신경망 학습의 의미
신경망에는 입력 데이터와 타깃 데이터가 제공될 뿐, 추론을 위한 규칙은 제공되지 않는다. 신경망을 `학습(learning)`한다는 것은 이 규칙을 학습 데이터를 이용해서 스스로 찾는 것이다. 이는 학습 데이터에 기대하는 정답이 들어있기 때문에 가능하다.
신경망에 입력 데이터가 들어왔을 때 어떤 출력 데이터를 만들어야 할지를 정하는 규칙은 함수적 매핑 관계로 표현된다. 가중 합산과 활성 함수가 연결되어 뉴런을 구성하고, 뉴런이 모여 계층을 구성하며, 계층이 쌓여서 신경망의 계층 구조가 정의된다. 이러한 복잡한 신경망의 계층 구조 자체가 신경망의 함수적 매핑 관계를 표현하는 것이다.
신경망의 학습 과정에서 함수적 매핑 관계를 표현하는 전체 계층 구조를 찾아야 하는 것은 아니다. 신경망의 구조와 관련된 것들은 학습 전에 미리 정해두고, 학습 과정에서는 `모델 파라미터(model parameter)`의 값을 찾는다. 뉴런의 연결 강도를 결정하는 가중치와 편향은 모델 파라미터의 대부분을 차지한다. 그 외에 활성 함수, 모델 구조와 관련된 파라미터들, 정규화 기법과 관련된 파라미터들, 모델 학습과 관련된 파라미터들이 모델 파라미터에 포함될 수 있다.
신경망 학습에서 최적의 파라미터 값을 찾아낼 때는 `최적화(Optimization)` 기법을 사용한다. 최적화 기법은 함수의 해를 근사적으로 찾는 방법으로, 신경망이 관측 데이터를 가장 잘 표현하는 함수가 되도록 만들어준다.
신경망 학습과 최적화
최적화란?
최적화란 유한한 방정식으로 정확한 해를 구할 수 없을 때 근사적으로 해를 구하는 방법으로, 다양한 제약 조건을 만족하면서 목적 함수를 최대화하거나 최소화하는 해를 반복하여 조금씩 접근하는 방식으로 찾아가는 방법이다. 이를 수학적으로 다음과 같은 표준 형태로 정의한다.
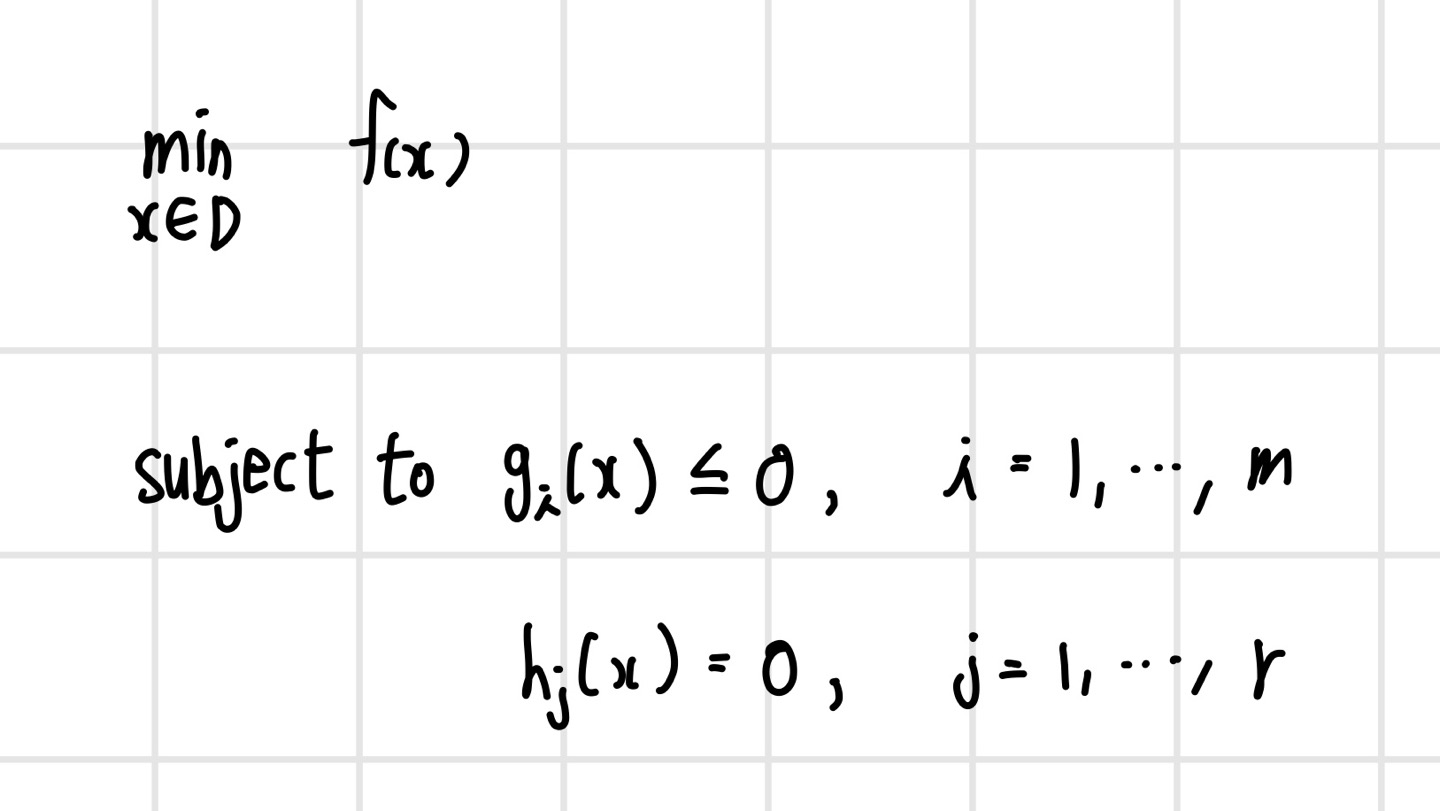
최적화 문제는 `목적 함수(objective function)` f(x)와 여러 `제약 조건(constraints)`으로 이루어진다. 제약 조건은 부등식 형태와 등식 형태의 제약 조건으로 구분된다. 표준 최적화 문제는 '변수 x에 대한 등식과 부등식으로 표현되는 여러 제약 조건을 만족하면서 목적 함수인 f(x)를 최소화하는 x의 값을 찾는 문제'로 풀어서 이야기할 수 있다. 최적화를 통해 찾은 x의 값을 `최적해(optimal solution)`이라고 하며, 최적해에 점점 가까이 가는 상태를 `수렴한다(converge)`고 하고 최적해를 찾으면 '수렴했다'라고 표현한다.
최적화 문제는 표준 형태와 같이 반드시 최소화 문제일 필요는 없다. 둘 중 문제를 더 잘 표현할 수 있는 방식을 선택하면 된다. 또한 목적 함수의 부호만 바꿔주면 최소화 문제는 최대화 문제가 되고 최대화 문제는 최소화 문제가 될 수 있기 때문에 쉽게 변화가 가능하다. 최소화 문제에서 목적 함수는 `비용 함수(cost function)` 혹은 `손실 함수(loss function)`이라고 부르며, 최대화 문제에서는 `유틸리티 함수(utility function)`라고 부른다.
신경망 학습을 위한 최적화 문제 정의
회귀 문제는 '타깃과 예측값의 오차를 최소화하는 파라미터를 찾으라'라는 최적화 문제로 다음과 같이 정의할 수 있다. 회귀 문제에서 손실 함수는 `평균제곱오차(MSE : Mean Square Error)`로 정의되며 타깃과 예측값의 오차를 나타낸다. 기본 회귀 문제는 제약 조건이 없지만, 정규화 기법이 적용되거나 문제가 확장되면 제약 조건이 추가될 수 있다.

분류 문제는 확률 모델의 관점에서 '관측 확률분포와 예측 확률분포의 차이를 최소화하는 파라미터를 찾으라'라는 최적화 문제로 다음과 같이 정의할 수 있다. 분류 문제에서 손실 함수는 `크로스 엔트로피(cross entroy)`로 정의되며, 타깃의 확률분포와 모델 예측 확률분포의 차이를 나타낸다. 기본 분류 문제는 제약 조건이 없지만, 정규화 기법이 적용되거나 문제가 확장되면 제약 조건이 추가될 수 있다.

최적화 문제를 통한 신경망 학습
신경망 학습을 위한 최적화 문제가 정의되었다면, 최적화를 통해 신경망 학습을 수행한다. 최적화는 손실 함수의 최소 지점을 찾아가는 과정이다. 즉, 손실 함수의 임의의 위치에서 출발해서 최적해가 있는 최소 지점을 찾아가는 과정을 최적화 과정이라고 한다. 최적해를 찾기 전에는 어디에서 출발해야 좋을지 알 수 없다. 따라서 최적화 알고리즘은 어느 위치에서 출발하든 손실 함수의 최소 지점으로 갈 수 있어야 한다.
경사 하강법
신경망의 학습 목표
신경망의 손실 함수는 차원이 매우 높고 복잡한 모양이기 때문에 최적화가 어렵다. 손실 함수에는 하나의 `전역 최소(global minimum)`와 수많은 `지역 최소(local minimum)`가 있다. 전역 최소란 함수 전체에서 가장 낮은 곳을 말하며, 지역 최소는 함수에서 부분적으로 낮은 곳을 말한다. 궁극적인 최적해는 전역 최소에 해당하는 파라미터 값이지만, 전역 최소를 찾으려면 곡면 전체 모양을 확인해야 하므로 계산 비용이 많이 들며 문제가 크고 복잡할 경우 전역 최소를 찾기 매우 어렵다. 따라서 대부분의 최적화 알고리즘의 목표는 지역 최소를 찾는 것이다. 이러한 해를 여러 번 찾아서 그중 가장 좋은 해를 선택하거나, 동시에 여러 해를 찾아서 함께 고려하기도 한다.
신경망 학습을 위한 최적화 알고리즘
일반적으로 최적화 문제는 관측 변수가 많고 `닫힌 형태(closed form)`로 정의되지 않기 때문에 함수를 미분해서 최대, 최소를 구할 수 없다. 닫힌 형태의 문제란 유한개의 방정식으로 명확한 해를 표현할 수 있는 문제를 말한다. 최적화 알고리즘은 손실 함수 곡면을 매번 근사하는데 이때 사용하는 미분의 차수에 따라 1차 미분, 1.5차 미분, 2차 미분 방정식으로 나뉜다.
