
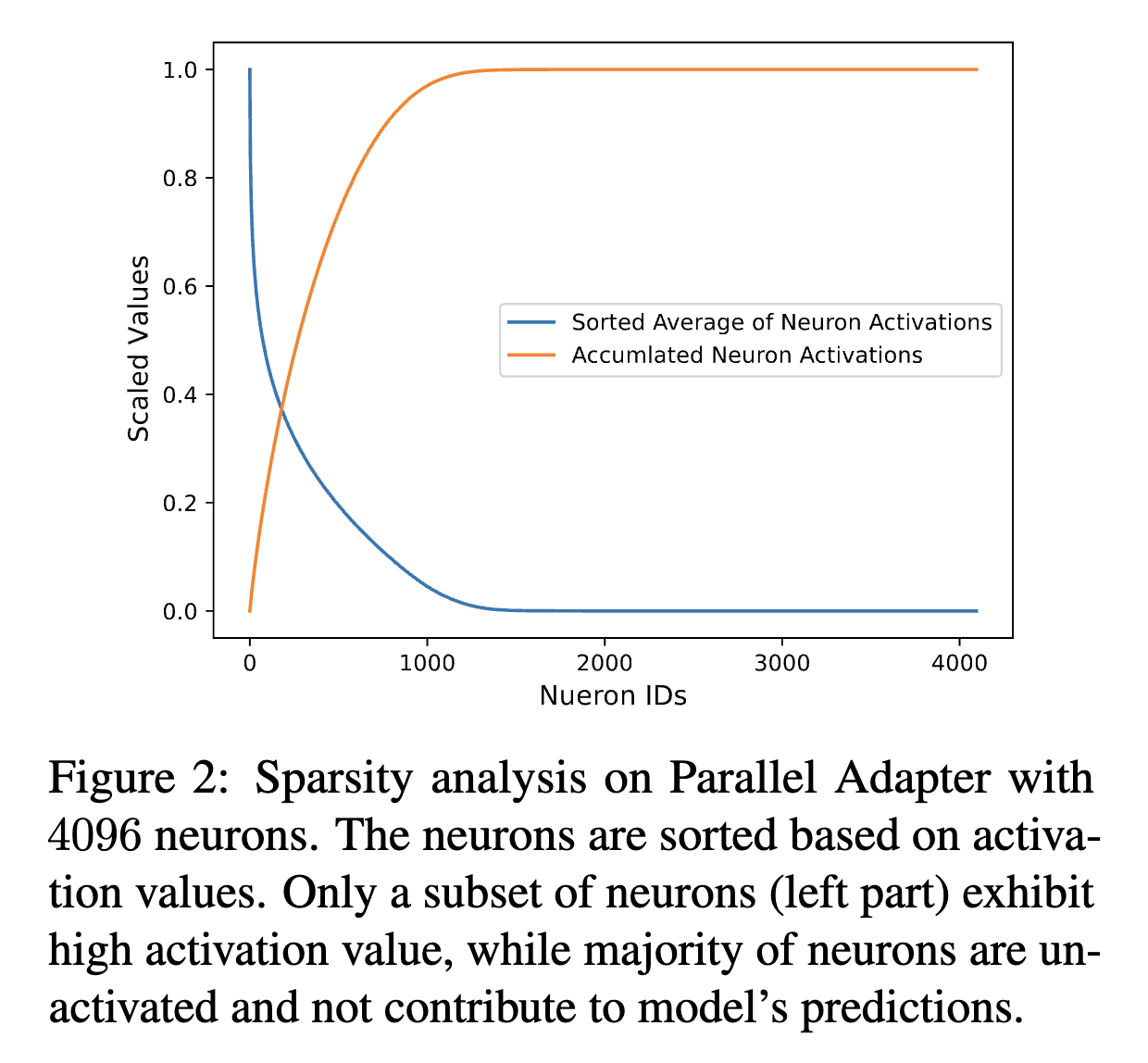
ACL 2024에 accept된 MEFT: Memory-Efficient Fine-Tuning through Sparse Adapter라는 논문에서 4,096의 bottleneck size를 가진 `Parallel Adapter`를 `Natural Question` 데이터셋에 대해 학습한 후 4,000 토큰으로 구성된 test set에 대한 adapter의 FFNs layer의 뉴런의 activation value를 추출한다. activation value를 기준으로 neuron들을 정렬하고, 시각화를 위해 [0, 1]의 값으로 정규화를 해주면 다음과 같은 그래프가 구성된다. 해당 그래프를 통해 adapter의 activation이 매우 `sparse`하며, 모델 예측에 일부 뉴런만이 기여해 대부분의 뉴런들은 비활성화 된다고 언급한다.
