대회 정보

https://dacon.io/competitions/official/236082/overview/description
DACON에서 진행한 '도배 하자 유형 분류 AI 경진대회'에 참여했다. 해당 대회는 19가지의 도배 하자 이미지를 가지고 유형 분류를 하는 AI 모델을 개발하는 대회이다. Train dataset의 경우 19개의 class folder에 총 3,457개의 데이터가 포함되어 있으며 모델 예측에 활용하는 Test dataset은 레이블이 주어져있지 않은 791개의 이미지 데이터이다. 평가 지표로는 weighted f1 score을 활용한다.

해당 데이터는 데이터 불균형이 매우 심한 데이터이다. 가장 데이터의 개수가 많은 클래스는 훼손으로 1,405개의 데이터가 있었고, 가장 적은 데이터는 반점으로 3개의 데이터만 포함되어 있다. 또한 정상 데이터가 포함되어 있지 않아 이런 부분들을 고려하여 모델을 구성해야 한다. 본 프로젝트에서 가장 중요하게 생각한 부분은 Data Augmentation, Object Detection이었다.
프로젝트 과정
1. CNN
가장 먼저 대략적인 확인을 위해 아무것도 하지 않은 상태로 CNN 모델 두가지 Resnet18 과 EfficientNetB0 모델로 데이터를 학습시켜 제출을 해보았다. 데이터의 개수가 적은 편이라고 판단하여 layer는 너무 깊지 않은 모델을 사용했고, pretrained 또한 FALSE로 설정하였다. 제출 결과 평가 지표로 활용한 weighted f1 score를 기준으로 각각 0.1124731341, 0.1254658385의 점수를 기록했다.
2. Diffusion Model
Data Augmentation을 위해 replicate.com 사이트를 통해 유료로 Stable Diffusion Model을 사용했다. 데이터를 생성하는 코드는 매우 간단하다.
os.environ["REPLICATE_API_TOKEN"] = getpass("Enter your Replicate API token: ")
model = replicate.models.get("stability-ai/stable-diffusion-img2img")
version = model.versions.get("API Key")먼저, 결제를 통해 얻은 API KEY를 통해 Diffusion Model을 불러드린다.
folder_idx = '17'
data_dir = 'C:/Users/user/Desktop/train/' + folder_idx + '/'
output_dir = 'C:/Users/user/Desktop/train/' + folder_idx + '/'
images = os.listdir(data_dir)
for fname in images:
inputs = {
'prompt': "fine cracks, different background",
'image': open(os.path.join(data_dir, fname), "rb"),
'prompt_strength': 0.13,
'num_outputs': 3,
'num_inference_steps': 30,
'guidance_scale': 11,
'scheduler': "K_EULER_ANCESTRAL"
}
output = version.predict(**inputs)
for i, url in enumerate(output):
response = requests.get(url)
with open(output_dir + f"{os.path.splitext(fname)[0]}_gen_{i+1}.png", "wb") as f:
f.write(response.content)이후 prompt에 원하는 생성 방식을 텍스트로 입력한 후 파라미터를 조정하여 실행하면 원본 데이터에서 조금의 변화만 준 데이터를 생성해준다. 데이터의 개수가 적은 클래스에 대하여 모두 약 100개 정도로 데이터를 증강을 해주었고, pytorch를 통해 추가적으로 증강을 진행하여 데이터의 개수를 약 600개로 구성하였다. 여기서 아쉬웠던 부분은, 19가지의 클래스마다 하자 유형이 다른데, 각 유형을 모두 파악해서 유형에 맞게 prompt를 설정하여 생성하지 못한 점이다.




그러나 이렇게 데이터를 증강한 이후 CNN 모델을 통해 학습을 진행하고, 제출한 결과는 더욱 처참했다. 거의 0점대에 가까운 0.0756134696, 0.002445397 점수가 나왔다. 이 순간 근본적으로 무언가 프로젝트의 방향을 잘못 잡았다는 생각이 들었다. 그래서 데이콘에 있는 토크 파트에서 다른 참가자 분들이 올린 글도 확인해보고, 직접 이미지도 확인해 보았을 때 몇 가지 문제점이 보였다.
- 클래스 간 차이가 크지 않다. 따라서 CNN 모델이 분류하는 데 애매한 데이터가 많다.