- 2차 미분
- 곡률을 사용하므로 최적해를 빠르게 찾을 수 있음
- 손실 함수 곡면이 `볼록(convex)`해야만 최적해를 찾을 수있음
- 계산 비용과 메모리 사용량이 많아 신경망에서 사용하기 어려움
- 뉴턴 방법(newton method), 내부점법(interior point method)
- 1.5차 미분
- 1차 미분을 사용해서 2차 미분을 근사하는 방식으로 최적해를 빠르게 찾을 수 있음
- 신경망 학습과 별도로 2차 미분을 근사하는 알고리즘을 실행해야 하며 근사된 2차 미분값을 저장해야 하므로 메모리 사용량이 많음
- 준 뉴턴 방법(quasi-newton method), 켤레 경사 하강법(conjugate gradient descent), 레벤버그-마쿼트 방법(levenberg-marquardt method)
- 1차 미분
- 상대적으로 수렴 속도가 느림
- 손실 함수 곡면이 볼록하지 않아도 최적해를 찾을 수 있어 손실 함수 곡면이 매우 복잡한 신경망에서 안정적으로 사용 가능
- 신경망에서는 주로 1차 미분 방식인 경사 하강법과 이를 개선한 알고리즘을 사용
- 경사하강법의 변형 알고리즘 : SGD, SGD 모멘텀, AdaGrad, RMSProp, Adam
경사 하강법(Gradient Descent)
`경사 하강법(Gradient Descent)`은 손실 함수의 최소 지점을 찾기 위해 경사가 가장 가파른 곳을 찾아서 한 걸음씩 내려가는 방법이다. 현재 위치에서 경사가 가장 가파른 곳을 찾기 위해 손실 함수의 기울기를 구하고 기울기의 반대 방향으로 내려간다.
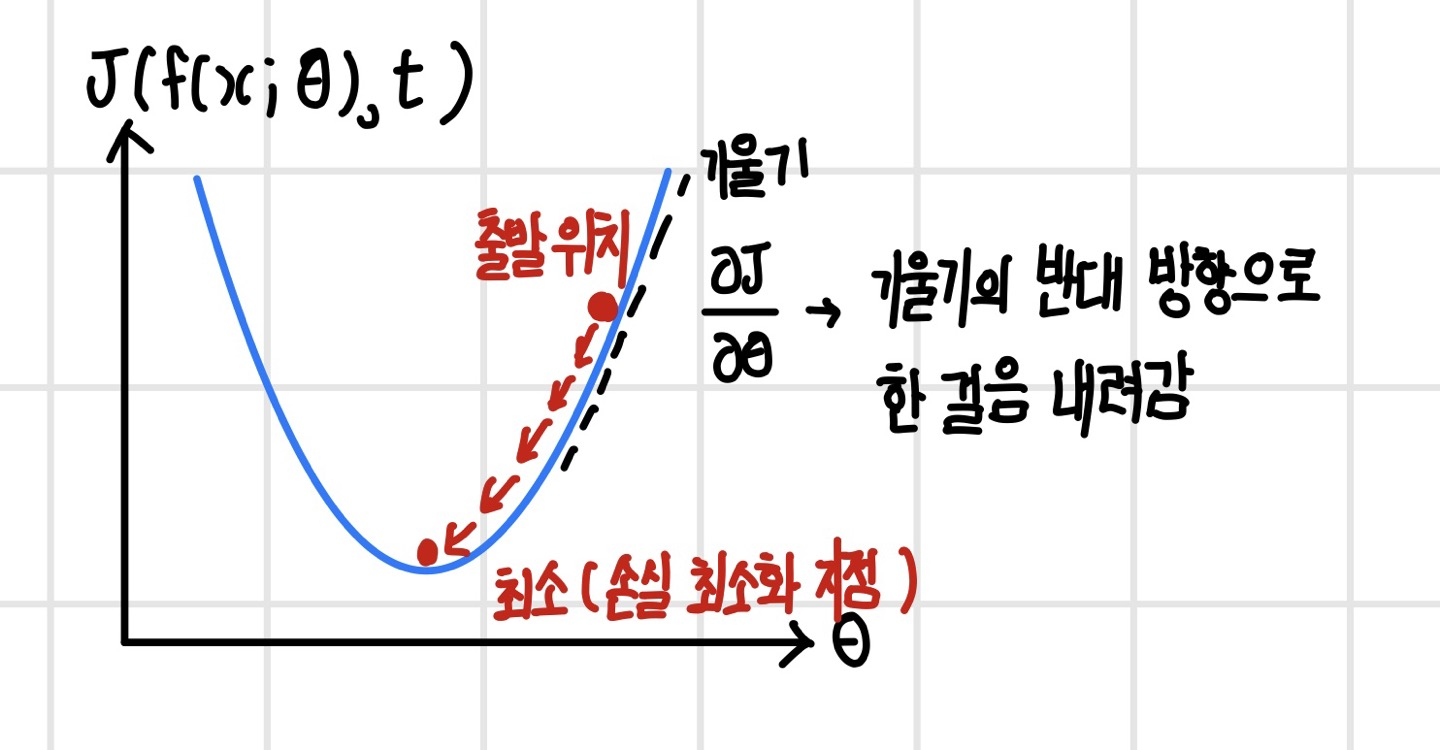
경사 하강법으로 현재 위치에서 다음 위치로 한 걸음 이동하려면 다음과 같은 파라미터 업데이트 식을 사용한다.

`그레이디언트(Gradient)`란 실수 함수의 미분을 말한다. f(x) = f(x1, x2, ..., xn)와 같이 변수 x가 n차원 벡터이고 함숫값이 실수인 경우, 입력 벡터의 요소별로 함수 f(x)를 편미분 한 벡터를 그레이디언트라고 한다. 그레이디언트는 x에서 함수 f(x)가 증가하는 방향과 증가율을 나타낸다. 신경망의 손실 함수 J는 실수 함수이고 모델의 파라미터는 벡터이기 때문에 손실 함수를 파라미터로 미분하면 그레이디언트가 된다.
신경망에 경사 하강법 적용
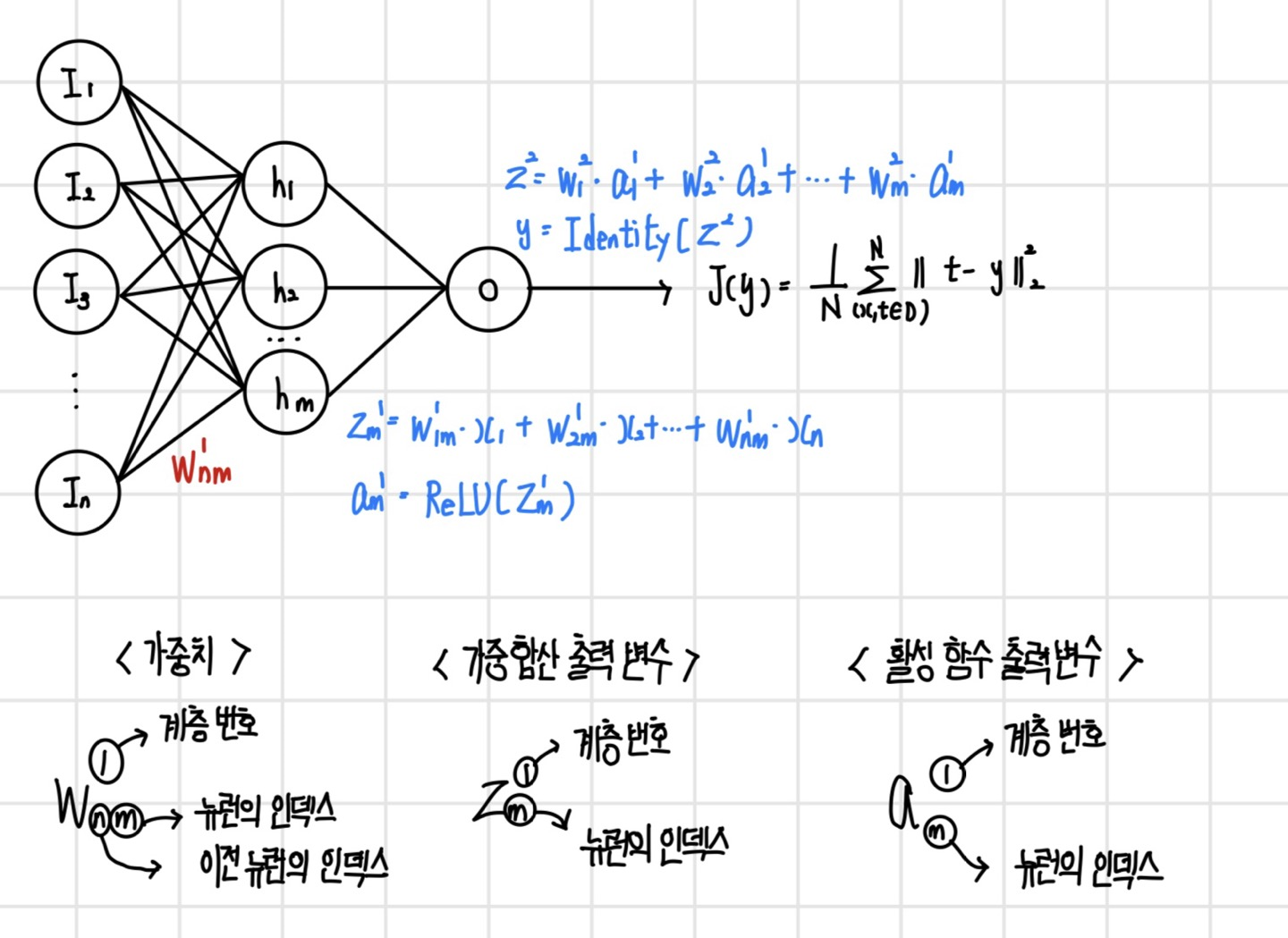
2계층 신경망 회귀 모델
다음과 같이 2계층 신경망으로 구성된 회귀 모델이 있다. 은닉 계층의 활성 함수는 ReLU이고, 회귀 모델이기 때문에 출력 계층의 활성 함수는 항등 함수이며, 손실 함수는 평균제곱오차이다.
파라미터 업데이트 식
경사 하강법을 이용하여 가중치 값을 업데이트하려면 먼저 손실 함수에 대한 가중치의 미분 값을 구해서 다음과 같이 업데이트할 수 있다.
