터 Q, K, V는 embedding vector보다 차원이 작다. 이는 향후 Multi-Head Attention을 수행하기 위함으로 만약embedding vector의 차원이 512라면, Q, K, V 벡터는 64차원이며 이후 Multi-Head Attention에 해당하는 8을 곱해 차원을 맞춘다.
두 번째는 특정 포지션의 단어를 encoding 하기 위해 input sentence의 어떤 다른 파트를 집중할지에 대한 score를 계산하는 것이다. 이는 Query 벡터와 각 Key벡터에 대한 dot product(내적)으로 생성한다.
세 번째 단계로 이를 key vector의 차원의 제곱근으로 나누어준다. 이는 gradients를 더 안정적으로 만들어준다. 네 번째론 이 값에 softmax 함수를 실행하여 현재 position에 해당하는 이 단어가 현재 보고 있는 토큰에 얼마나 중요한 역할을 하는가를 softmax score를 통해 표현한다.
다섯 번째 단계로 이 softmax score와 value vector를 곱해주고, 마지막으로 각 단어별로 계산한 weighted value 값을 더해 해당 position에서의 최종 Output을 생성한다.
이러한 총 Self-Attention의 6단계 과정을 구체적인 예시로 보면 다음과 같다.
Self-Attention에는 여러 Matrix calculation이 나타나는데, 이는 다음과 같다.
추가적으로 Self-Attention를 또다른 형태로 표현하면 다음과 같다.
Multi-Head Attention / Residual connection & Normalization
Multi-Head Attention
Multi-Head Attention은 Single Attention을 전부 다르게 8개를 만들어 생성된 각 Z 값을 활용하는 방법이다. 이를 위하여 각 Single Attention에서 생성된 Z 값들을 concatenated한 후, 모델 학습 과정에서 찾는 새로운 파라미터인 Wo와의 multiplied를 통해 향후 Feed Forward Neural Network에 활용될 Input을 생성한다. 이렇게 생성된 Z는 처음 Input Embedding과 동일한 차원의 Self-Attention Output이다.
Multi-Head Attention의 전체적인 과정은 다음과 같이 표현할 수 있다. 해당 그림에서 R은 이전 Encoder의 Output으로 Original Input Embedding과 차원이 동일하다.
다음은 실제 Multi-Head Attention의 예시로 각 Single Attention마다 Output이 다르게 나타나는 것을 색으로 확인할 수 있다.
Residual connection & Normalization
Residual이란 원래 식에 자기 자신을 더해줌으로써 미분 이후 gradient가 매우 작아도 최소 1이 더해지는 형태로 만들어 학습에 유리하게 한다. 이러한 Redisual connection과 Layer-Normalization은 각 Encoder 내 Self-Attention과 Feed Forward Neural Network 이후에 존재한다.
또한 이는 Decoder에도 적용된다.
Position-wise Feed Forward Networks
Position-wise Feed Forward Neural Networks는 각각의 position에 대해 개별적으로 수행하는 Fully Connected Feed Forward Network이다. Feed Forward Neural Networks의 linear transformation은 다음 그림에서 확인할 수 있듯이 같은 Encoder Blcok 내에서는 같은 W1, b1, W2, b2가 각 토큰마다 동일하여 같은 구조를 가지고 있다. 그러나 첫 번째 Encoder Block과 두 번째 Encoder Block의 파라미터는 다를 수 있다. 여기서 활성화 함수로 ReLU 함수가 사용되는 것을 확인할 수 있다.
Masked Multi-Head Attention
Decoder에선 Self-Attention은 반드시 output sequence보다 앞쪽(earlier)에 해당하는 토큰들에만 Attention Score를 볼 수 있으며, 이에 해당하지 않는 position들은 Masking을 적용한다. 즉, Attention Score을 계산한 뒤 softmax를 적용하기 이전에 이 값을 -무한대(-inf)로 변경한다.
Multi-Head Attention with Encoder Outputs
Multi-Head Attention with Encoder Outputs는 Encoder의 Outputs과 Decoder의 Masked Multi-Head Attention을 한 번 통과한 값 사이의 Multi-Head Attention이다. 이는 t 시점의 예측에 도움이 되는 Encoder의 Outputs들만 이용하고자 하는 목적이다. 여기서 Encoder를 거쳐 나온 Outputs의 Key와 Value와 Decoder의 Masked Self-Attention을 거친 값이 Query가 되어 Attention Score를 계산하며 Multi-Head Attention을 수행한다.
다음 Time step에선 전 step에서의 Outputs을 입력 값으로 Decoder에서 Masked Multi-Head Attention을 수행하고 또다시 Encoder의 Key, Value를 활용해 동일하게 Outputs을 생성해낸다. 여기서 Masking의 특성을 가지는 Decoder이기 때문에 Sequential하게 데이터가 입력되는 것을 확인할 수 있다.
따라서 Tranformer에선 3가지의 Attention이 수행된다.
- Encoder 내에서의 Self-Attention
- Decoder 내에서의 Masked Self-Attention
- Encoder의 Outputs과 Decoder 사이의 Attention
The Final Linear and Softmax Layer
Linear layer: 단순한 Fully-Connected Layer로,logits vector라고 불리는 거대한 벡터로 Linear 연산 수행Softmax layer: logits vector를 확률값으로 변환하여 Outputs 생성
이 포스팅은 다음을 공부하며 작성한 글입니다.