
Pre-trained word representation
- Pre-trained word respresentation은 많은 neural language understanding model에서 중요한 요소
- 높은 품질의 representation은 2가지를 모델링할 수 있어야 함
- 단어의 복잡한 특성(ex> syntax, semantic)
- 단어들이 linguistic context 상에서 서로 다르게 사용될 때, 사용법에 맞는 representation을 표현
- "눈"이라는 단어는 "eye", "snow"로 사용이 가능한데 이에 맞게 embedding이 달라야 함
ELMo(Embeddings from Language Models)의 특징
- 기존에 단어에 집중했던 것에서 벗어나 전체 input sentence를 고려하여 생성된 representation을 각 토큰에 할당
- 이는 input sentence 내 해당 단어가 어떻게 사용되었는지를 고려하기 위함
- 거대 text corpus를 활용한 두 가지 language model(forward, backward)을 통해 훈련된 `bidirectional LSTM`에서 생성된 vector 사용
- 모든 biLM의 internal layer에 해당하는 hidden vector들을 결합하기 때문에 ELMo representation은 심층적(deep)
- 각 end task에 대해 각 input word 위에 쌓인 hidden vector의 linear combination이 학습되어 LSTM layer의 top layer만 사용하는 것보다 현저한 성능 향상이 가능
- task에 따라서 어떻게 여러 층의 정보를 결합하느냐(가중치를 어떻게 설정하느냐)를 결정하여 여러 downstream task에서 높은 성능을 보이는 representation을 생성
- High-level의 hidden state는 단어 뜻의 context-dependent 한 부분을 보존
- Low-level의 경우 syntax에 대한 부분
Graphical illustration
- ELMo는 문장 전체를 살펴본 뒤 각 단어에 대한 embedding 할당

- `Language Model` : 지금까지 주어진 단어의 sequence들을 통해서 다음 단어를 예측하여 language understanding
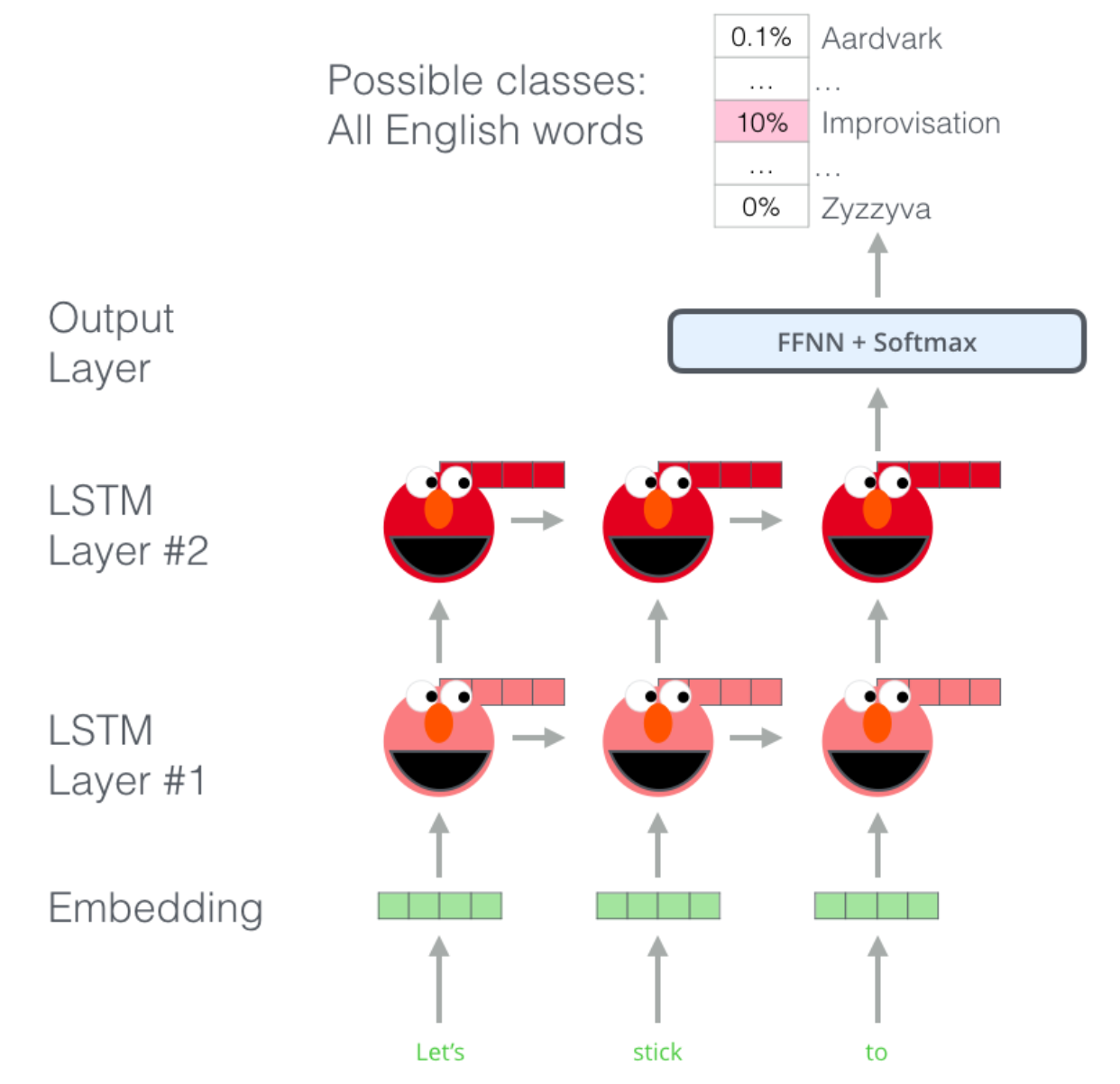
ELMo를 활용한 embedding 과정
- ELMo는 contextualized embedding을 initial embedding 및 hidden states를 concatenate 하고 이에 대한 weighted sum을 수행하며 생성
- "Let's stick to"라는 sentence에서 "stick"이라는 token을 embedding 하는 과정
- `bi-directional LSTM`을 통해 next word뿐만 아니라 previous word에 대해서도 모두 학습
- 같은 level에 있는 hidden state를 concatenate
- downstream task에 따라 적절합 가중치 s0, s1, s2 를 학습하여 앞서 concatenate 한 vector에 곱함(중요)
- 가중치가 곱해진 weighted vector들을 sum