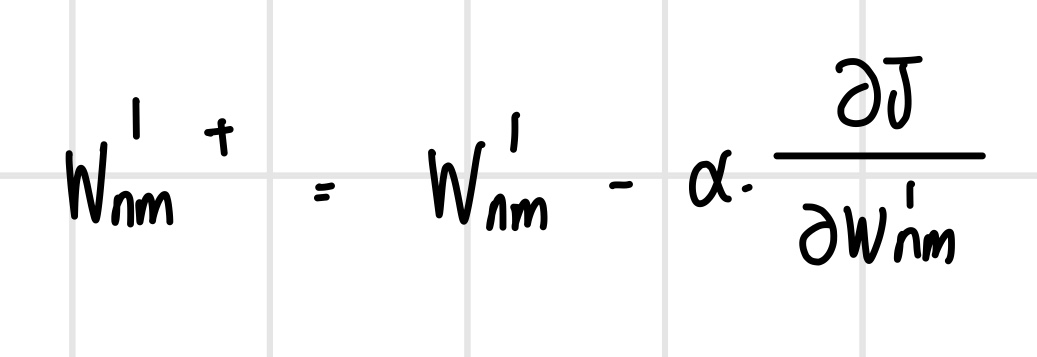
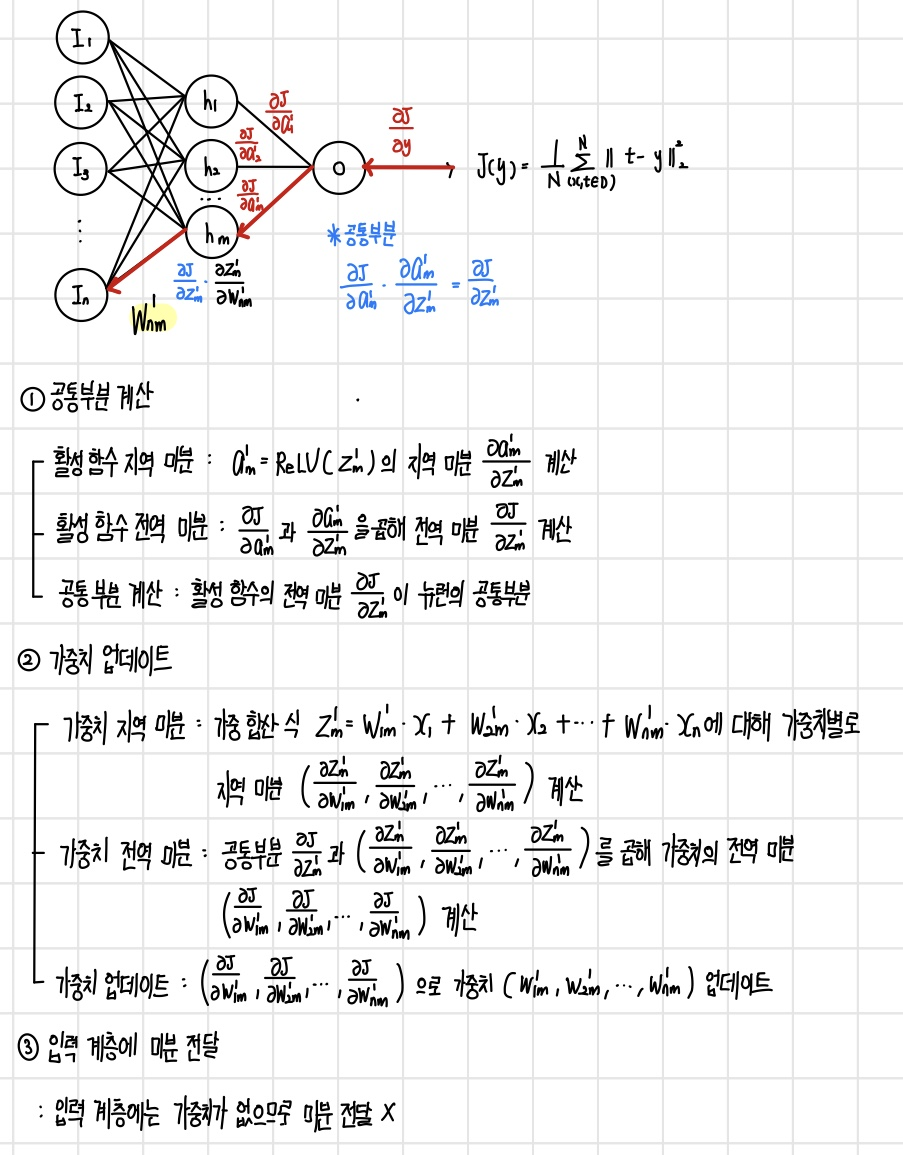
그러나 이 업데이트 식은 손실 함수의 정의에 가중치 변수가 포함되어 있지 않기 때문에 바로 계산할 수 없다. 신경망에서 가중치 변슈는 은닉 뉴런에 정의되며 출력 뉴런을 거쳐서 손실 함수에 간접적으로 영향을 미친다. 즉, 손실 함수는 합성 함수로 정의되며 합성 함수를 미분하려면 `연쇄 법칙(chain rule)`을 사용해야 한다. 연쇄 법칙을 적용하면 다음과 같다. 여기서 식 ①과 ②는 은닉 뉴런에 정의된 가중 합산과 ReLU이다. 또한 식 ③, ④는 출력 뉴런에 정의된 가중 합산과 항등 함수이며, 식 ⑤는 손실 함수이다. 손실 함수에서 가중치까지 각 함수를 거꾸로 따라가며 ⑤,④,③,②,① 순으로 미분을 계산해서 곱하면 된다.

신경망에서 연쇄 법칙으로 미분하는 과정
앞서 확인한 신경망에서 연쇄 법칙으로 미분하는 과정을 그림으로 확인해 보면, 다음과 같다. 빨간색 화살표를 따라 신경망의 역방향으로 미분을 계산해서 곱해 나간다.
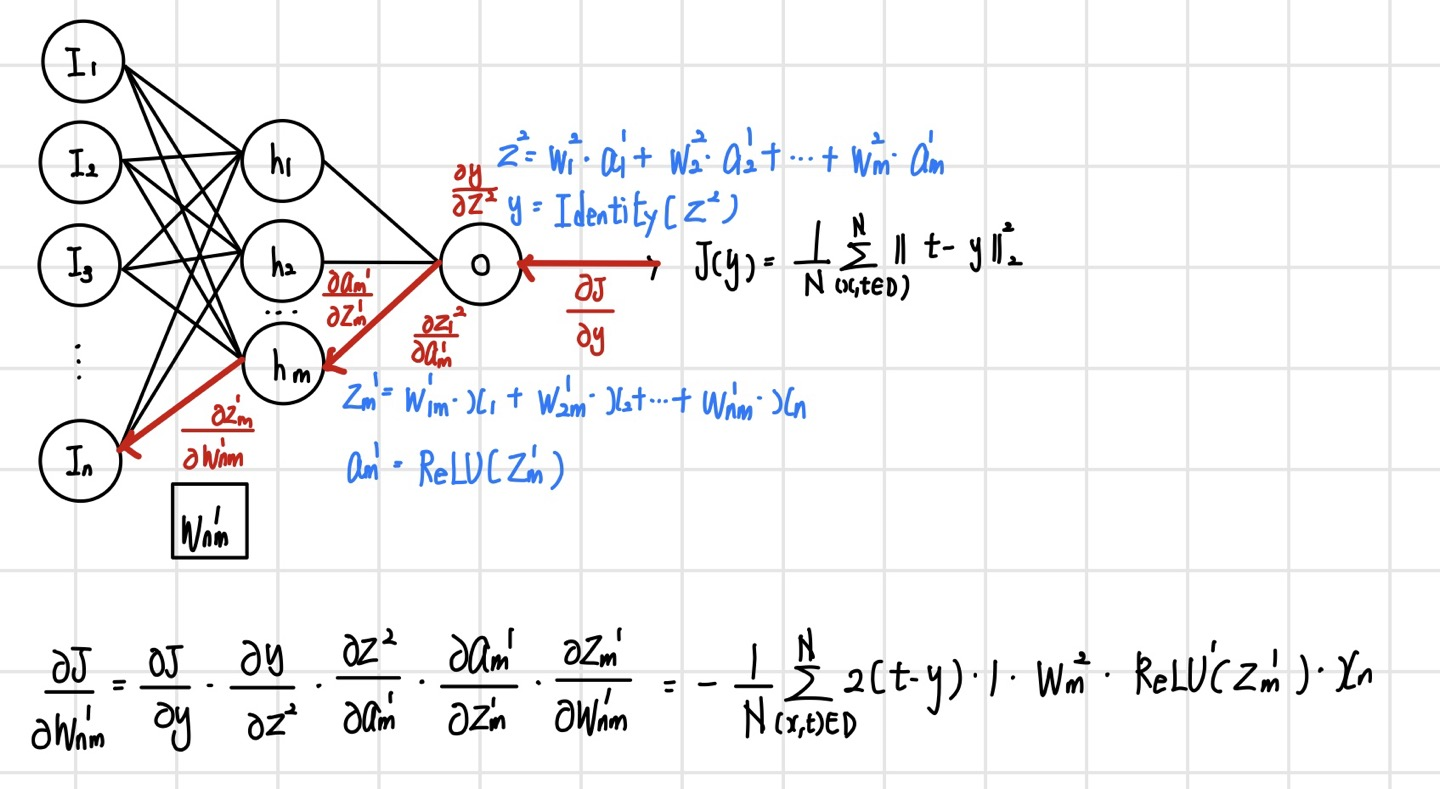
이렇게 계산된 결과를 활용하여 파라미터 업데이트 식에 적용하면 경사 하강법이 완성된다. 이러한 방식으로 모든 파라미터에 미분의 연쇄 법칙을 적용해서 경사 하강법을 적용할 수 있다.
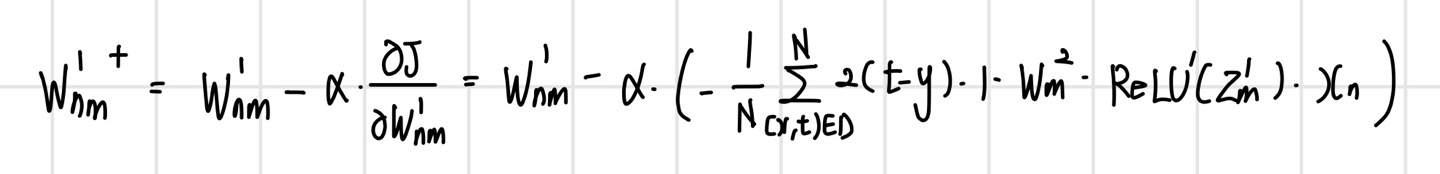
역전파 알고리즘
역전파 알고리즘
신경망에 경사 하강법을 적용할 때 손실 함수에서 각 가중치까지 신경망의 역방향으로 실행했던 함수를 따라가며 미분을 계산해서 곱했다. 만약 이 과정을 모든 파라미터에 대해 개별적으로 진행하게 되면 같은 미분을 여러 번 반복하는 비효율성 문제가 발생하며, 이러한 문제를 해결하기 위해 제안된 방법이 `역전파 알고리즘(backpropagation algorithm)`이다. 앞서 본 가중치와 또 다른 가중치에 대해 미분을 연쇄 법칙으로 표현해 보면 마지막 항을 제외한 앞부분이 동일한 것을 확인할 수 있다. 따라서 이러한 공통부분은 한 번 계산해 두면 같은 뉴런에 속한 모든 가중치의 미분을 계산할 때 재사용할 수 있다.