hook
위의 경우처럼 순전파 과정에서 각 layer의 activation value를 확인하는 경우에 파이토치의 `hook` 기능을 사용할 수 있다. hook은 패키지화된 코드에서 중간에 원하는 코드를 삽입할 수 있게끔 해주는 역할을 한다. 아래와 같이 `nn.Module`을 상속하는 모델을 만들면 자동으로 `hooks`가 정의된다. 이는 `forward()`나 `backward()` 시에 사용자가 직접 정의한 함수를 실행시킬 수 있도록 nn.Module을 만들 때 정의해 둔 것이다. 이러한 hook을 통해 매 layer마다 print문을 확인하지 않아도 각 layer의 activation/gradient 값을 확인하거나, 순전파 이후에 모델의 가중치를 변경하거나, 파라미터 업데이트를 실시간으로 확인하는 등의 기능을 수행할 수 있다.
from torch import nn
class Model(nn.Module):
def __init__(self):
super().__init__()
def module_hook(grad):
pass
model = Model()
model.__dict__
tensor_hook
import torch
def tensor_hook(grad):
grad = grad + 2
return grad
tensor = torch.rand(1, requires_grad=True)
print(tensor)
tensor.register_hook(tensor_hook)
print(tensor._backward_hooks)
tensor.backward()
print(tensor.grad)
print(tensor._backward_hooks)
forward_pre_hook
다음으로 Module에 적용하는 hook으로는 `forward_pre_hook`, `forward_hook`, `full_backward_hook`이 있다. 전체적인 실행 순서는 forward_pre_hook -> forward -> forward_hook -> backward -> full_backward_hook의 순서대로 진행된다. 먼저 forward_pre_hook의 경우 `register_forward_pre_hook()`을 통해 정의하며, forward 실행 전에 실행되는 hook에 해당한다. `pre_hook(module, input)` 함수에서 input의 경우 forward 연산의 입력에 해당하는 x1과 x2가 튜플 형태로 구성된다. 이 hook을 통해서 모델의 input을 수정할 수 있다.
import torch
from torch import nn
class Add(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x1, x2):
output = torch.add(x1, x2)
return output
add = Add()
answer = []
def pre_hook(module, input):
answer.append(input[0])
answer.append(input[1])
x1 = torch.rand(1)
x2 = torch.rand(1)
print(x1, x2)
add.register_forward_pre_hook(pre_hook)
output = add(x1, x2)
print(output)
print(answer)
forward_hook
다음은 `forward_hook`으로 `register_forward_hook()`을 통해 정의 가능하며 forward 이후에 실행되는 hook이다. `hook(module, input, output)` 함수에서 input은 이전과 동일하게 forward의 입력 값에 해당하는 x1과 x2가 튜플 형태로 포함되며, output에 순전파의 결과 값을 가지게 된다. 모델 내에서는 우선 forward를 실행해서 결과값을 저장한 뒤, forward_hook의 반환값이 있으면 forward_hook의 반환값으로 결과를 수정하게 된다. 따라서 hook에서 input을 수정한다해도 forward에는 적용되지 않는다.
def hook(module, input, output):
return output + 5
add.register_forward_hook(hook)
x1 = torch.rand(1)
x2 = torch.rand(1)
print(x1, x2)
output = add(x1, x2)
print(output)
print(answer)
full_backward_hook
마지막으로 `full_backward_hook`의 경우 `register_full_backward_hook()`을 통해 정의 가능하며, input에 대한 gradient가 계산될 때마다 호출되는 hook에 해당한다. `module_hook(module, grad_input, grad_output)` 함수에서 grad_input의 경우 forward의 입력 값인 x1과 x2에 대한 gradient를 튜플 형태로 저장하며, grad_output은 순전파 output에 대한 gradient를 담고 있어 1로 구성되며 튜플 형태로 저장되어 있다. 여기서 grad_output과 input, output은 모두 수정할 수 없다. 즉, grad_input 값만을 새로운 gradient로 활용할 수 있는데, 이 경우 grad_input의 의미가 왜곡되기 때문에 디버깅 이외의 상황에서는 권장되지 않는다.