ELMo for downstream task

- ELMo는 대응되는 hidden layer들의 선형 결합으로 현재의 word t_k 에 대한 representation 생성
- biLMs에서 생성되는 hidden vector들은 downstream task에 상관없이 corpus가 주어지면 생성
- r^task 는 task에 대한 scale factor로 전체 가중합이 된 pre-trained vector를 얼마만큼 증폭 혹은 축소시킬지 결정
Mathematical demonstration : Bidirectional language models
- N개의 token으로 구성된 sequence (t_1, t_2, ... , t_N) 이 주어졌을 때 `forward language model`은 t_k 이전의 토큰들을 통해 probability를 계산

- `context-independent` representation x_k 는 token embedding 혹은 CNN 등 다양한 것을 통해 생성 가능하며, 이는 forward LSTM 모델의 모든 L개의 layer를 모두 통과
- 각 k에서는 각 LSTM layer에서 `context-dependent` representation →h_k,j (k번째 token이 j번째 LSTM layer에서 가지고 있는 hidden state)를 생성
- 최상단 LSTM layer의 output →h_k,L 은 softmax layer를 통해 다음 토큰인 t_k+1 을 예측하는 데 사용
- `backward language model`은 future context를 통해 previous token을 예측

- 각 backward LSTM layer는 representation ←h_k,j 생성
- forward 및 backward LM의 log likelihood를 모두 최대화

ELMo
- biLM의 hidden layer representation의 task-specific combination
- 각각의 토큰 t_k 에서 biLM의 L번째 layer는 2L+1개의 representation을 계산

- R_k 의 모든 layer의 vetor들을 downstream task에 맞는 가중치로 가중 합을 수행해 하나의 single vector로 계산

Performances

- 다양한 downstream task에 대해서 모두 ELMo를 사용했을 때 일반적인 `GloVe`, `Word Embedding` 등의 1차원 embedding을 수행하는 방식보다 성능이 향상
Analysis
Alternate layer weighting scheme

- downstream task에 맞게 weight를 조정하는 것이 weight를 1/(L+1) 로 동일하게 유지하는 것과, top-layer 혹은 bottom-layer만을 사용하는 것보다 성능이 우수
Where to include ELMo?

- Input sequence를 embedding 하는 과정에 ELMo를 concatenate 하는 것과 더불어 hidden layers를 거쳐 최종 output을 생성하기 이전 vector에 다시 한 번 ELMo를 concatenate하는 것이 성능이 가장 좋음
- Input sequence에서만 ELMo를 concatenate하는 것과, Output 이전 vector에 concatenate하는 것, ELMo를 아예 사용하지 않는 것보다 더 좋은 성능을 보임
What information is captured by the biLM's representation
- ELMo는 GloVe와 비교했을 때 context에 따라서 각 단어의 의미를 구분

Reference
[1] https://arxiv.org/abs/1802.05365