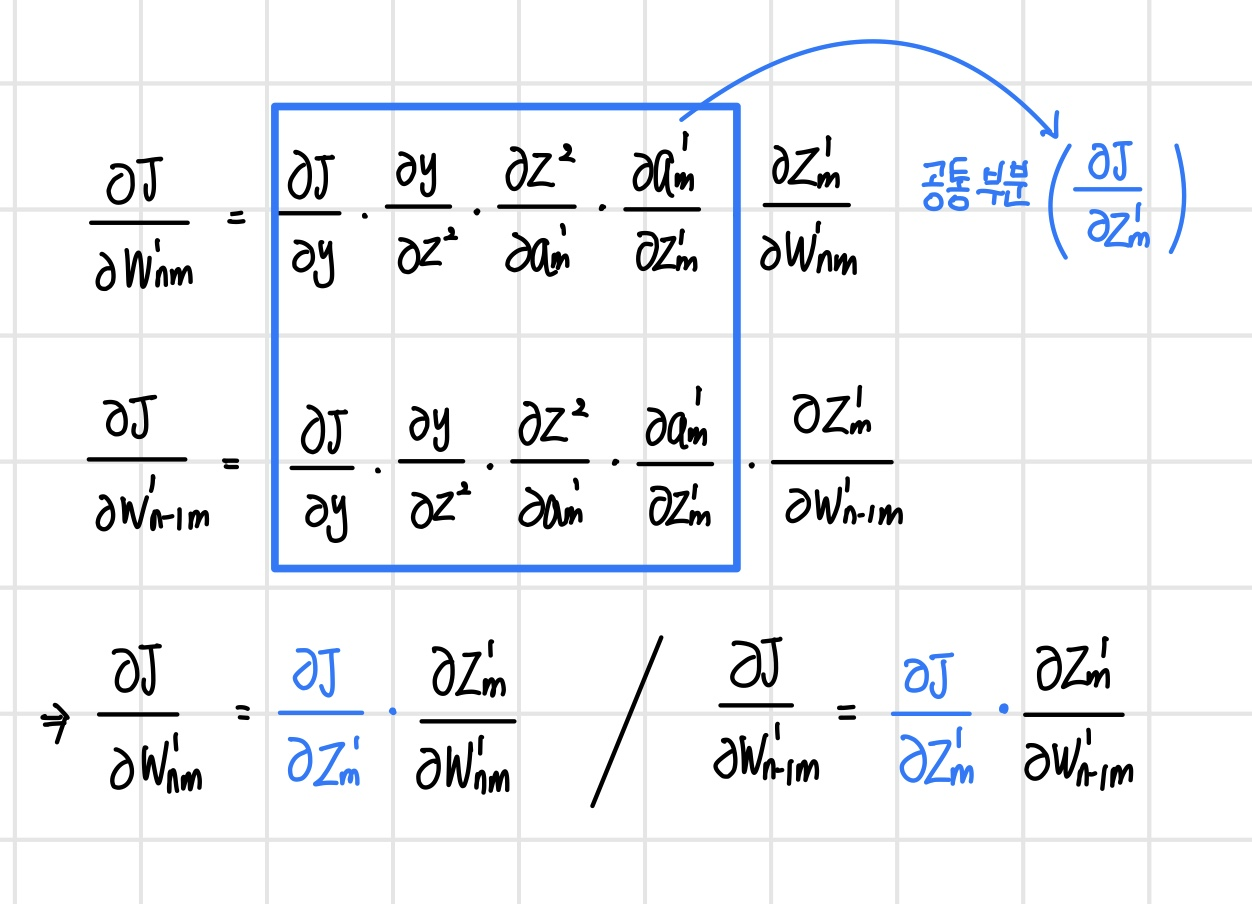
공통부분의 계산을 중복하지 않으려면 손실 함수에서 시작해서 입력 계층 방향으로 계산된 미분값을 역방향으로 전파해 주면 된다. 각 뉴런의 공통부분에 해당하는 미분값을 `오차`라고 하며 오차를 역방향으로 전파하면서 미분을 계산하는 미분 계산 방식을 오차의 역전파 알고리즘이라고 한다.
역전파 알고리즘의 실행 순서
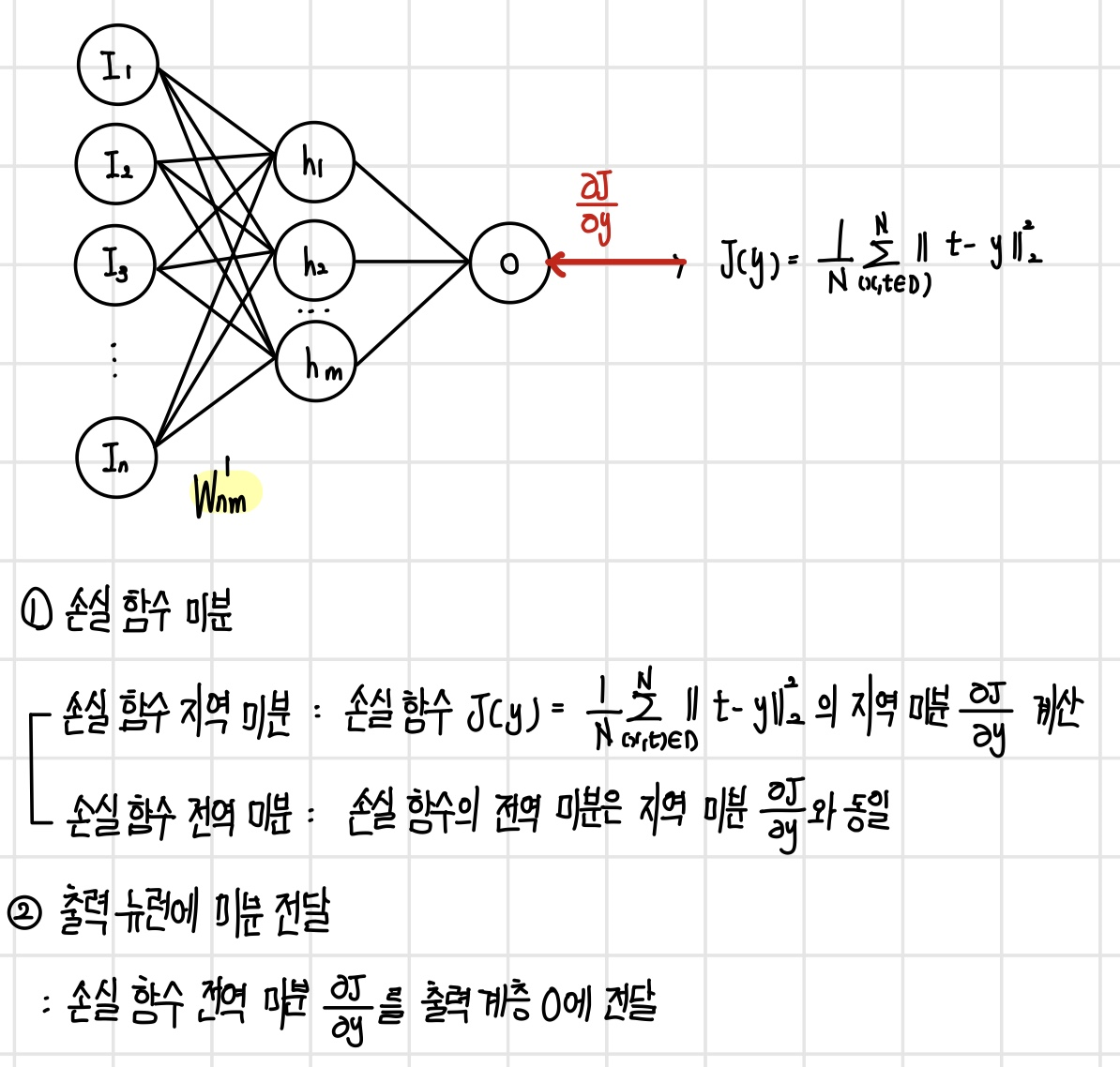
손실 함수 미분
역전파 알고리즘은 손실 함수에서 시작하므로, 먼저 손실 함수에 대한 입력의 미분을 계산하여 출력 계층에 전달한다.
출력 뉴런 미분
출력 뉴런 O는 손실 함수의 전역 미분값을 전달바도 가중치의 미분을 계산해서 가중치를 업데이트한다. 이후 입력의 미분을 계산해서 은닉 계층에 전달한다. O의 활성 함수와 가중 합산은 별도로 미분을 수행한다.

은닉 뉴런 미분
은닉 뉴런은 출력 뉴런에게 전역 미분 값을 전달받고 가중치의 미분을 계산해서 가중치를 업데이트한다. 또한 다음 은닉 계층이 없기 때문에 입력의 미분은 계산하지 않는다. 은닉 뉴런의 활성 함수와 가중 합산은 별도로 미분을 수행한다. 은닉 계층의 가중치 업데이트가 완료되면 역전파 알고리즘도 종료한다.
뉴런 관점에서 보는 역전파 알고리즘
역전파 알고리즘을 하나의 뉴런 관점에서 보면 미분 계산 규칙을 좀 더 쉽게 이해할 수 있다. 다음과 같이 입력 x, y가 있고 활성 함수 z = f(x,y)를 실행하는 뉴런이 있다. 뉴런 출력 z는 손실 함수 J(z)의 입력이다. 이러한 뉴런의 입장에서 미분을 계산하는 방식은 지역 미분을 구하고 전달받은 전역 미분에 곱하는 것이 전부이다.

계층 단위의 미분
이러한 미분 과정은 실제 구현 시 계층 단위로 계산되는데, 뉴런에서 벡터로 표현했던 가중치가 계층에서는 행렬로 표현된다. 뉴런에서 가중치의 미분을 나타내는 그레이디언트는 벡터로 표현되지만, 계층에서 가중치와 미분을 나타내는 `야코비안(jacobian)`은 행렬로 표현된다. X = (X1, X2,..., Xn)와 같이 입력이 n차원 벡터이고 f(x) = (f1(x), f2(x),..., fm(x))와 같이 함숫값이 m차원 벡터인 경우, 입력의 차원별로 함숫값의 각 차원을 편미분 해서 정의한 행렬을 야코비안이라고 한다.