- CNN이 특징으로 판단할 부분이 두드러지지 않는다. 즉, 직접 이를 지정해 줄 필요가 있다.
- 하자 위치를 표시하기 위해 데이터에 화살표 같은 부분이 있는데 이를 가지고 분류하는 경우도 있다.



3. Object Detection
위에서 확인한 문제점을 통해 Object Detection 문제로 해당 대회를 바라봐야한다는 것을 깨달았다. 하자 유형별 특징을 DACON 측에서 올려줬는데, 이를 확인해 볼 필요가 있는 것이다. 따라서 하자 유형별로 특징을 파악하고, 직접 박스를 지정해 데이터를 재구성하였다. 이 과정에서는 http://roboflow.com 사이트를 이용하였다. 해당 사이트를 통해 다시 데이터를 train/valid dataset으로 나누고 클래스별로 직접 박스를 지정하여 클래스별 특징을 지정해주었다.

이렇게 다시금 데이터셋을 만든 후 YOLOv8 모델을 통해 object detection 및 classification을 진행했다. 해당 모델에 detect와 classify 두 가지 모델이 있어 모두 학습을 진행했다. imgsz는 800으로 지정하였으며 200 에포크로 학습을 진행했다. 그 결과 weighted f1 score는 0.5318018066, 0.5213931102까지 올랐다.
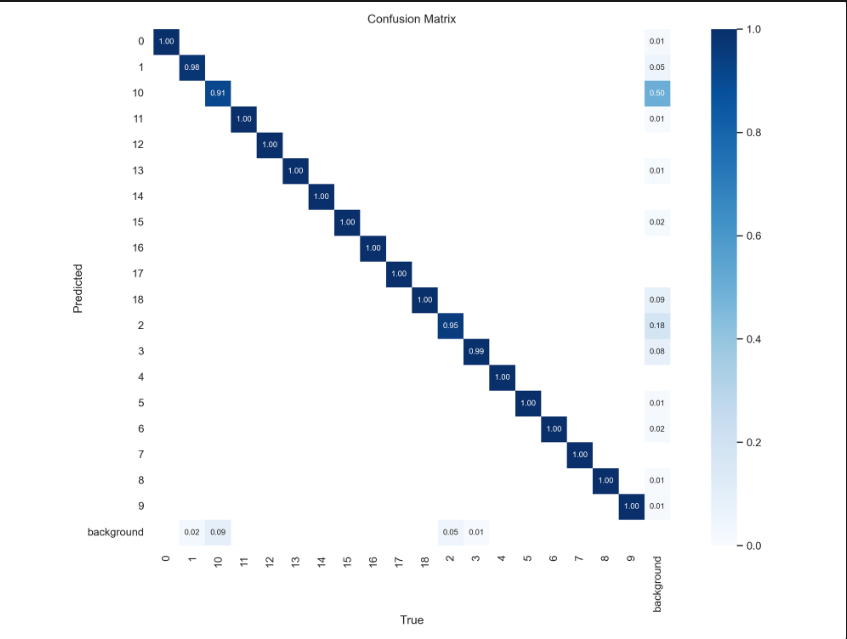
confusion matrix를 확인해보면 어느정도 학습은 잘 된 것 같은데, 실제 792개의 테스트 데이터에 대해서 예측을 수행했을 때 약 200개의 데이터는 탐지를 하지 못했다. 이는 데이터가 부족했다고 판단했고, 앞서 Stable Diffusion Model을 통해서 증강시켰던 데이터를 활용했다. 하지만 증강 데이터에 대해서도 일일이 박스를 지정해주는 작업이 필요했기 때문에 현실적으로 모든 데이터를 활용하진 못했고, 100개가 되지 않는 클래스에 해당하는 데이터에 대해서만 약 150개의 데이터로 증강시켰다.
그러나 증강 데이터를 활용한 결과는 차이가 거의 없었다. 0.5340605851, 0.5416652623 정도의 점수를 기록했다. 그러나 아래의 Confusion Matrix를 보면 소수 데이터가 늘어나 실제 많은 데이터가 포함되어 있던 훼손 같은 레이블에 대한 탐지는 전보다 못하는 것처럼 보인다. 그러나 점수는 비슷하게 나온 것은 imbalanced data에 대한 분류 모델을 구성할 때 f1 score를 많이 사용하기 때문에 증강 데이터를 활용한 모델은 소수 데이터에 대해 전보다 잘 맞추기 때문이라는 생각이 들었다.