import torch
from torch import nn
from torch.nn.parameter import Parameter
class Model(nn.Module):
def __init__(self):
super().__init__()
self.W = Parameter(torch.Tensor([5]))
def forward(self, x1, x2):
output = x1 * x2
output = output * self.W
return output
model = Model()
answer = []
def module_hook(module, grad_input, grad_output):
answer.extend(grad_input)
answer.append(grad_output[0])
pass
model.register_full_backward_hook(module_hook)
x1 = torch.rand(1, requires_grad=True)
x2 = torch.rand(1, requires_grad=True)
print(x1, x2)
output = model(x1, x2)
print(output)
output.retain_grad()
output.backward()
print(answer)
backward hook을 통해 grad_input 값을 수정해 새로운 gradient로 활용하는 예시로는, grad_input의 합이 1로 되게끔 수정하는 경우가 있다.
import torch
from torch import nn
from torch.nn.parameter import Parameter
class Model(nn.Module):
def __init__(self):
super().__init__()
self.W = Parameter(torch.Tensor([5]))
def forward(self, x1, x2):
output = x1 * x2
output = output * self.W
return output
model = Model()
def module_hook(module, grad_input, grad_output):
print(grad_input)
total = 0
for grad in grad_input:
total+=grad
grad_input = torch.divide(grad_input[0],total), torch.divide(grad_input[1],total)
print(grad_input)
return grad_input
model.register_full_backward_hook(module_hook)
x1 = torch.rand(1, requires_grad=True)
x2 = torch.rand(1, requires_grad=True)
output = model(x1, x2)
full_backward_hook에서는 forward의 인자에 해당하는 input(x1과 x2의 튜플)의 gradient과 output의 gradient만을 알 수 있기 때문에 모델 내부 파라미터의 gradient 값은 알 수 없다. 이 경우 위에서 확인한 tensor 단위의 hook을 사용해 모델 내부 파라미터의 gradient를 확인할 수 있다.
class Model(nn.Module):
def __init__(self):
super().__init__()
self.W = Parameter(torch.Tensor([5]))
def forward(self, x1, x2):
output = x1 * x2
output = output * self.W
return output
model = Model()
answer = []
def tensor_hook(grad):
answer.append(grad)
pass
model.W.register_hook(tensor_hook)
x1 = torch.rand(1, requires_grad=True)
x2 = torch.rand(1, requires_grad=True)
print(x1, x2)
output = model(x1, x2)
output.backward()
print(output)
print(answer)
hook의 사용 예시
hook이 사용되는 경우는 다음과 같다.
- 디버깅 - layer마다의 shape, output 등을 출력하는 hook을 넣어주는 등의 방식
- feature extraction
from typing import Dict, Iterable, Callable
class FeatureExtractor(nn.Module):
def __init__(self, model: nn.Module, layers: Iterable[str]):
super().__init__()
self.model = model
self.layers = layers
self._features = {layer: torch.empty(0) for layer in layers}
for layer_id in layers:
layer = dict([*self.model.named_modules()])[layer_id]
layer.register_forward_hook(self.save_outputs_hook(layer_id))
def save_outputs_hook(self, layer_id: str) -> Callable:
def fn(_, __, output):
self._features[layer_id] = output
return fn
def forward(self, x: Tensor) -> Dict[str, Tensor]:
_ = self.model(x)
return self._features- gradient clipping - `register_hook`
- visualizing activation - `forward_hook`
import torch
import torch.nn as nn
class myNet(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(3,10,2, stride = 2)
self.relu = nn.ReLU()
self.flatten = lambda x: x.view(-1)
self.fc1 = nn.Linear(160,5)
self.seq = nn.Sequential(nn.Linear(5,3), nn.Linear(3,2))
def forward(self, x):
x = self.relu(self.conv(x))
x = self.fc1(self.flatten(x))
x = self.seq(x)
net = myNet()
visualisation = {}
def hook_fn(m, i, o):
visualisation[m] = o
def get_all_layers(net):
for name, layer in net._modules.items():
#If it is a sequential, don't register a hook on it
# but recursively register hook on all it's module children
if isinstance(layer, nn.Sequential):
get_all_layers(layer)
else:
# it's a non sequential. Register a hook
layer.register_forward_hook(hook_fn)
get_all_layers(net)
out = net(torch.randn(1,3,8,8))Reference
[1] https://arxiv.org/abs/2406.04984
[2] https://kjy042386.tistory.com/308
[3] https://ohsy0512.tistory.com/27
[4] https://daebaq27.tistory.com/65
[5] https://medium.com/the-dl/how-to-use-pytoch-hooks-5041d777f904
[6] https://blog.paperspace.com/pytorch-hooks-gradient-clipping=debugging/