신경망 학습은 역전파 알고리즘을 이용해서 미분을 계산하고 경사 하강법과 같은 최적화 알고리즘을 통해 파라미터를 업데이트하면서 최적해를 찾는 최적화 과정이라고 할 수 있다.
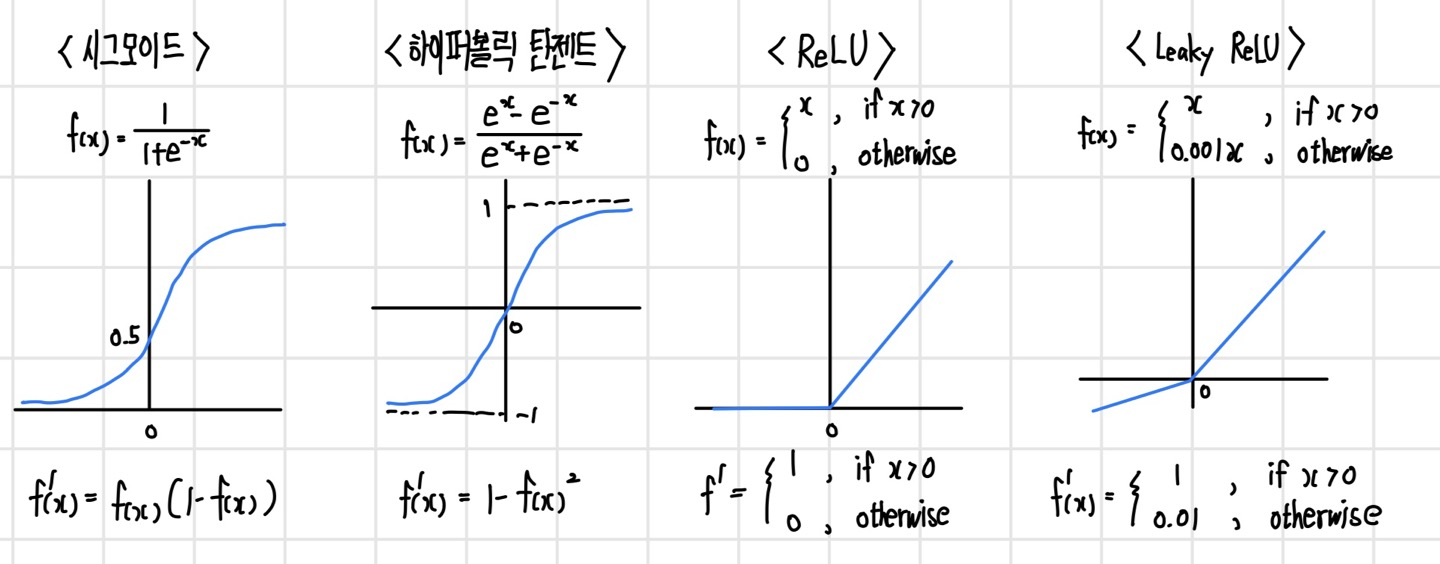
주요 활성 함수의 미분
활성 함수의 미분은 대부분 간단한 형태로 정의된다. 시그모이드 계열의 도함수는 활성 함수 f(x)의 식으로 정의되기 때문에 계산이 간단하며, ReLU 계열은 구간 선형 함수이므로 미분값이 상수이기 때문에 미분을 별도로 계산할 필요가 없다.
데이터셋 구성과 훈련 데이터 단위
데이터셋 구성
관측 데이터의 구성
실생활에서 모집단을 구하기란 대부분 불가능하며, 현실적으로 모집단을 대표할 수 있는 표본 집단을 구성할 수밖에 없다. 관측 데이터를 구성할 때 중요한 것은 범주형 데이터의 경우 클래스별로 비율을 맞추는 것이다. 만일 특정 클래스의 데이터를 확보하기 어려워 한쪽 클래스에 데이터가 치우친다면 데이터를 강제로 늘려주거나 데이터의 분포를 고려하여 손실 함수에 가중치가 조절되도록 알고리즘적으로 해결해야 한다.
데이터셋의 분리
관측 데이터가 준비되면 데이터를 `훈련 데이터셋(train set)`, `검증 데이터셋(valid set)`, `테스트 데이터셋(test set)`으로 분리한다.
- 훈련 데이터셋은 모델을 훈련할 때 사용
- 검증 데이터셋은 훈련된 모델의 성능을 평가하여 하이퍼 파라미터를 튜닝하는 데 사용
- 테스트 데이터셋은 훈련이 완료된 모델의 최종 성능을 평가할 때 사용
이 세 종류의 데이터셋은 서로 중복되지 않도록 배타적으로 분리해야 한다. 여기서 중요한 점은, 분리된 데이터셋의 분포가 원래의 데이터 분포를 따르도록 해야 한다는 것이다. 즉, 검증 데이터셋과 테스트 데이터셋의 분포는 훈련 데이터셋의 분포와 동일해야 한다. 따라서 검증 데이터셋과 테스트 데이터셋에 대한 성능 평가를 위한 데이터가 골고루 들어가도록 최소의 데이터셋을 구성할 수 있다면, 나머지 데이터는 훈련 데이터로 할당한다. 보통 훈련 데이터셋과 테스트 데이터셋의 비율은 전체 관측 데이터셋의 8:2, 7.5:3.5, 7:3 정도의 비율로 분할하며, 검증 데이터셋은 훈련 데이터셋에서 10%~20%를 분할한다.
훈련 데이터 단위
훈련 데이터의 단위
신경망을 학습할 때 훈련 데이터를 한꺼번에 입력하는 것을 `배치(batch) 방식`이라고 한다. 훈련 데이터셋의 크기가 작은 경우 배치 방식으로 학습이 가능하지만, 신경망은 많은 학습 데이터가 필요하여 그만큼 훈련 데이터셋이 크기 때문에 배치 방식으로 학습하면 메모리를 쉽게 초과한다. 이와 같은 배치 방식의 한계를 극복하고자 데이터를 작은 단위로 묶어서 훈련하는 방식을 `미니배치(minibatch) 방식`이라고 한다. 일반적으로 신경망은 미니배치 방식을 통해 학습한다. 데이터 각각의 샘플의 용량이 매우 클 때는 샘플 단위로 훈련하는 `확률적(stochastic) 방식`을 통해 훈련하기도 한다. 미니배치의 크기를 1로 하면 확률적 방식이 되고, 미니배치의 크기를 훈련 데이터셋 크기로 하면 배치 방식이 되므로 미니배치 방식이 가장 융퉁성 있는 방식이다.
훈련 데이터 단위에 따른 경사 하강법의 분류
훈련 데이터의 단위에 따라 경사 하강법도 `배치 경사 하강법(batch gradient descent)`, `미니배치 경사 하강법(minibatch gradient descent)`, `확률적 경사 하강법(stochastic gradient descent)`으로 나뉜다. 배치 경사 하강법은 그레이디언트를 정확하게 계산하므로 부드러운 경로를 만들지만, 확률적 방식은 하나의 샘플로 그레이디언트를 근사하기 때문에 상당히 많이 진동한다. 미니배치 방식도 작은 묶음의 샘플로 그레이디언트를 근사하므로 두 방식의 중간 정도 수준에서 진동한다. 이 세 가지 방식을 엄밀히 구분하지 않는다면 경사 하강법은 일반적으로 배치 경사 하강법을 의미하며 확률적 경사 하강법은 미니배치 경사 하강법을 포함한 의미로 사용한다.
미니배치 훈련 방식
미니배치 훈련 방식의 성능이 우수한 이유
일반적으로 신경망 훈련을 할 때는 미니배치 방식으로 훈련한다. 고해상도 이미지와 같이 샘플 용량이 클 경우는 미니배치 크기를 1로 하여 훈련하기 때문에 확률적 방식으로 훈련하는 셈이다. 미니배치 방식을 사용하면 배치 방식보다 학습이 더 빨라지고 모델의 성능이 좋아진다. 미니배치 방식은 데이터를 작은 단위로 묶어서 훈련하기 때문에 미니배치를 생성할 때마다 매번 다른 데이터로 묶여 조금씩 다른 통계량을 갖는 확률적 성질이 생기게 된다. 이러한 확률적 성질이 생기게 되면 일반화 오류가 줄어들고 과적합이 방지되는 정규화 효과를 볼 수 있다. 결론적으로 미니배치 방식으로 훈련하면 그레이디언트는 근삿값을 갖지만 학습 속도가 빨라지고 정규화 효과 덕분에 좋은 최적해를 찾을 수 있다.
미니배치의 크기는 어느 정도로 정해야 할까?
일반적으로 미니배치의 크기는 2의 거듭제곱(2,4,8,16,32,64,128,256,512)으로 정해야 GPU 메모리를 효율적으로 사용할 수 있다. 미니배치를 키울 경우 증가하는 계산 시간에 비해 얻을 수 있는 통계적 이득이 크지 않기 때문에 미니배치 크기를 무작정 키운다고 성능이 좋아지진 않는다. 미니배치 크기는 신경망을 훈련하면서 검증 데이터셋을 이용해서 적절한 크기를 찾아야 한다.
손실 함수 정의
손실 함수를 정의하는 기준
신경망 모델이 정확하게 예측하려면 모델은 관측 데이터를 잘 설명하는 함수를 표현해야 한다. 이를 위해서 손실 함수는 최적해가 관측 데이터를 잘 설명할 수 있는 함수의 파라미터값이 되도록 정의되어야 한다. 이를 위해선 두 가지 기준으로 손실 함수를 정의하며, 이는 결국 동일한 최적해를 갖는 함수가 되어 같은 대상을 다르게 해석하는 것이다.
- 모델이 `오차 최소화(error minimization)`되도록 정의
- 모델의 오차는 모델의 예측과 관측 데이터의 타깃의 차이
- 손실 함수의 목표는 오차를 최소화하는 것이며, 손실 함수를 정의할 때 어떤 방식으로 오차의 크기를 측정할지 결정
- 모델이 추정하는 관측 데이터의 확률이 최대화되도록 `최대우도추정(MLE·Maximum Likelihood Estimation)` 방식 정의
- `우도(likelihood)` : 모델이 추정하는 관측 데이터의 확률
- 손실 함수의 목표는 관측 데이터의 확률이 최대화되는 확률분포 함수를 모델이 표현하도록 만드는 것
- 확률 모델인 경우에만 적용 가능하며, 대부분의 신경망 모델은 확률 모델을 가정하므로 손실 함수 유도 가능
오차 최소화 관점에서 손실 함수 정의
신경망 모델은 파라미터 세타(theta)로 이루어져 있고 학습 데이터 D가 있다고 할 때, 모델의 예측을 y라고 하고 타깃을 t라고 하면 오차는 다음과 같다.