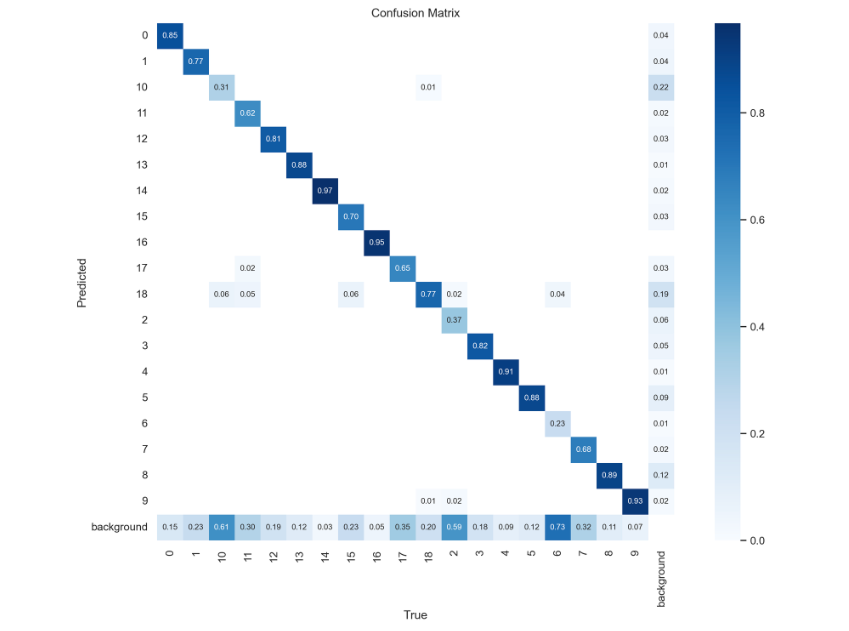
대회는 이렇게 끝이 났다. 전체적인 프로세스는 다음과 같다.
- CNN 모델을 활용한 분류에서 전혀 이미지에 대한 특징을 파악하지 못하고, 분류를 제대로 수행하지 못함
- Stable Diffusion Model을 통한 이미지 증강을 진행한 후 CNN 모델 학습을 진행했지만 성능이 더욱 안좋아짐
- Object Detection 문제로 전환한 후 직접 박스를 지정해 데이터셋을 재구성하고, YOLOv8 모델로 학습하여 성능이 많이 향상
- 앞서 증강한 데이터를 통해 다시 학습을 진행했지만 성능에 크게 변화가 없음
코멘트
순위는 Public은 256/1,028 Private은 207/1,025등이었다. 아무래도 CNN 모델을 통한 분류 과정 이후에는 처음 접해보는 분야였기 때문에 프로젝트 과정에서 허술한 부분이 많다. 또한 지금 생각해보면 아쉬운 부분도 참 많다. 그러나 그동안 공부해보지 못했던 Object Detection과 Diffusion Model 등을 직접 데이터셋에 적용시켜보고, 이런 저런 수정 과정을 통해 성능도 향상시켜보는 과정이 의미가 있었던 프로젝트라고 생각한다.
아쉬웠던 부분은 다음과 같다.
- Diffusion Model을 통한 증강 과정에서 클래스별로 다른 방식으로 증강을 하지 못함
- YOLOv8 모델의 성능 향상을 위한 방법들을 더 공부해보고 적용시켜보지 못함
- YOLOv8 모델이 탐지하지 못한 약 200여 개의 데이터에 대해 직접 확인해보고 모델을 수정해보지 못함
- Stable Diffusion Model, YOLOv8 등 사용해보지 못했던 모델들에 대해 적용하면서 output을 얻어낸 것에서 그치지 않고 추가적으로 모델에 대한 논문을 읽어보는 등 공부를 더해서 어느 정도 이해도를 높인 상태로 대회를 진행하지 못함
- 박스를 지정하는과정에서 일관적이지 못한 부분이 있는 것 같음
대회 정보
https://dacon.io/competitions/official/236082/overview/description
DACON에서 진행한 '도배 하자 유형 분류 AI 경진대회'에 참여했다. 해당 대회는 19가지의 도배 하자 이미지를 가지고 유형 분류를 하는 AI 모델을 개발하는 대회이다. Train dataset의 경우 19개의 class folder에 총 3,457개의 데이터가 포함되어 있으며 모델 예측에 활용하는 Test dataset은 레이블이 주어져있지 않은 791개의 이미지 데이터이다. 평가 지표로는 weighted f1 score을 활용한다.