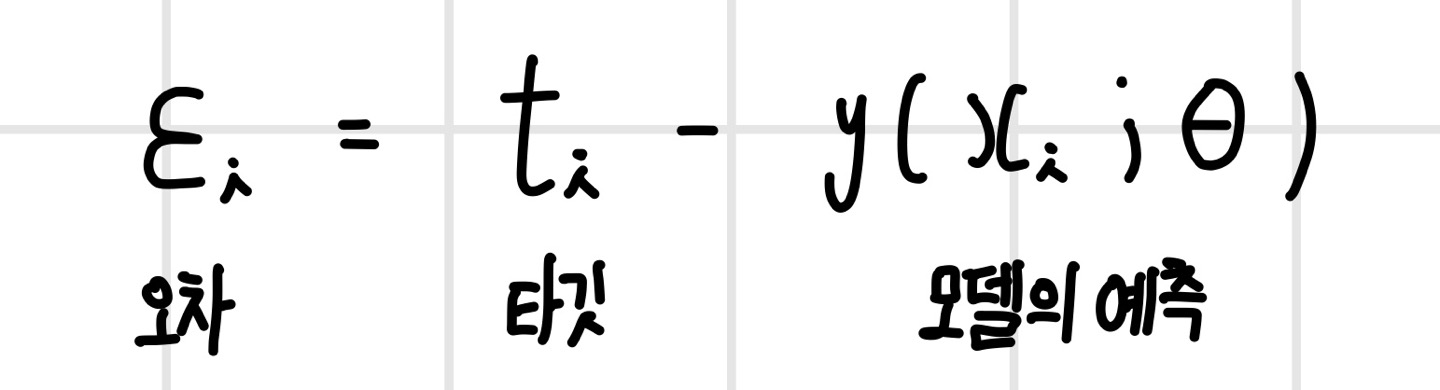
오차 최소화 관점에서 손실 함수는 오차의 크기를 나타내는 함수로 정의하면 된다. 오차의 크기를 나타내는 대표적인 함수는 벡터의 크기를 나타내는 `노름(norm)`이다. 주로 L2 노름과 L1 노름을 사용하며 이때 손실 함수를 `평균제곱오차(MSE·Mean Squared Error)`와 `평균절대오차(MAE·Mean Absolute Error)라고 한다.
평균제곱오차는 N개의 데이터에 대해 오차의 L2 노름의 제곱의 평균으로 정의되면 l2 손실로 표기한다. 평균제곱오차는 모델이 타깃 t의 평균을 예측하도록 만든다. 오차가 커질수록 손실이 제곱승으로 상승하기 때문에 이상치에 민감하게 반응한다는 단점이 있다.

평균절대오차는 N개의 데이터에 대해 오차의 L1 노름의 평균으로 정의하며 l1 손실이라고 표기한다. 평균절대오차는 모델이 타깃의 중앙값을 예측하도록 만든다. 오차가 커질수록 손실이 선형적으로 증가해 이상치에 덜 민감하다. 그러나 이는 미분 가능한 함수가 아니기 때문에 구간별로 미분을 처리해야 하는 단점이 있다.
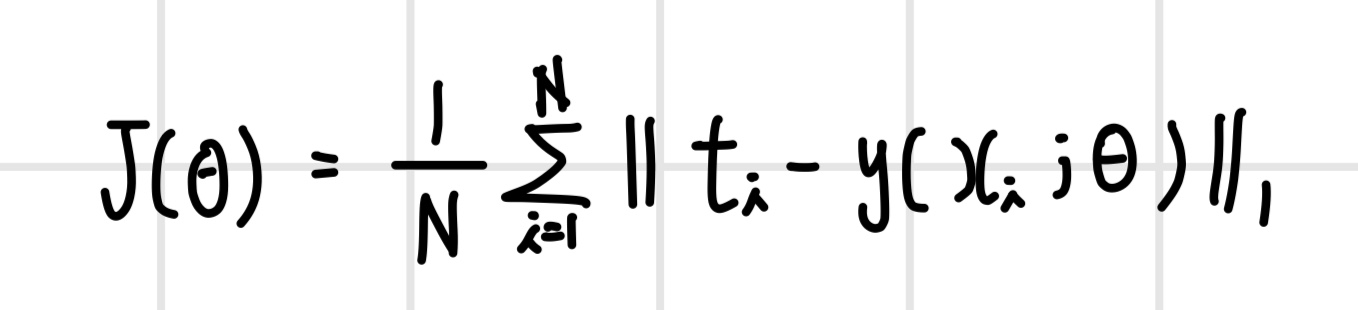
오차 최소화 관점에서 평균제곱오차를 통 신경망 학습을 위한 최적화 문제를 정의한다 하면 다음과 같이 정의할 수 있다.

노름과 거리 함수
앞서 본 노름이란, 벡터의 크기를 나타내며 다음과 같은 p-노름의 식으로 정의된다. p의 값에 따라 노름의 종류가 달라진다.
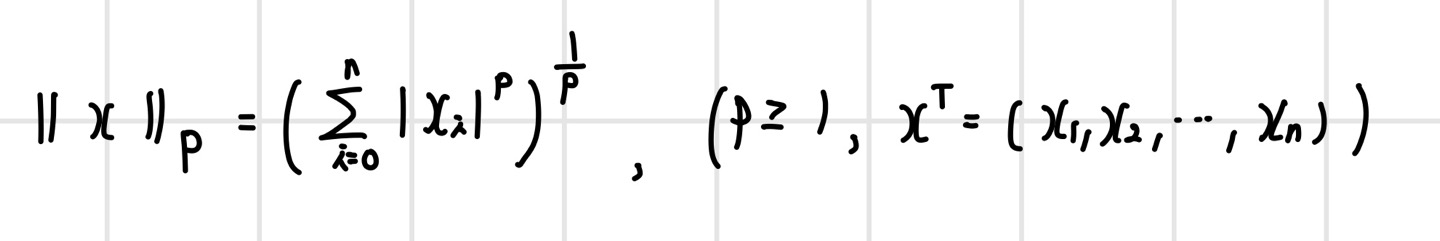
p=1일 때는 L1 노름이라고 하며, 벡터 x의 각 요소에 절댓값을 취해서 합산한 값이다.
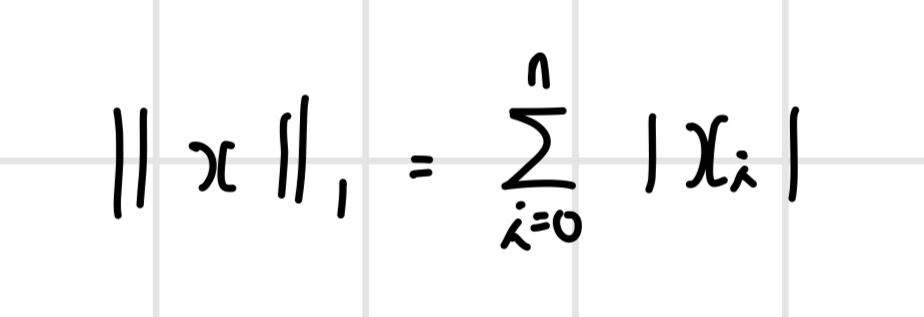
p=2일 때는 L2 노름이라고 하며, 벡터 x의 각 요소에 절댓값을 취해서 제곱한 후 합산해서 제곱근을 취한 값이다.
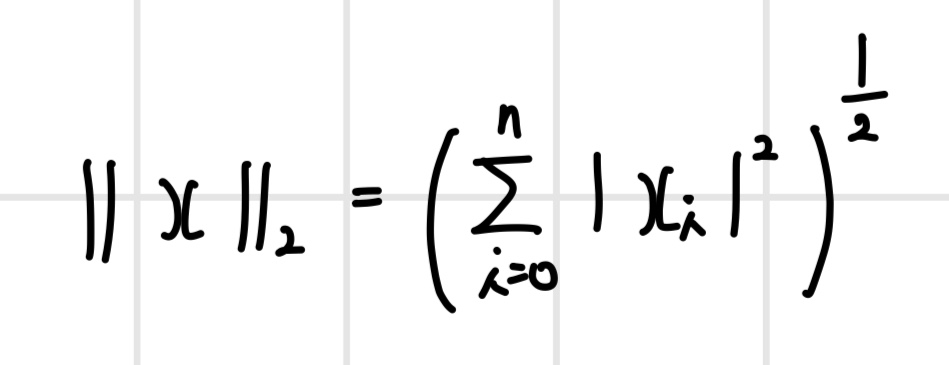
노름은 `거리 함수(distance function)`으로도 사용할 수 있다. 두 점 사이의 거리를 계산할 때 두 점의 차 벡터를 구한 후 노름을 계산하면 거리가 되기 때문이다.
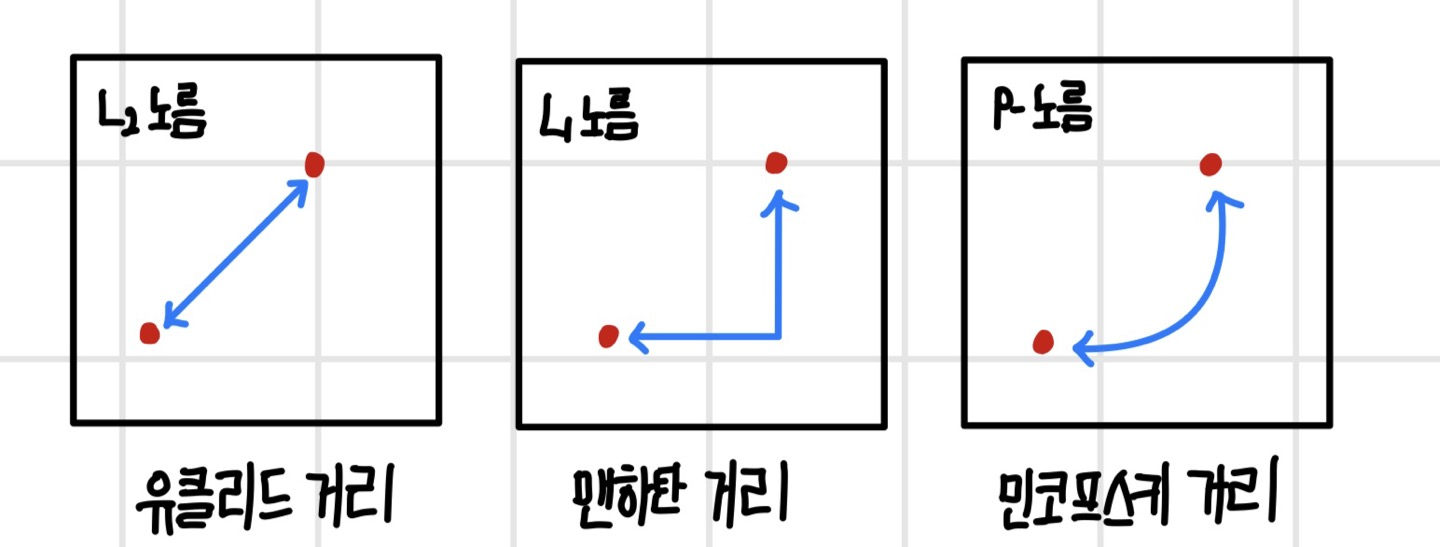
- `유클리드 거리(Euclidean distance)` : 두 점 사이의 짧은 거리를 나타내며 두 벡터의 차에 L2 노름 적용
- `맨해튼 거리(Manhattan distance)` : 각 축을 따라 직각으로 이동하는 거리로 두 벡터의 차에 L1 노름 적용
- `민코프스키 거리(Minkowski distance)` : 임의의 p 값에 대해 두 벡터의 차에 p-노름을 적용
최대우도추정 관점에서 손실 함수 정의
관측 데이터의 우도와 손실 함수
신경망 모델은 파라미터 세타(theta)로 이루어진 확률 모델이고, 학습 데이터 D의 각 샘플은 같은 분포에서 독립적으로 샘플링되어 i.i.d 성질을 만족하자고 할 때 신경망 모델로 추정한 관측 데이터의 확률이 우도이다. 각 샘플은 서로 독립이기 때문에 관측 데이터의 우도는 N개의 샘플의 우도의 곱으로 표현할 수 있다.
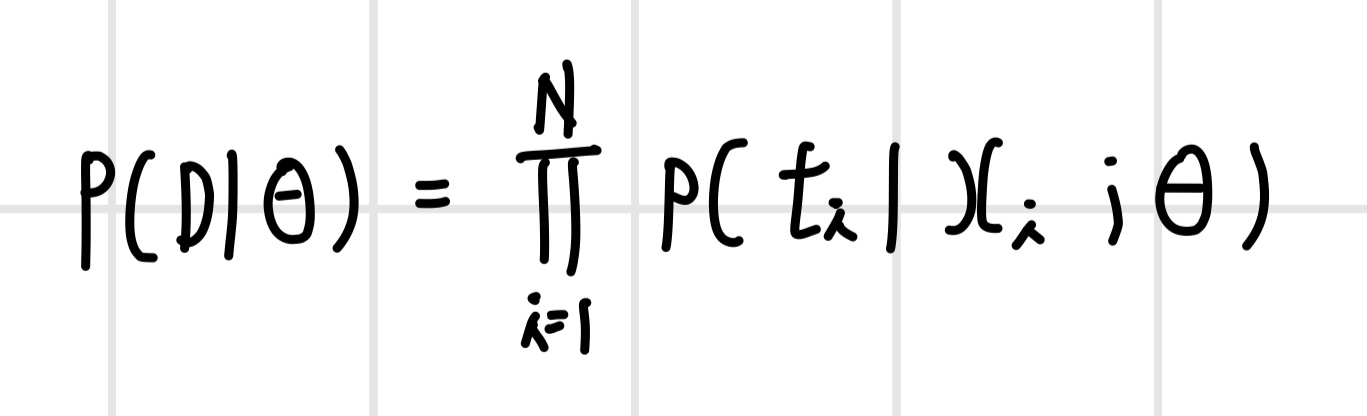
최대우도추정 관점에서 목적 함수인 우도를 최대화하는 확률 모델의 파라미터 세타(theta)를 찾는 최적화 문제는 다음과 같이 정의할 수 있다.
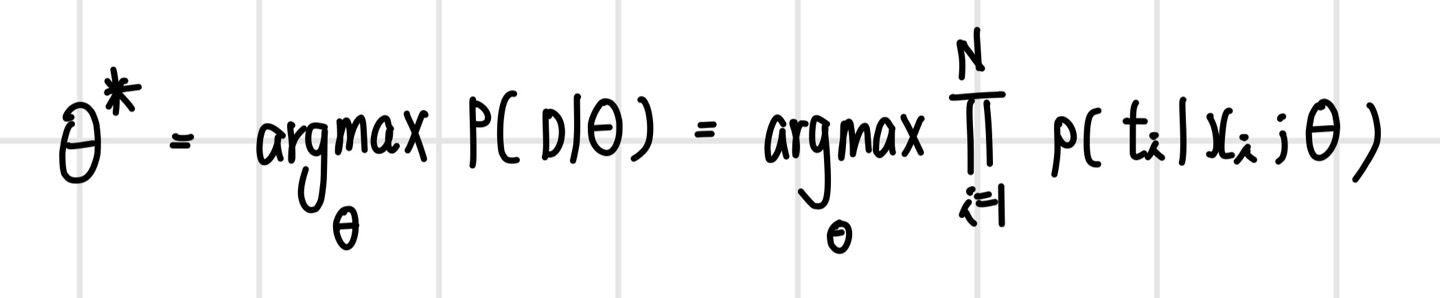
최대우도추정 관점의 최적화 문제 개선
앞서 정의한 최적화 문제를 조금만 변형하면 수치적으로 다루기 쉬워지며 안정적으로 최적화할 수 있다. 또한 표준 형태의 최소화 문제로 통일할 수도 있다. 이를 위해선 다음과 같은 변환 과정을 거쳐 문제를 재정의한다.
- 목적 함수를 개선된 형태로 만들기 위해 우도 대신 `로그 우도(log likelihood)` 사용
- 최대화 문제를 최소화 문제로 변환하기 위해 목적함수에 `음의 로그 우도(negative log likelihood)` 사용
먼저, 목적 함수를 로그 우도로 변환하는 과정이다. 로그 우도란 우도에 로그를 취한 형태를 말하며 로그 우도를 사용하면 다음과 같은 식으로 변환된다.
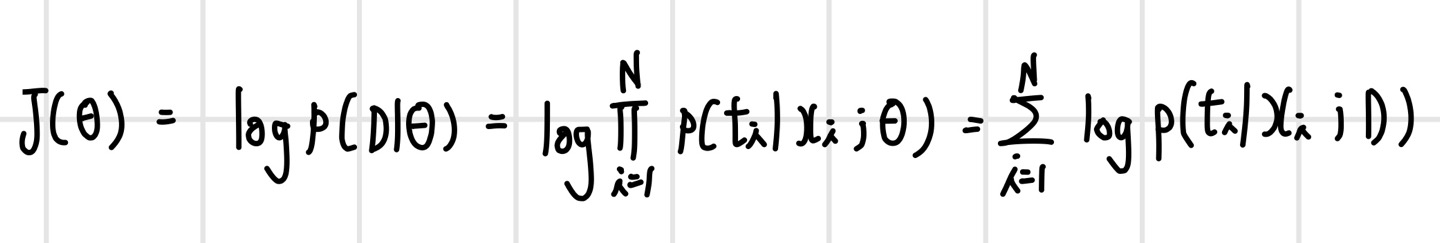
우도 대신 로그 우도를 사용하는 이유는 다음과 같다.
- 가우시안 분포 또는 베르누이 분포와 같은 지수 함수 형태로 표현되는 확률분포는 로그를 취하면 지수 항이 상쇄되어 다항식으로 변환되기 때문에 함수 형태가 다루기 쉬워짐
- N개 샘플에 대한 우도의 곱을 로그 우도의 합산으로 바꾸면 언더플로를 방지
- 확률은 1보다 작기 때문에 확률을 N번 곱하면 N이 커질수록 언더플로가 쉽게 발생
- 로그 우도를 사용하면 곱이 합산 형태로 바뀌어 언더플로를 방지
- 최적화 문제는 목적 함수에 로그와 같은 증가함수를 적용하더라도 동일한 해를 얻을 수 있으므로 최적해 변화 x
다음은 최대화 문제를 최소화 문제로 변환하는 과정이다. 이 과정에선 로그 우도에 음수를 취한 음의 로그 우도, 즉 `NLL(Negative Log Likelihood)`로 손실 함수가 정의된다. NLL의 손실 함수와 이를 통한 표준 형태의 최소화 문제로 재정의된 식은 다음과 같다.
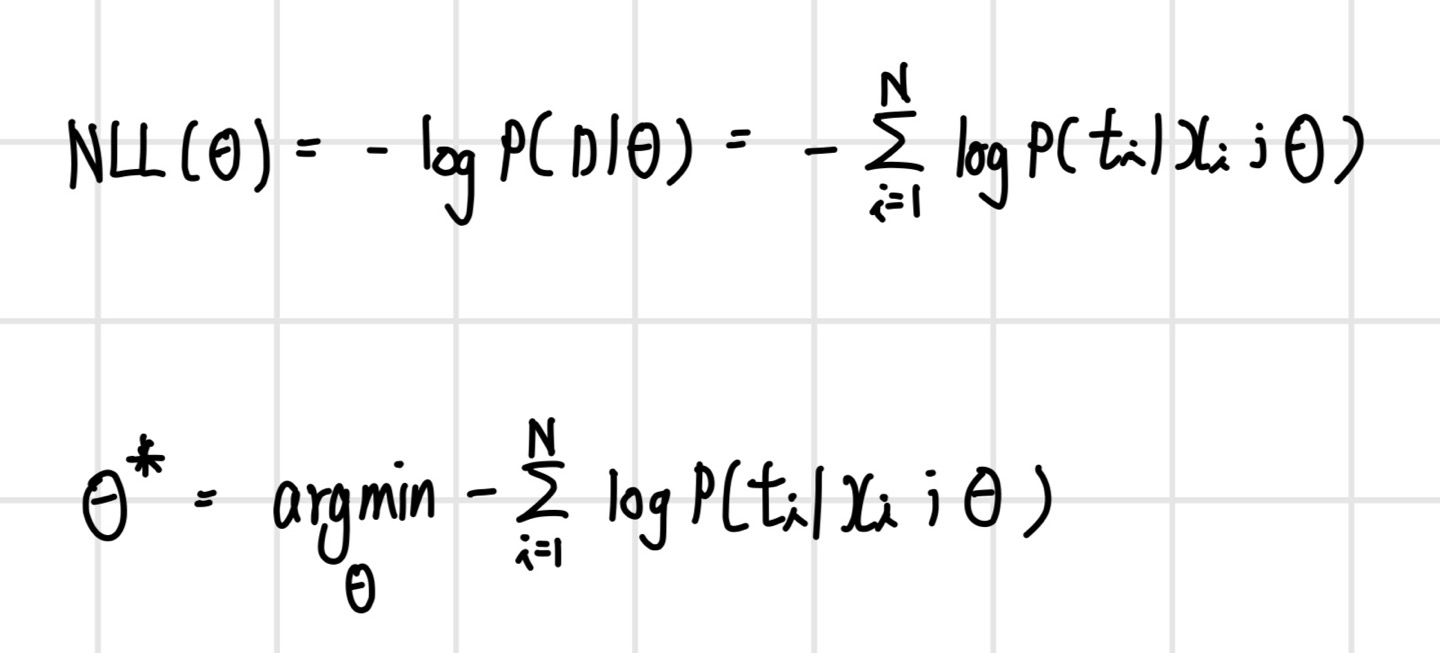
정보량, 엔트로피, 크로스 엔트로피
정보량(self-information)
`정보량(self-information)`은 확률을 표현하는 데 필요한 비트 수로 사건이 얼마나 자주 발생하는지를 나타낸다. 또한 정보량은 확률에 반비례하면서 독립 사건들의 정보량은 더해져야 하므로, 확률의 역수에 로그를 취한 값으로 정의된다. 다음 그래프를 보면 확률이 0이면 정보량은 무한대가 되고 확률이 1이면 정보량은 0이다.