해당 데이터는 데이터 불균형이 매우 심한 데이터이다. 가장 데이터의 개수가 많은 클래스는 훼손으로 1,405개의 데이터가 있었고, 가장 적은 데이터는 반점으로 3개의 데이터만 포함되어 있다. 또한 정상 데이터가 포함되어 있지 않아 이런 부분들을 고려하여 모델을 구성해야 한다. 본 프로젝트에서 가장 중요하게 생각한 부분은 Data Augmentation, Object Detection이었다.
프로젝트 과정
1. CNN
가장 먼저 대략적인 확인을 위해 아무것도 하지 않은 상태로 CNN 모델 두가지 Resnet18 과 EfficientNetB0 모델로 데이터를 학습시켜 제출을 해보았다. 데이터의 개수가 적은 편이라고 판단하여 layer는 너무 깊지 않은 모델을 사용했고, pretrained 또한 FALSE로 설정하였다. 제출 결과 평가 지표로 활용한 weighted f1 score를 기준으로 각각 0.1124731341, 0.1254658385의 점수를 기록했다.
2. Diffusion Model
Data Augmentation을 위해 replicate.com 사이트를 통해 유료로 Stable Diffusion Model을 사용했다. 데이터를 생성하는 코드는 매우 간단하다.
os.environ["REPLICATE_API_TOKEN"] = getpass("Enter your Replicate API token: ") model = replicate.models.get("stability-ai/stable-diffusion-img2img") version = model.versions.get("API Key")
먼저, 결제를 통해 얻은 API KEY를 통해 Diffusion Model을 불러드린다.
folder_idx = '17' data_dir = 'C:/Users/user/Desktop/train/' + folder_idx + '/' output_dir = 'C:/Users/user/Desktop/train/' + folder_idx + '/' images = os.listdir(data_dir) for fname in images: inputs = { 'prompt': "fine cracks, different background", 'image': open(os.path.join(data_dir, fname), "rb"), 'prompt_strength': 0.13, 'num_outputs': 3, 'num_inference_steps': 30, 'guidance_scale': 11, 'scheduler': "K_EULER_ANCESTRAL" } output = version.predict(**inputs) for i, url in enumerate(output): response = requests.get(url) with open(output_dir + f"{os.path.splitext(fname)[0]}_gen_{i+1}.png", "wb") as f: f.write(response.content)
이후 prompt에 원하는 생성 방식을 텍스트로 입력한 후 파라미터를 조정하여 실행하면 원본 데이터에서 조금의 변화만 준 데이터를 생성해준다. 데이터의 개수가 적은 클래스에 대하여 모두 약 100개 정도로 데이터를 증강을 해주었고, pytorch를 통해 추가적으로 증강을 진행하여 데이터의 개수를 약 600개로 구성하였다. 여기서 아쉬웠던 부분은, 19가지의 클래스마다 하자 유형이 다른데, 각 유형을 모두 파악해서 유형에 맞게 prompt를 설정하여 생성하지 못한 점이다.
그러나 이렇게 데이터를 증강한 이후 CNN 모델을 통해 학습을 진행하고, 제출한 결과는 더욱 처참했다. 거의 0점대에 가까운 0.0756134696, 0.002445397 점수가 나왔다. 이 순간 근본적으로 무언가 프로젝트의 방향을 잘못 잡았다는 생각이 들었다. 그래서 데이콘에 있는 토크 파트에서 다른 참가자 분들이 올린 글도 확인해보고, 직접 이미지도 확인해 보았을 때 몇 가지 문제점이 보였다.
- 클래스 간 차이가 크지 않다. 따라서 CNN 모델이 분류하는 데 애매한 데이터가 많다.
- CNN이 특징으로 판단할 부분이 두드러지지 않는다. 즉, 직접 이를 지정해 줄 필요가 있다.
- 하자 위치를 표시하기 위해 데이터에 화살표 같은 부분이 있는데 이를 가지고 분류하는 경우도 있다.