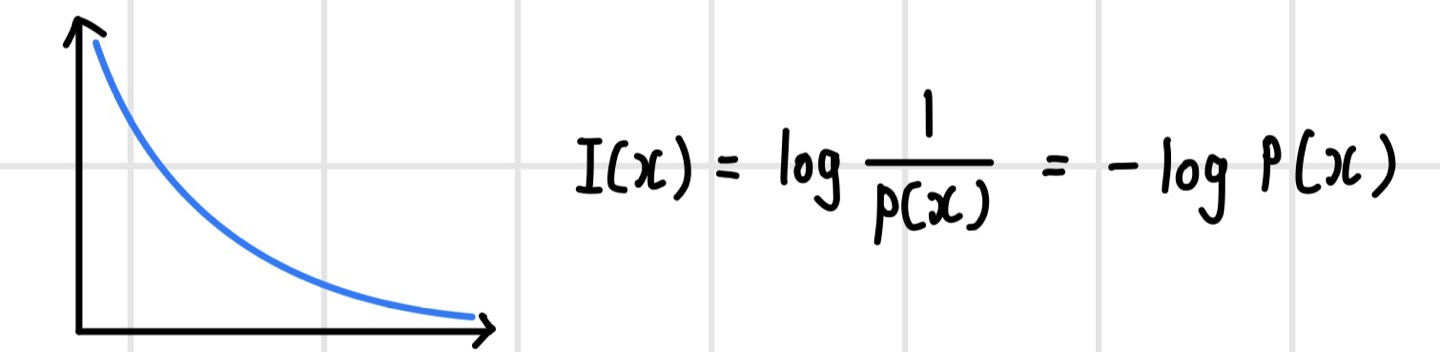
엔트로피(entropy)
`엔트로피(entropy)`는 확률 변수가 얼마나 `불확실(uncertain)`한지 혹은 `무작위(random)`한지를 나타낸다. 분산이 큰 확률분포의 경우 넓은 범위에서 사건이 발생하므로 어떤 사건이 발생할지 불확실해 엔트로피 또한 높다. 반면 분산이 작은 확률분포의 경우 좁은 범위에서 사건이 발생하므로 어떤 사건이 발생할지 확실해 엔트로피는 낮다. 이러한 엔트로피는 확률 변수의 정보량의 기댓값으로 정의된다. 엔트로피는 p(x) = 0 혹은 1일 때 0이 되고, p(x) = 0.5일 때 최댓값 1이 된다.
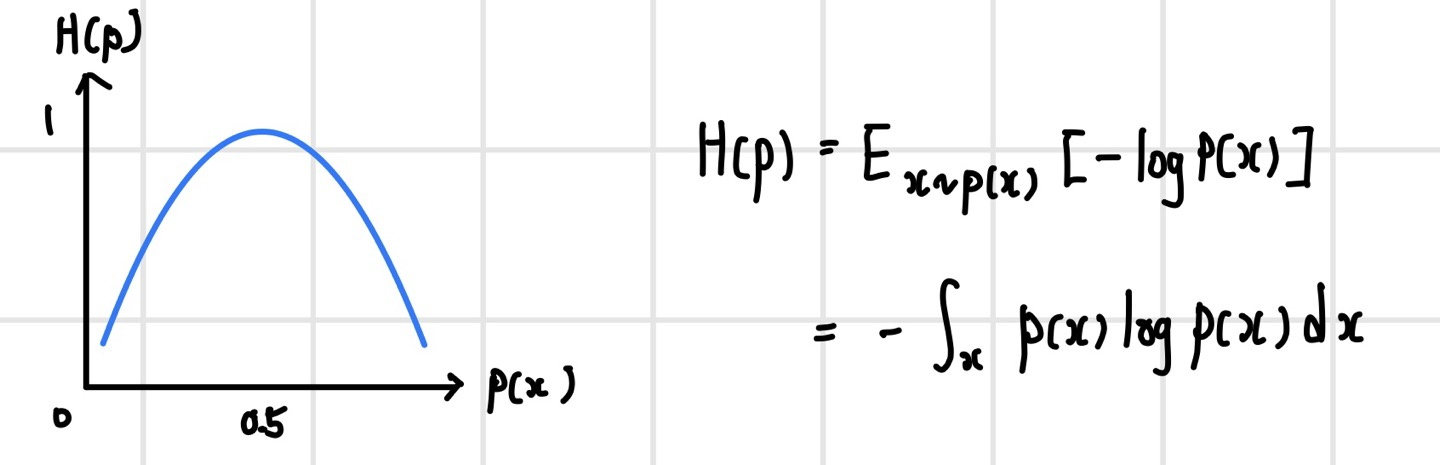
크로스 엔트로피(Cross Entropy)
`크로스 엔트로피(Cross Entropy)`는 두 확률분포의 차이 또는 유사하지 않은 정도(dissimilarity)를 나타낸다. 확률 분포 q로 확률 분포 p를 추정한다고 할 때 크로스 엔트로피는 q의 정보량을 p에 대한 기댓값을 취하는 것으로 정의한다. q가 p를 정확히 추정해서 두 분포가 같아지면 크로스 엔트로피는 최소화되고, 잘못 추정할 경우 크로스 엔트로피는 높아진다. 이를 통해 크로스 엔트로피는 q와 p의 유사하지 않은 정도를 나타내는 지표로 볼 수 있다.
하나의 데이터 샘플 (x,t)에 대해서 이진 크로스 엔트로피 손실 함수가 어떻게 변화하는지 확인해 보면 다음과 같다.
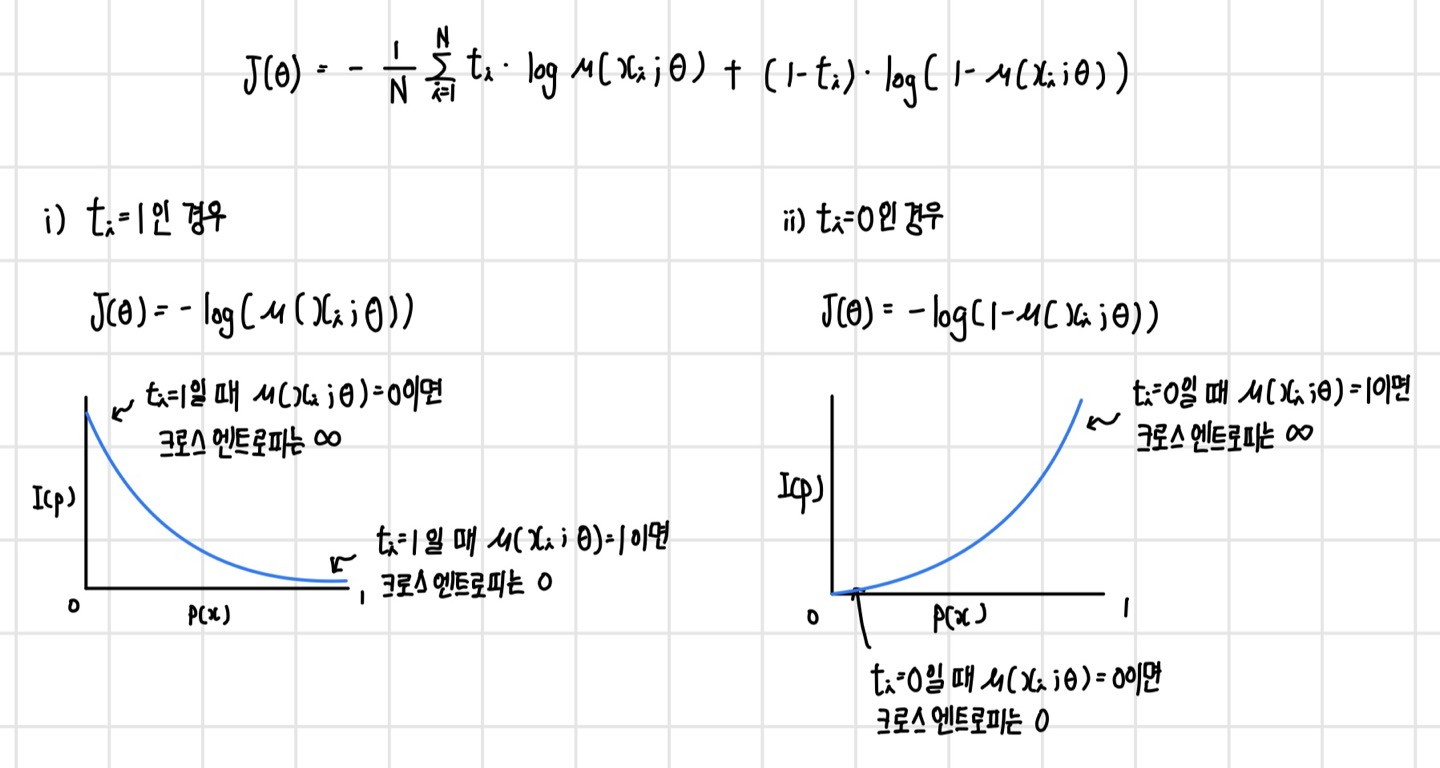
즉, 신경망의 예측 분포와 타깃 분포가 같으면 크로스 엔트로피는 최소화되며, 신경망의 예측 분포와 타깃 분포가 0과 1로 서로 반대가 되면 크로스 엔트로피는 ∞가 된다.
본 포스팅은 'Do it! 딥러닝 교과서' 교재를 공부하고 작성한 글입니다.