3. Object Detection
위에서 확인한 문제점을 통해 Object Detection 문제로 해당 대회를 바라봐야한다는 것을 깨달았다. 하자 유형별 특징을 DACON 측에서 올려줬는데, 이를 확인해 볼 필요가 있는 것이다. 따라서 하자 유형별로 특징을 파악하고, 직접 박스를 지정해 데이터를 재구성하였다. 이 과정에서는 http://roboflow.com 사이트를 이용하였다. 해당 사이트를 통해 다시 데이터를 train/valid dataset으로 나누고 클래스별로 직접 박스를 지정하여 클래스별 특징을 지정해주었다.
이렇게 다시금 데이터셋을 만든 후 YOLOv8 모델을 통해 object detection 및 classification을 진행했다. 해당 모델에 detect와 classify 두 가지 모델이 있어 모두 학습을 진행했다. imgsz는 800으로 지정하였으며 200 에포크로 학습을 진행했다. 그 결과 weighted f1 score는 0.5318018066, 0.5213931102까지 올랐다.
confusion matrix를 확인해보면 어느정도 학습은 잘 된 것 같은데, 실제 792개의 테스트 데이터에 대해서 예측을 수행했을 때 약 200개의 데이터는 탐지를 하지 못했다. 이는 데이터가 부족했다고 판단했고, 앞서 Stable Diffusion Model을 통해서 증강시켰던 데이터를 활용했다. 하지만 증강 데이터에 대해서도 일일이 박스를 지정해주는 작업이 필요했기 때문에 현실적으로 모든 데이터를 활용하진 못했고, 100개가 되지 않는 클래스에 해당하는 데이터에 대해서만 약 150개의 데이터로 증강시켰다.
그러나 증강 데이터를 활용한 결과는 차이가 거의 없었다. 0.5340605851, 0.5416652623 정도의 점수를 기록했다. 그러나 아래의 Confusion Matrix를 보면 소수 데이터가 늘어나 실제 많은 데이터가 포함되어 있던 훼손 같은 레이블에 대한 탐지는 전보다 못하는 것처럼 보인다. 그러나 점수는 비슷하게 나온 것은 imbalanced data에 대한 분류 모델을 구성할 때 f1 score를 많이 사용하기 때문에 증강 데이터를 활용한 모델은 소수 데이터에 대해 전보다 잘 맞추기 때문이라는 생각이 들었다.
대회는 이렇게 끝이 났다. 전체적인 프로세스는 다음과 같다.
- CNN 모델을 활용한 분류에서 전혀 이미지에 대한 특징을 파악하지 못하고, 분류를 제대로 수행하지 못함
- Stable Diffusion Model을 통한 이미지 증강을 진행한 후 CNN 모델 학습을 진행했지만 성능이 더욱 안좋아짐
- Object Detection 문제로 전환한 후 직접 박스를 지정해 데이터셋을 재구성하고, YOLOv8 모델로 학습하여 성능이 많이 향상
- 앞서 증강한 데이터를 통해 다시 학습을 진행했지만 성능에 크게 변화가 없음
코멘트
순위는 Public은 256/1,028 Private은 207/1,025등이었다. 아무래도 CNN 모델을 통한 분류 과정 이후에는 처음 접해보는 분야였기 때문에 프로젝트 과정에서 허술한 부분이 많다. 또한 지금 생각해보면 아쉬운 부분도 참 많다. 그러나 그동안 공부해보지 못했던 Object Detection과 Diffusion Model 등을 직접 데이터셋에 적용시켜보고, 이런 저런 수정 과정을 통해 성능도 향상시켜보는 과정이 의미가 있었던 프로젝트라고 생각한다.
아쉬웠던 부분은 다음과 같다.
- Diffusion Model을 통한 증강 과정에서 클래스별로 다른 방식으로 증강을 하지 못함
- YOLOv8 모델의 성능 향상을 위한 방법들을 더 공부해보고 적용시켜보지 못함
- YOLOv8 모델이 탐지하지 못한 약 200여 개의 데이터에 대해 직접 확인해보고 모델을 수정해보지 못함
- Stable Diffusion Model, YOLOv8 등 사용해보지 못했던 모델들에 대해 적용하면서 output을 얻어낸 것에서 그치지 않고 추가적으로 모델에 대한 논문을 읽어보는 등 공부를 더해서 어느 정도 이해도를 높인 상태로 대회를 진행하지 못함
- 박스를 지정하는과정에서 일관적이지 못한 부분이 있는 것 같음